
NAND가 TLC에 DRAM 있는 SATA SSD는 좋아하세요? [1300 1TB]
2022년 초, 저는 Synology사의 DS620slim이라는 제품을 NAS로 사용하고 있었습니다. 870 EVO 1TB를 사용하고 있었지만, SSD의 추가를 위해 1TB의 SATA SSD를 찾았습니다. 그때의 SATA SSD는 Samsung 870 EVO, WD Blue, Micron Crucial MX500이 대중적이었던 것으로 기억합니다. 지금 멀쩡하게 남은 것은 870 EVO 뿐이지만요.
아무튼, 그렇게 유명하진 않았지만, Crucial 브랜드가 아니라 Micron 브랜드로 1300이라는 SATA SSD가 유통되고 있었습니다. 타이밍 좋게 저는 PLP라는 개념을 막 알게되었고, 1300이 PLP를 지원한다길래 바로 구입했죠. 지금은 eSSD의 PLP와 다른 것을 알고있지만, 당시에는 "Data-at-rest"라는 문구를 못 보았거나, 제대로 이해하지 못했던 것 같습니다.
그렇게 시간이 흐르고, DS620slim을 처분하고, 다른 NAS에서도 이리저리 구르다가 지금은 쉬고있는 1300씨. 더 쉬어서 몸이 굳기 전에 테스트를 진행했습니다. 아마 1300 씨에게 있어서는 살면서 가장 혹독한 시간이 아니었나 싶네요.
목차
Appearance


은색의 금속제 케이스입니다. 소비자용 브랜드인 Crucial로 판매되었던 MX500은 파란 스티커가 붙어있었지만, 이 친구는 Crucial 제품이 아닌지라 조금 투박합니다.
개인적으로는 이쪽이 더 취향이에요.


기판을 잡아주는 스펀지가 있고, 컨트롤러 쪽에는 방열을 도와주기 위한 작업이 되어있습니다.
Internal Components
문외한의 입장에서 일부 IC만 찾아보았으며, 제조시기 등에 따라 변경될 가능성이 있습니다.
맞지 않을 확률이 상당히 높으니 재미로만 읽어주세요.


| Micron 1300 (1TB, 2.5") | 2019. 08. 02. |
| Marvell 88SS1074 | Maxim Integrated MAX77752 |
| Micron MT52L512M16D1PF-093 WT:B | Texas Instruments TLV62585 |
| Micron MT29F2T08EMHBFJ4-R:B *4 | Macronix MX25L3233F |
컨트롤러는 Marvell 88SS1074를 사용했습니다. 엔터프라이즈에도 사용되는 무난한 4채널 SATA 컨트롤러이며, 2개의 ARM9 코어로 구성됩니다.
DRAM은 Micron MT52L512M16D1PF-093 WT:B이 실장되었습니다. LPDDR3 1GB입니다.
NAND는 Micron MT29F2T08EMHBFJ4-R:B이며, 전후면에 각각 두 개씩 실장되었습니다. B27A 또는 96L TLC라고도 불리며, 512Gb Die가 4개씩 패키징되어 2048Gb = 256GB를 구현합니다. 이러한 칩이 총 4개로 1TB를 이룹니다. 해당 NAND는 FortisFlash 등급으로, 일반적인 cTLC임을 알 수 있습니다.
참고로, 이 세대 이후에는 IMFT가 아닌 Micron의 NAND라고 할 수 있으며, FG가 아닌 CTF가 적용됩니다.
Datasheet
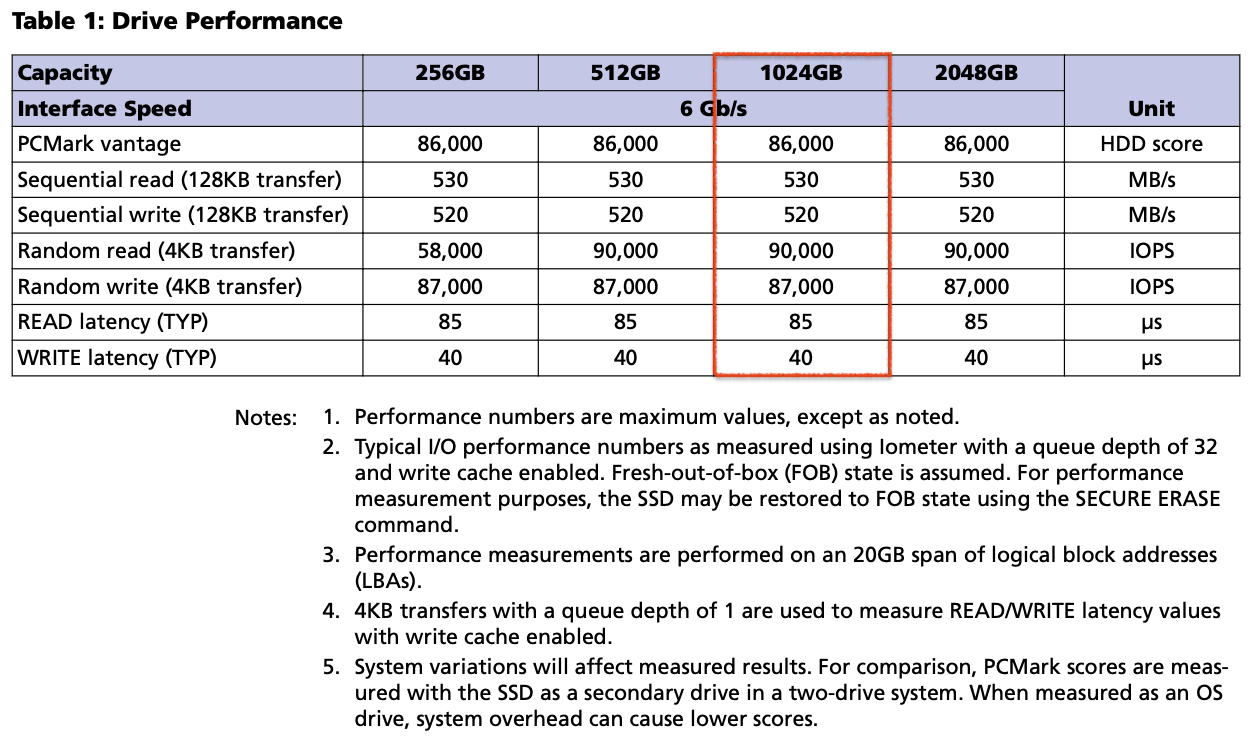
성능 수치에 관한 표입니다. 역시 FOB의 상태를 가정하고 있으며, 특이한 점은 PCMark와 관련된 수치가 기입되어 있습니다. 아쉽지만 이 부분에 대한 검증은 진행하지 못할 것 같네요.
많은 사람들이 그냥 넘길 항목을 보시면 재밌는 부분이 있습니다. 3번 항목을 보면 "20GB span of LBAs"라고 지정하였는데, 제가 참조하는 Intel의 8GB span보다 살짝 큽니다. 사실, 저도 리뷰 작성하면서 방금 인지했습니다.
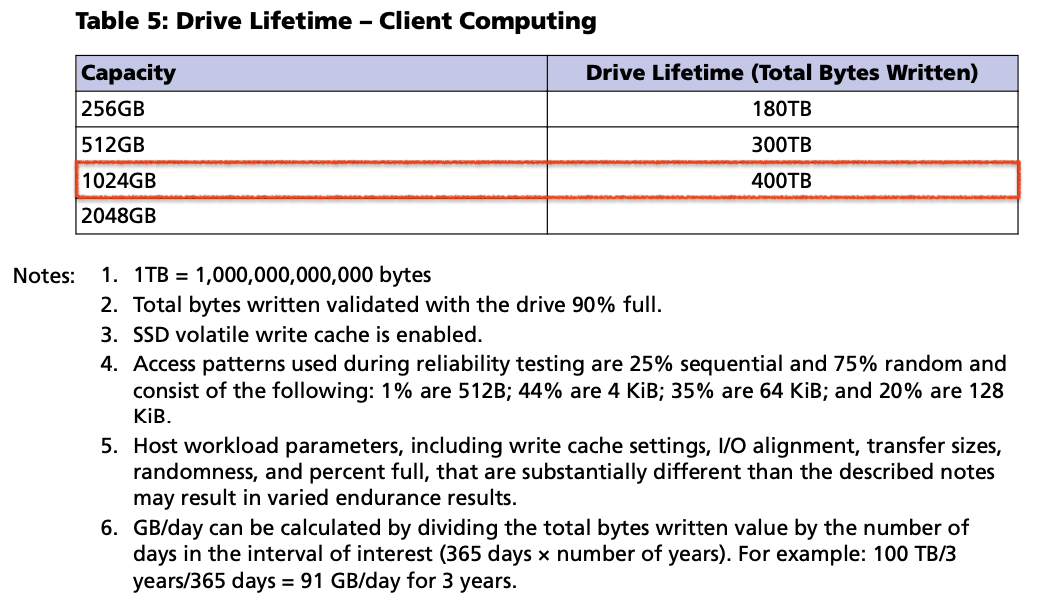
내구성에 관한 표입니다. 적절하게 빨간 사각형을 그려 2048GB SKU의 TBW가 없는 것처럼 보이지만, 실제로는 1024GB SKU와 그 값을 공유합니다.
일반적으로 1TB TLC SSD가 600TBW를 보증하는 것을 생각하면, 꽤 짧다고 볼 수도 있겠습니다. 하지만 그런 수치보다 아래에 기입해둔 항목이 흥미롭습니다. TBW는 드라이브가 9할 채워져있을 때 검증되었으며, 자세한 워크로드도 나와 있습니다.
Micron은 이러한 워크로드를 Client Computing이라고 정의하는 모양입니다.
SW Report
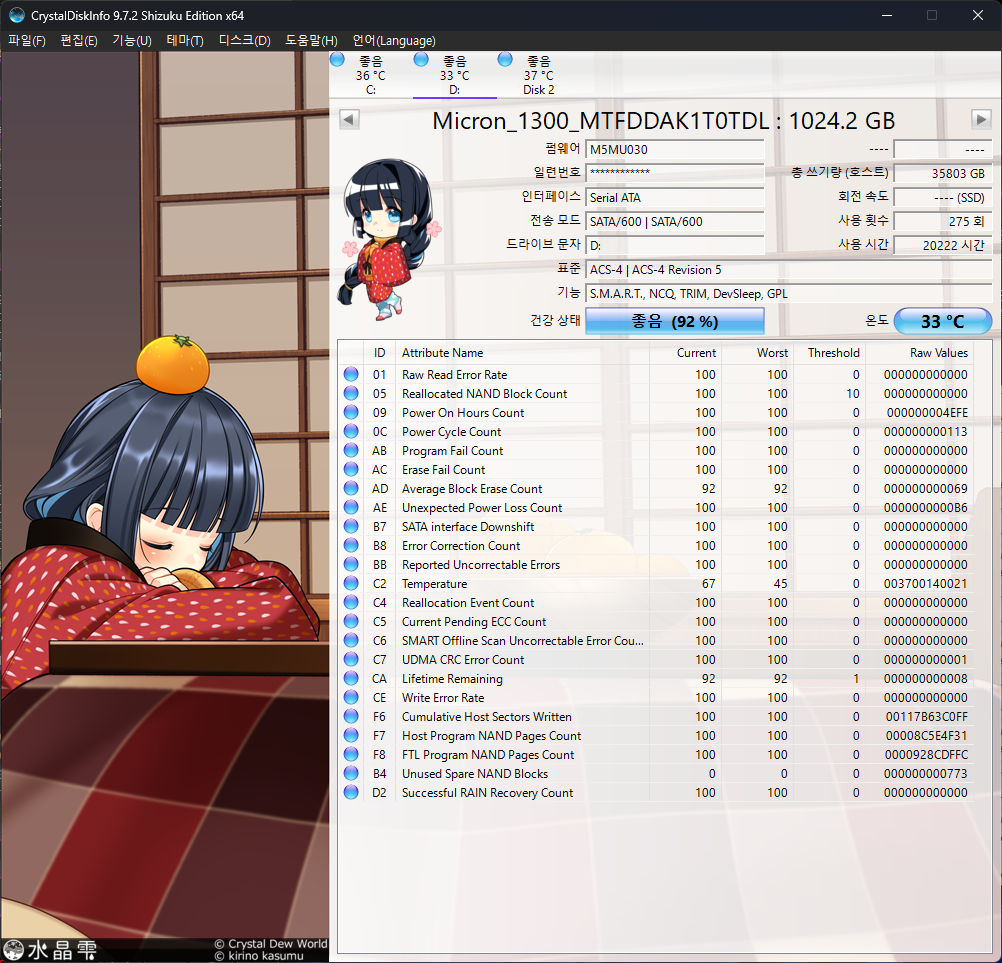
제가 한참 사용했던 드라이브라 사용량이 꽤 누적되어 있습니다.
smartmontools와 hdparm에 대한 값은 GitHub에 첨부하도록 하겠습니다.
DUT Summary
벤치마크를 진행할 SSD에 관한 요약입니다.
MTFDDAK1T0TDL-1AW1ZABYY [Micron 1300 1TB] | |||
| Link | SATA 6Gbps | NVMe Version | - |
| Firmware | M5MU030 | LBA Size | 512B |
| Controller | Marvell 88SS1074 | Warning Temp | X °C |
| Storage Media | Micron 96L TLC | Critical Temp | X °C |
| Power State | Maximum Power | Entry Latency | Exit Latency |
| PS- | - W | - μs | - μs |
SATA SSD는 뭔가 적을게 없어서 허전하네요.
Comparison Device
비교군은 아래와 같습니다.
| Name | Why? |
| P3 Plus 2TB [P9CR40D] | QLC DRAMless NVMe. TLC DRAM SATA와 비교해봅시다. |
| PM981a 256GB [EXH7201Q] | 혼자는 외로우니깐... |
스포일러를 약간 포함하자면, eSSD Benchmarking에서 P3 Plus의 데이터가 존재하지 않기에 PM981a을 가지고 왔습니다.
Test Platform
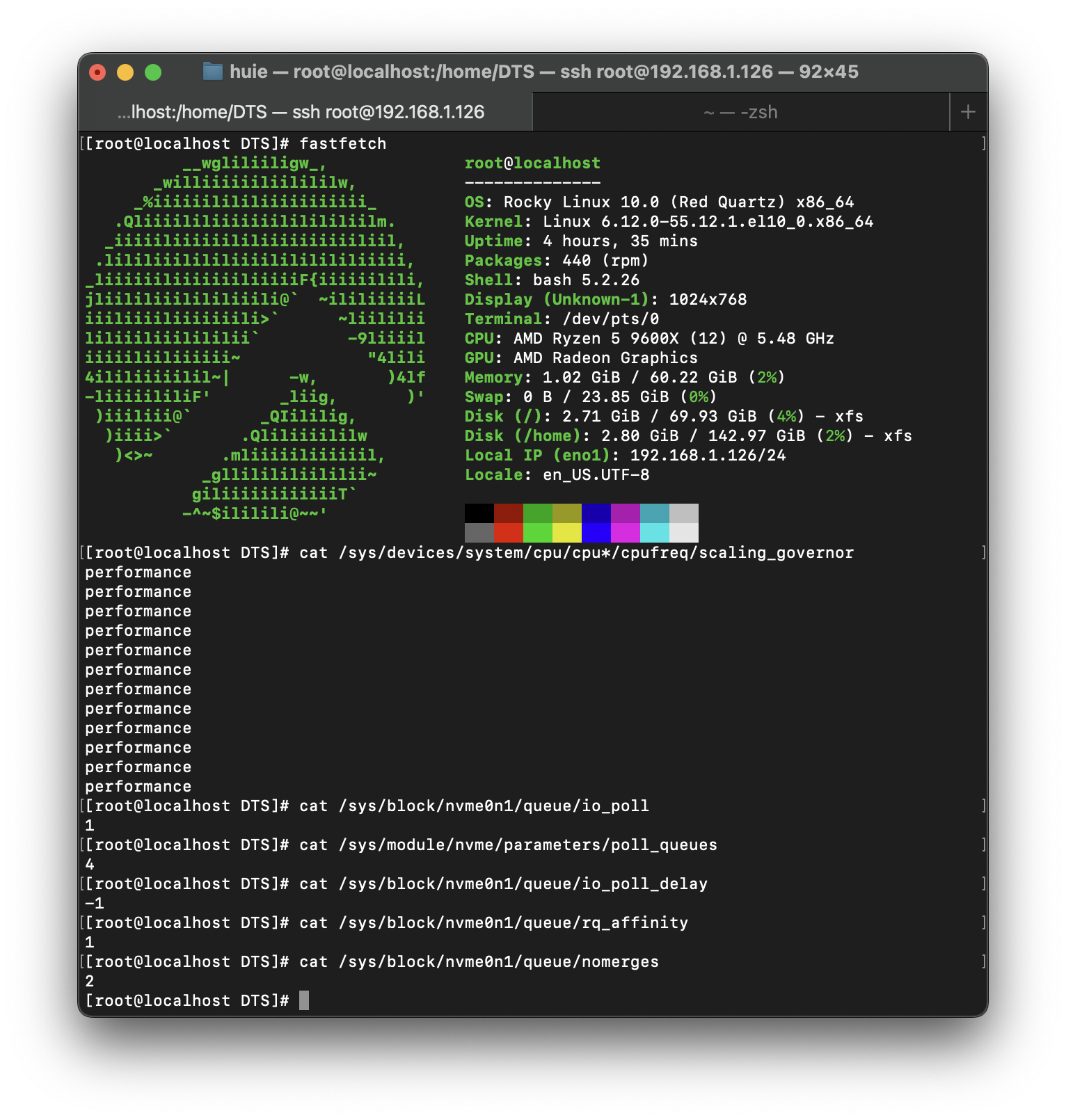
테스트 환경은 위와 같습니다. Windows 25H2(26200.6899)에 종속되는 도구들을 제외하고는 모두 FIO 3.41을 통해 Rocky Linux 10(6.12.0-55.12.1.el10_0)에서 실행되며, 가능하다면 io_uring과 Polling을 적극적으로 활용합니다.(SATA SSD에서는 Polling을 사용하지 않습니다.) 또한, 양쪽 다 기본 Inbox Driver를 사용합니다.
자세한 벤치마크 방법론에 대해서는 이전에 작성한 Refresh Benchmark를 참고해 주시길 바랍니다.
cSSD Benchmarking
start /wait Rundll32.exe advapi32.dll/ProcessIdleTasks Windows에서는 위의 명령어를 실행하고 15분 뒤를 IDLE 상태로 정의해 벤치마크를 진행합니다. 각 벤치마크 사이에는 5분의 휴식 시간이 부여되며, Purge는 Linux에서 hdparm --user-master @ --security-erase @ 명령어를 통해 수행했습니다.
CrystalDiskMark 9.0.1
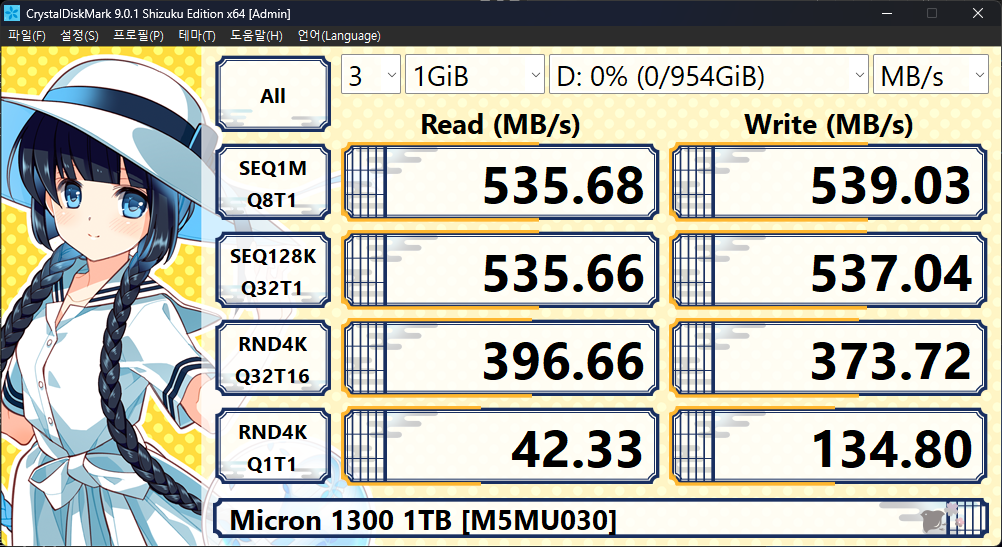
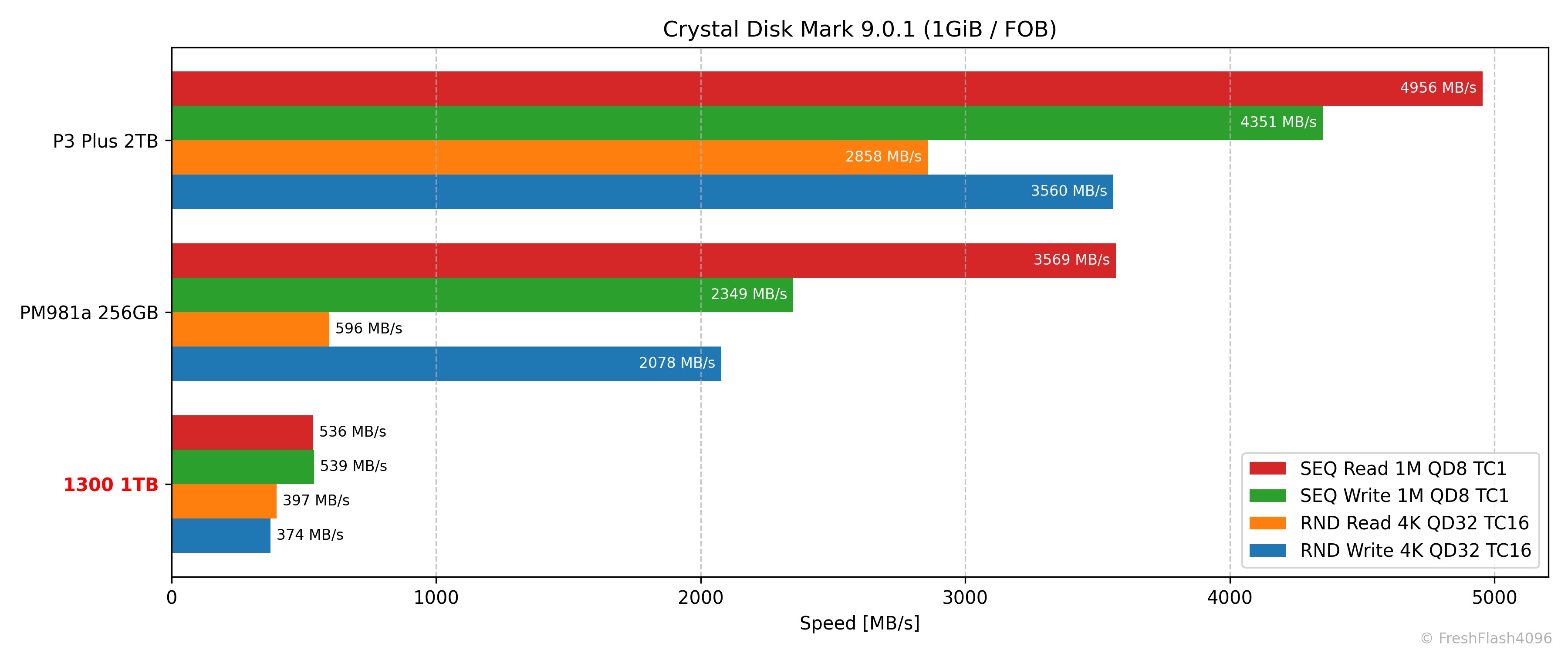
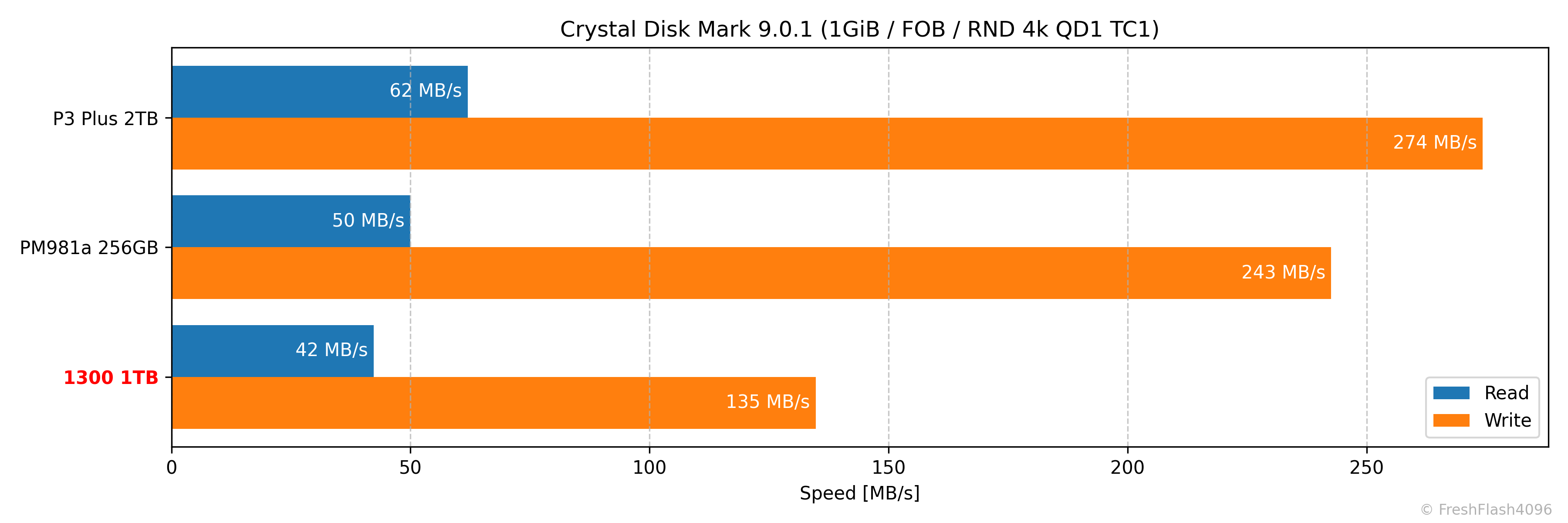
CDM에서 SATA SSD와 NVMe SSD를 비교하는건 잔인하지만, 스펙시트의 값은 충족합니다. 엄밀히는 다른 조건이지만요.
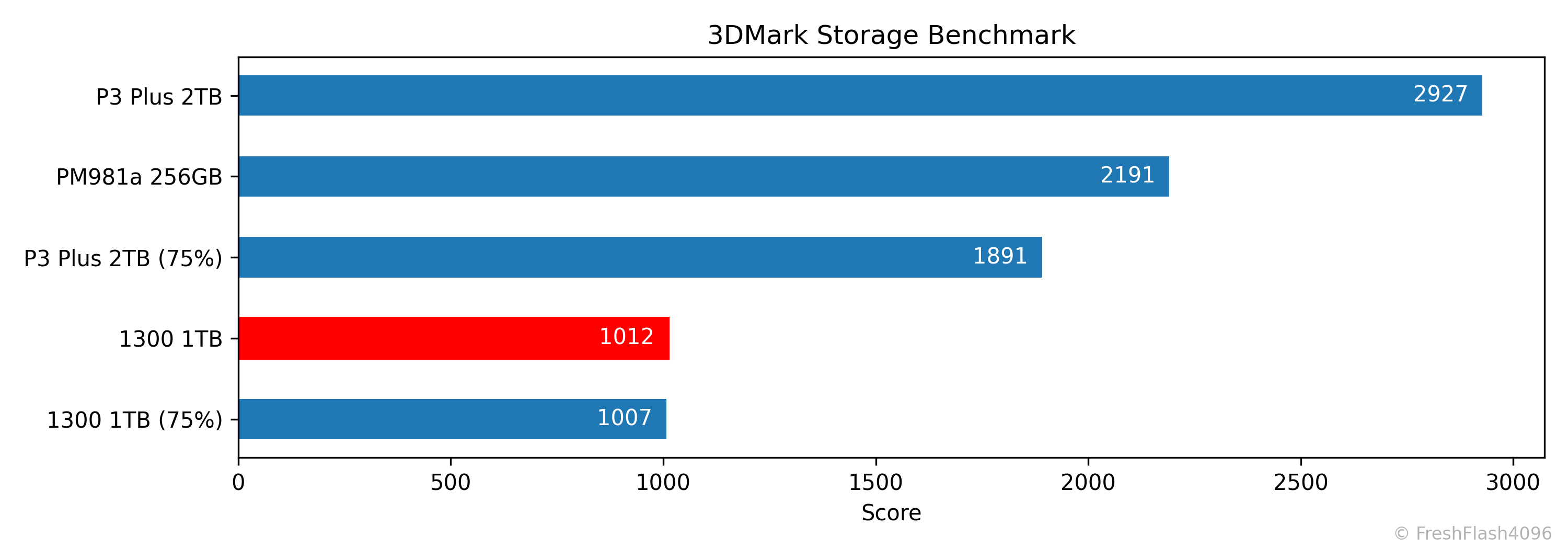
3DMark Storage Benchmark
SPECworkstation 4.0
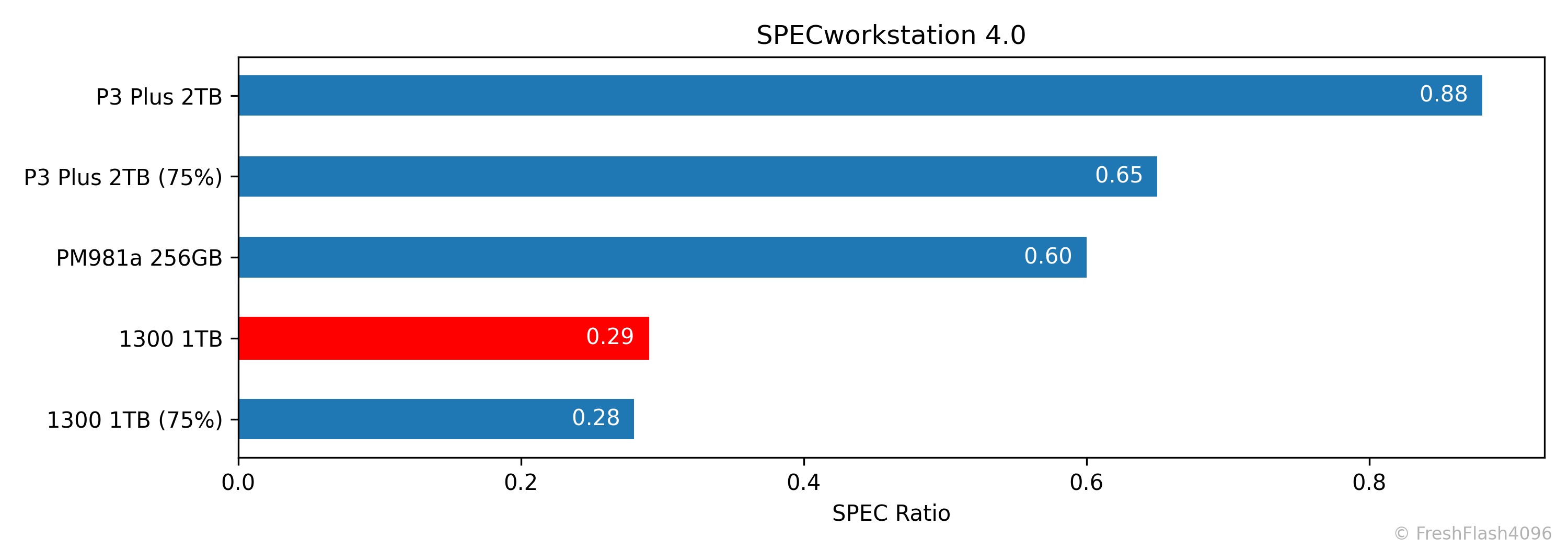
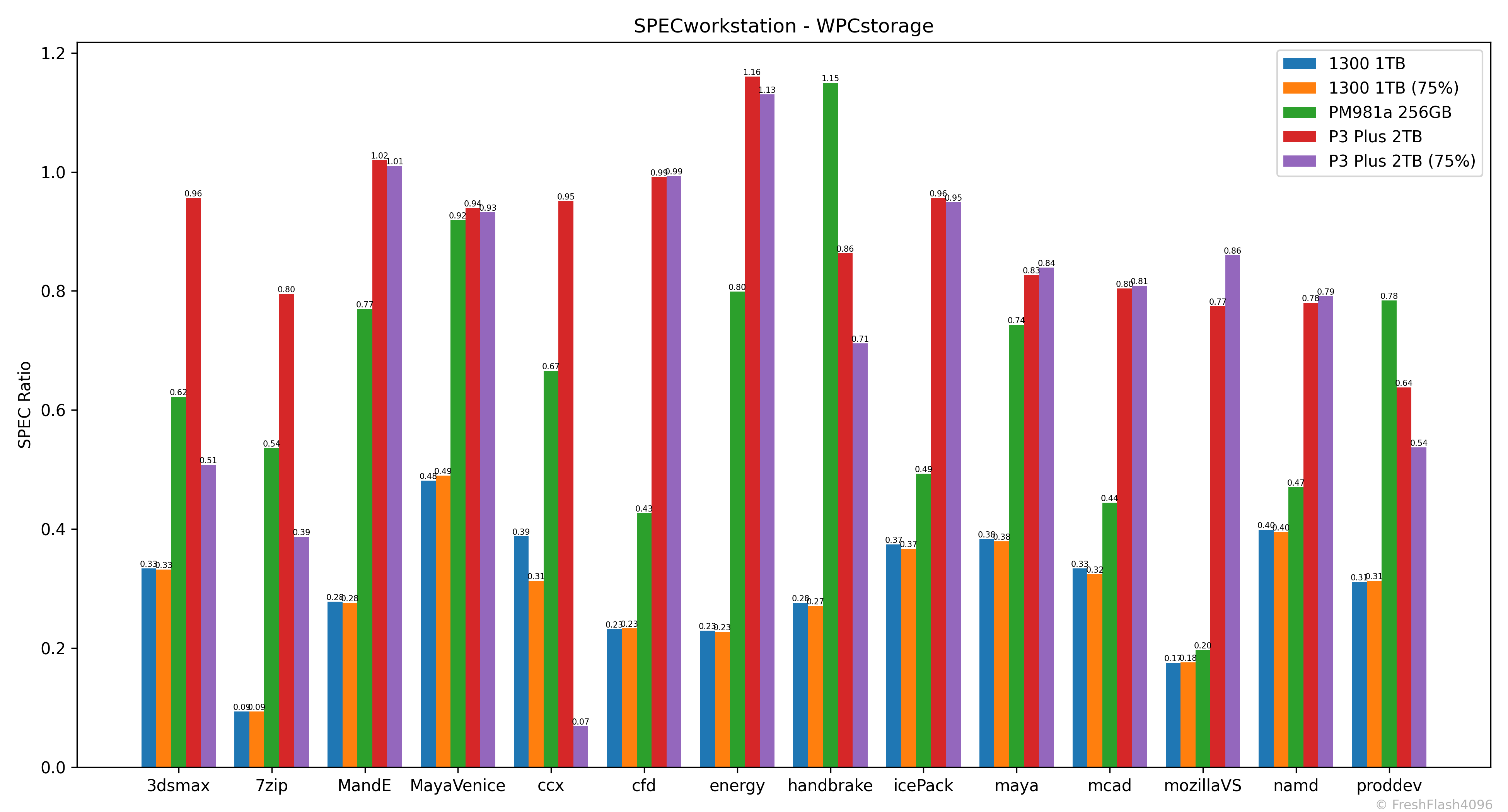
일반적으로 FOB상태라면 P3 Plus 2TB가 1300 1TB에 비해 더 우수한 성능을 보였지만, 유한요소해석을 다루는 ccx 워크로드는 그렇지 않았습니다. 75%가 채워진 P3 Plus 2TB의 성능이 심각하게 하락하기 때문이죠.
Fill Drive
나래온 더티테스트와 비슷한 벤치마크입니다. FOB상태로 시작하여, SEQ 128k QD256으로 드라이브 전체를 2회 채우며, 0.1s 단위로 값을 측정합니다. 1회차와 2회차 사이의 휴식은 충분히 부여됩니다.
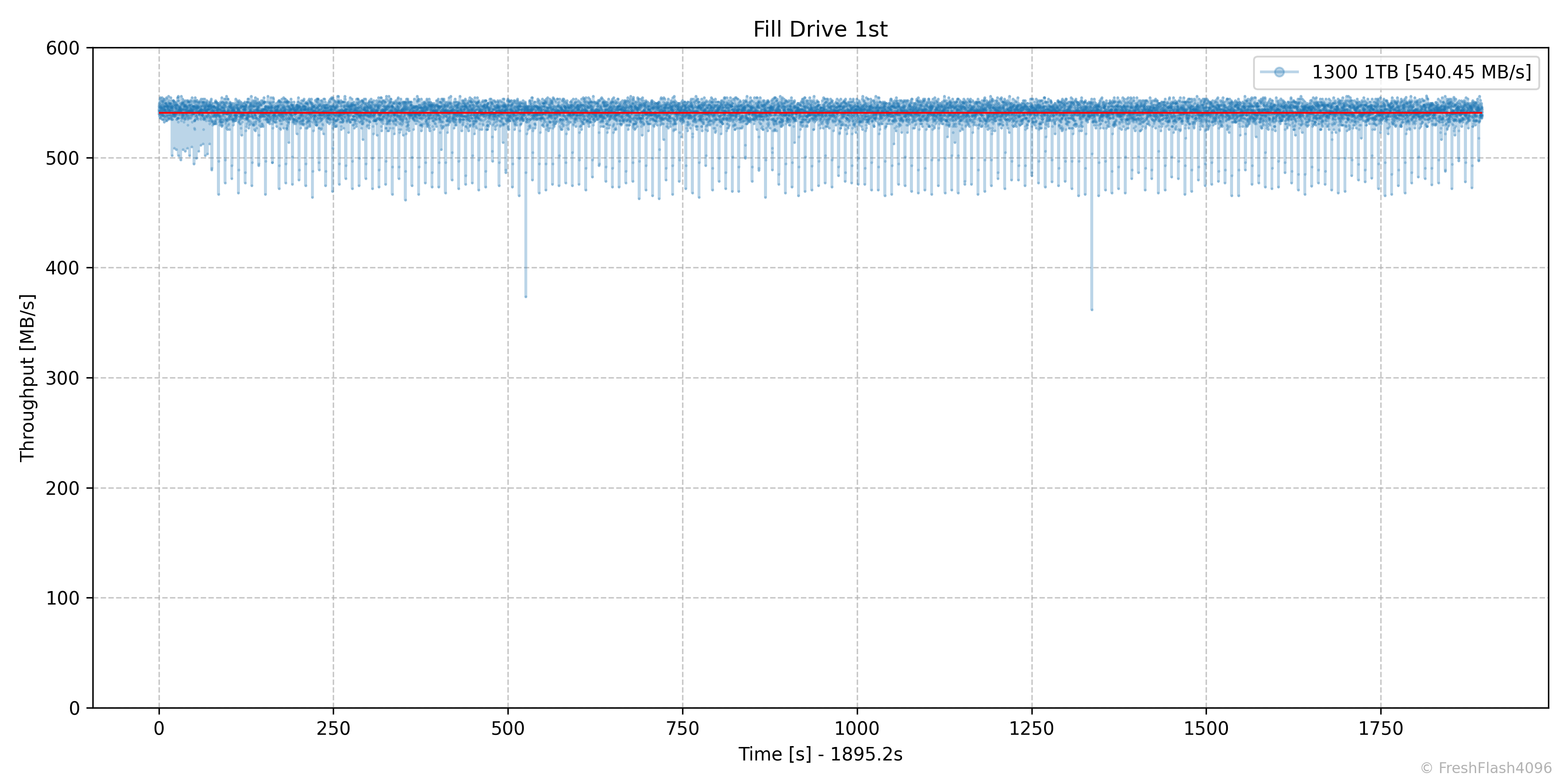
SATA 대역폭의 한계로 SLC캐시와 무관하게 지속되는 540MB/s의 속도를 보여줍니다. 하지만, Flush로 인한 패널티도 확인이 가능합니다.
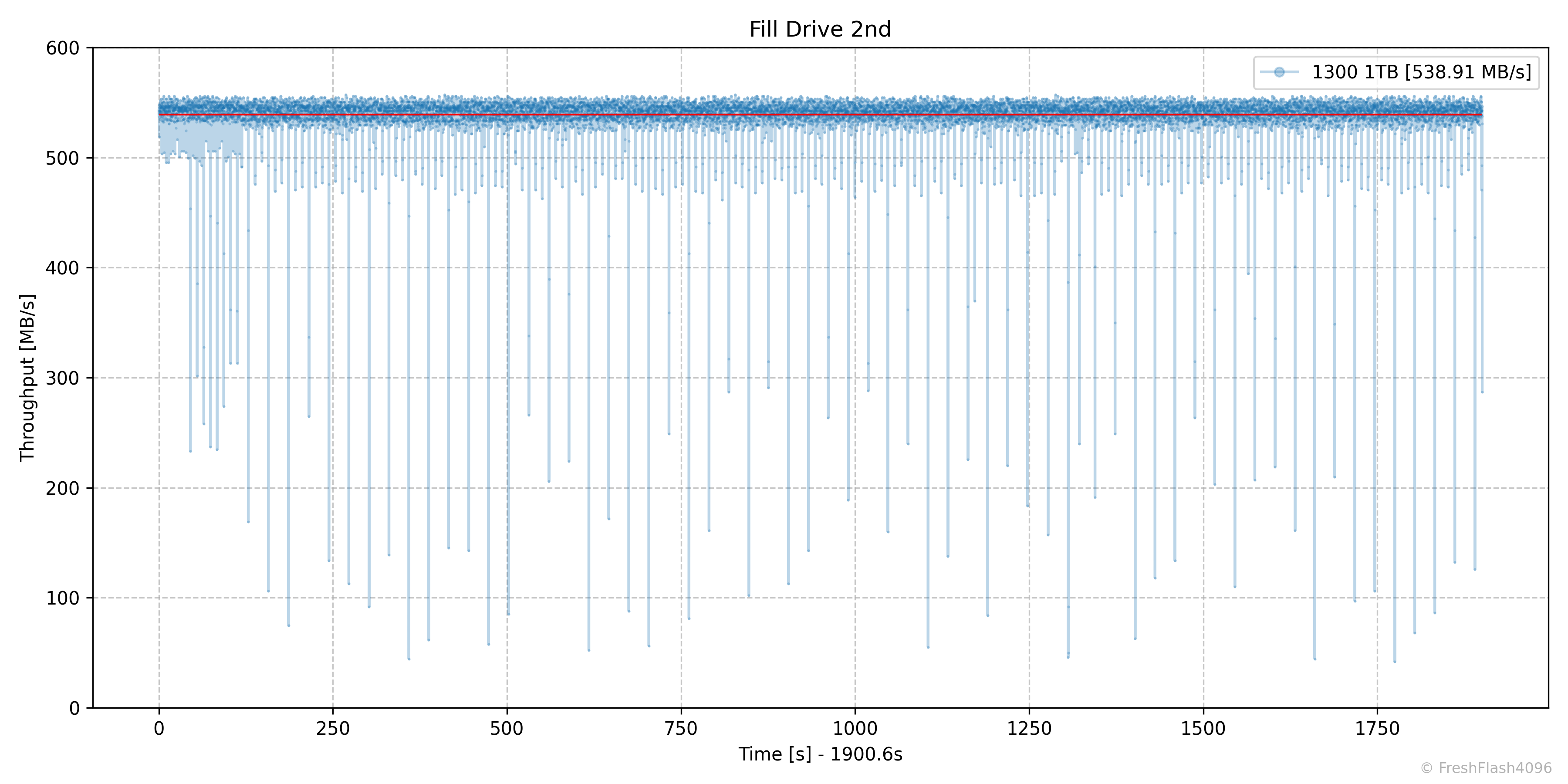
2차 Fill Drive는 겨우 5초의 시간이 늘었으나, 확실하게 1회차보다 덜 일관된 속도를 보여줍니다. 단순한 Garbage Collection이라도 확실하게 패널티가 된다는 뜻이죠.
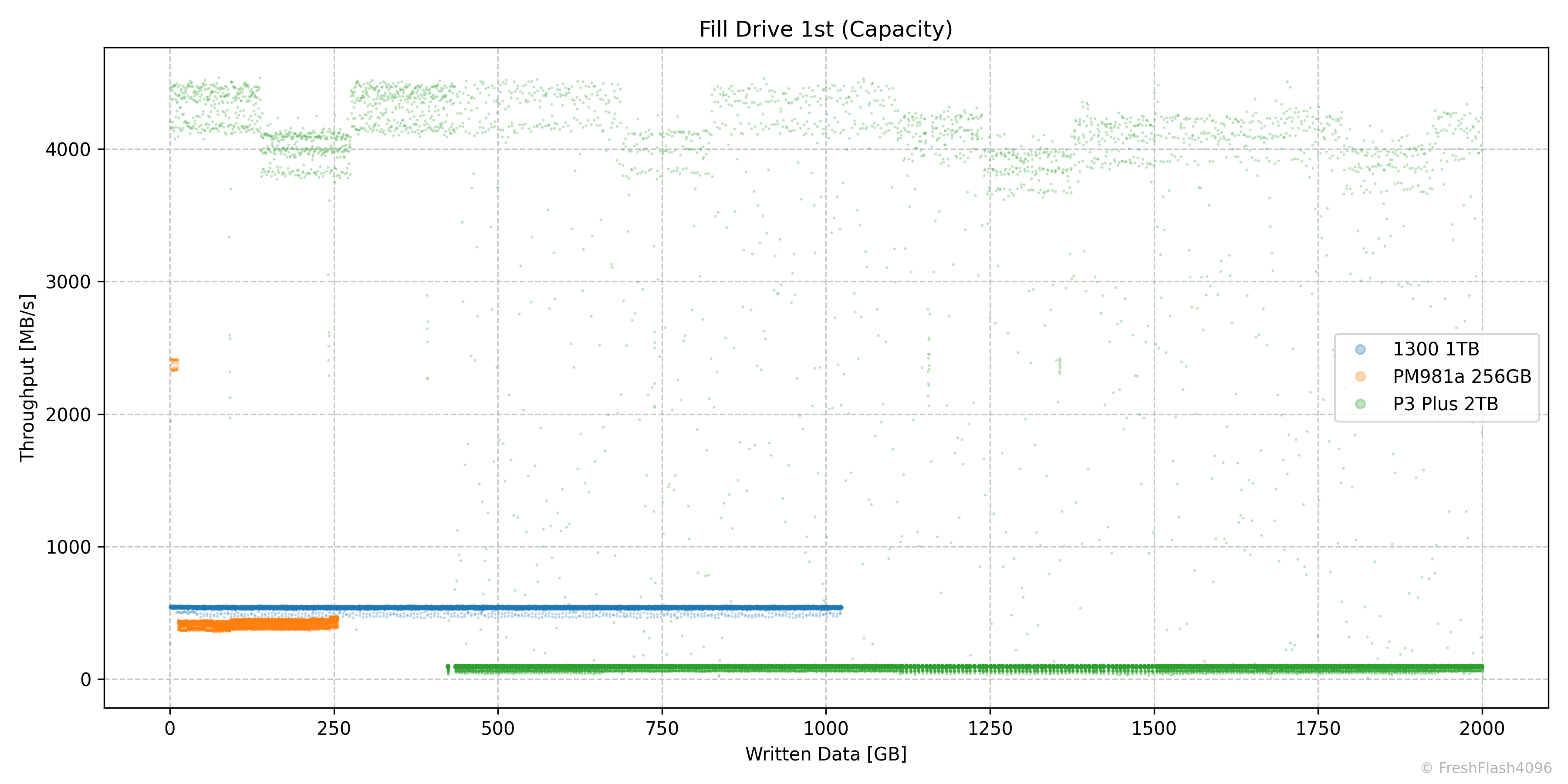
비교군의 1차 Fill Drive를 모아봤습니다. 단, 가로축이 쓰기량이란 것에 유의해주세요.
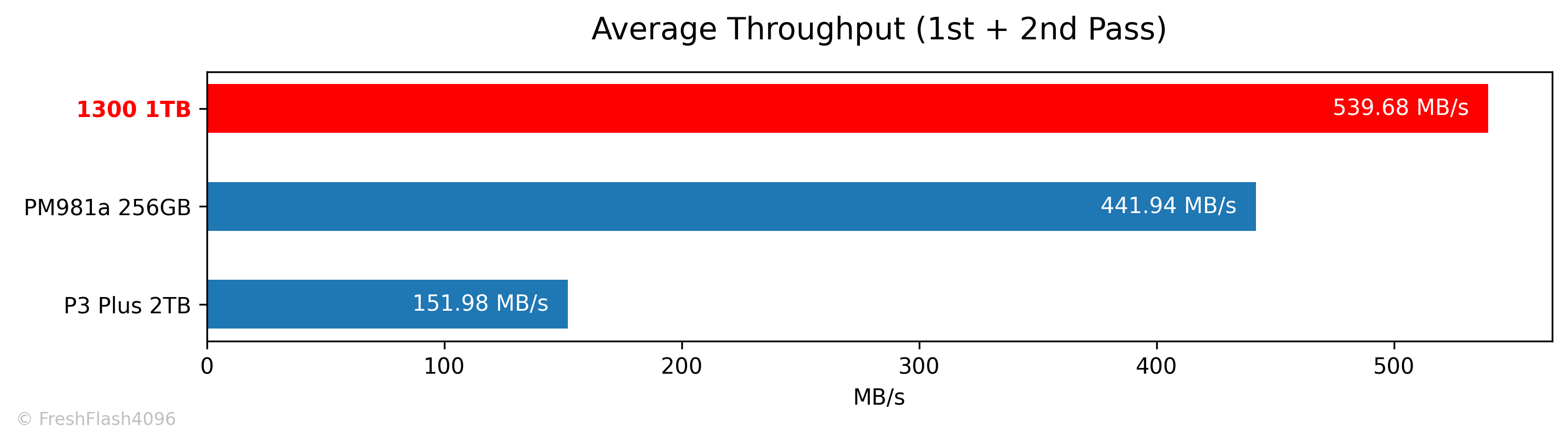
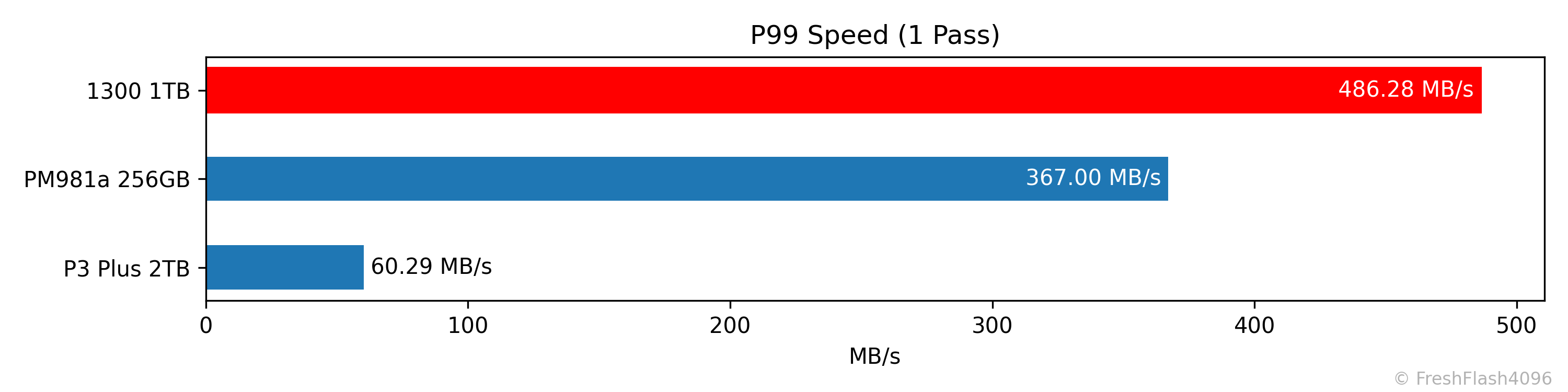
첫 번째와 두 번째의 Fill Drive에 대한 전체 평균값과 첫 번째 Fill Drive에 대한 하위 1% 속도는 DUT인 1300 1TB가 가장 우수했습니다.
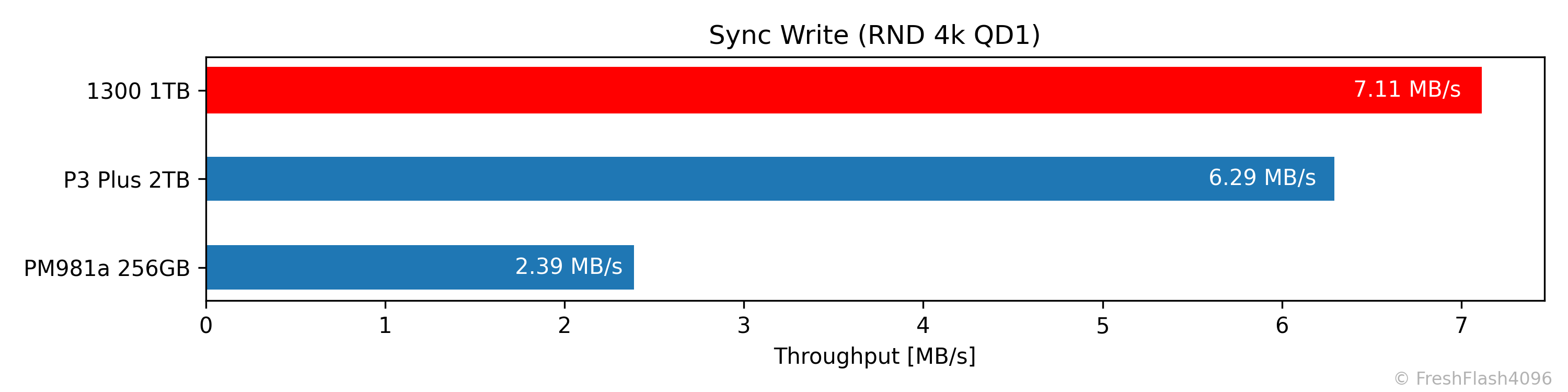
Sync Performance
자체적인 Pre-Conditioning 이후, 해당 영역에 한해서 측정됩니다. 쓰기량은 총 500MiB이며, 최대 소모 시간은 2분으로 제한합니다. sync=1 옵션을 활용했습니다.
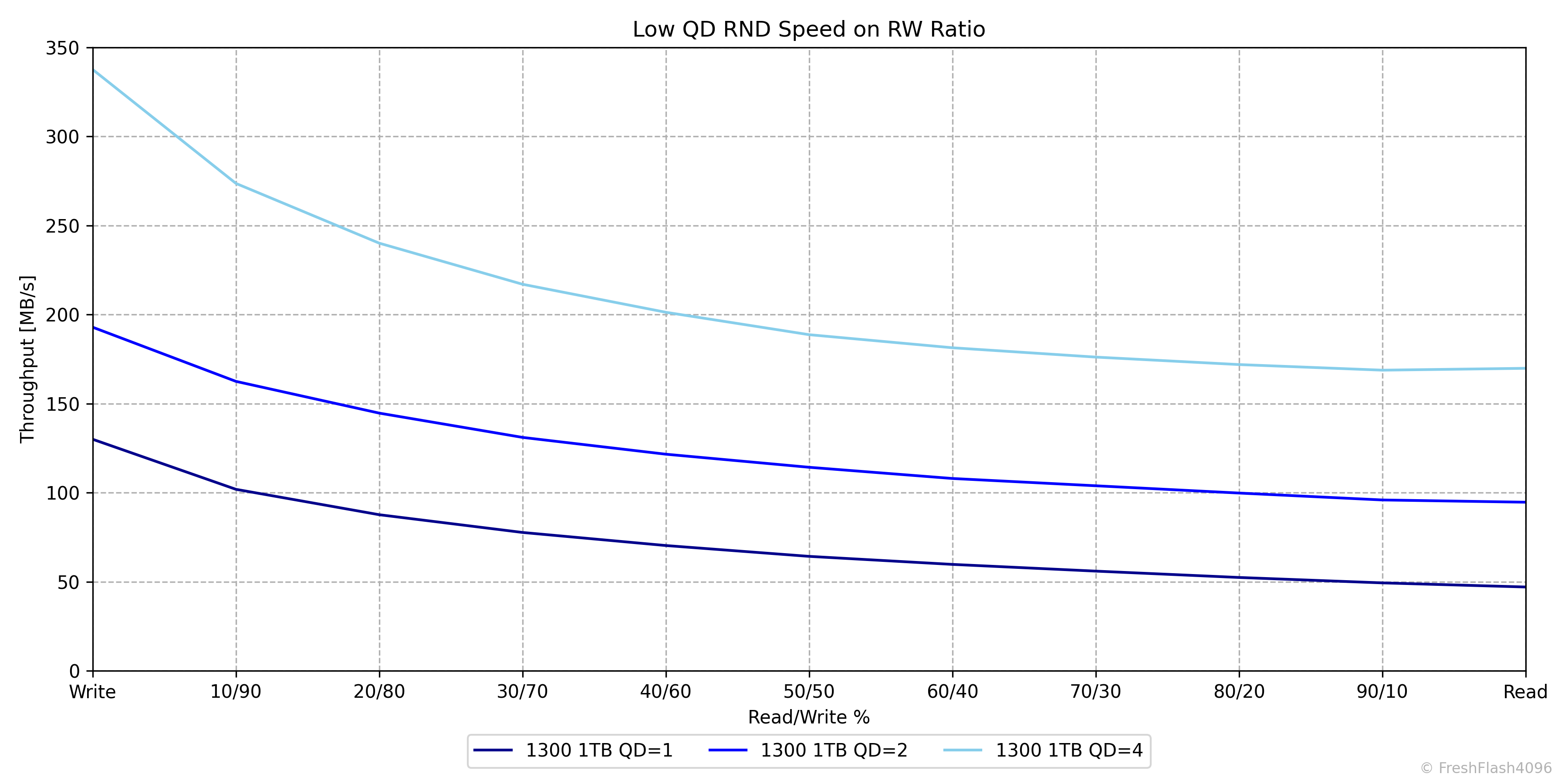
Low QD Performance by RW Ratio
이전과 마찬가지로 Pre-Conditioning 이후에 측정하며, Burst 성능을 측정하기 위해서 각 단계에서 가해지는 I/O의 양은 GB 단위가 되지 않습니다. 다시 말해, 매우 가벼운 부하입니다. 전체 용량의 75%는 이미 채워져 있지만요.
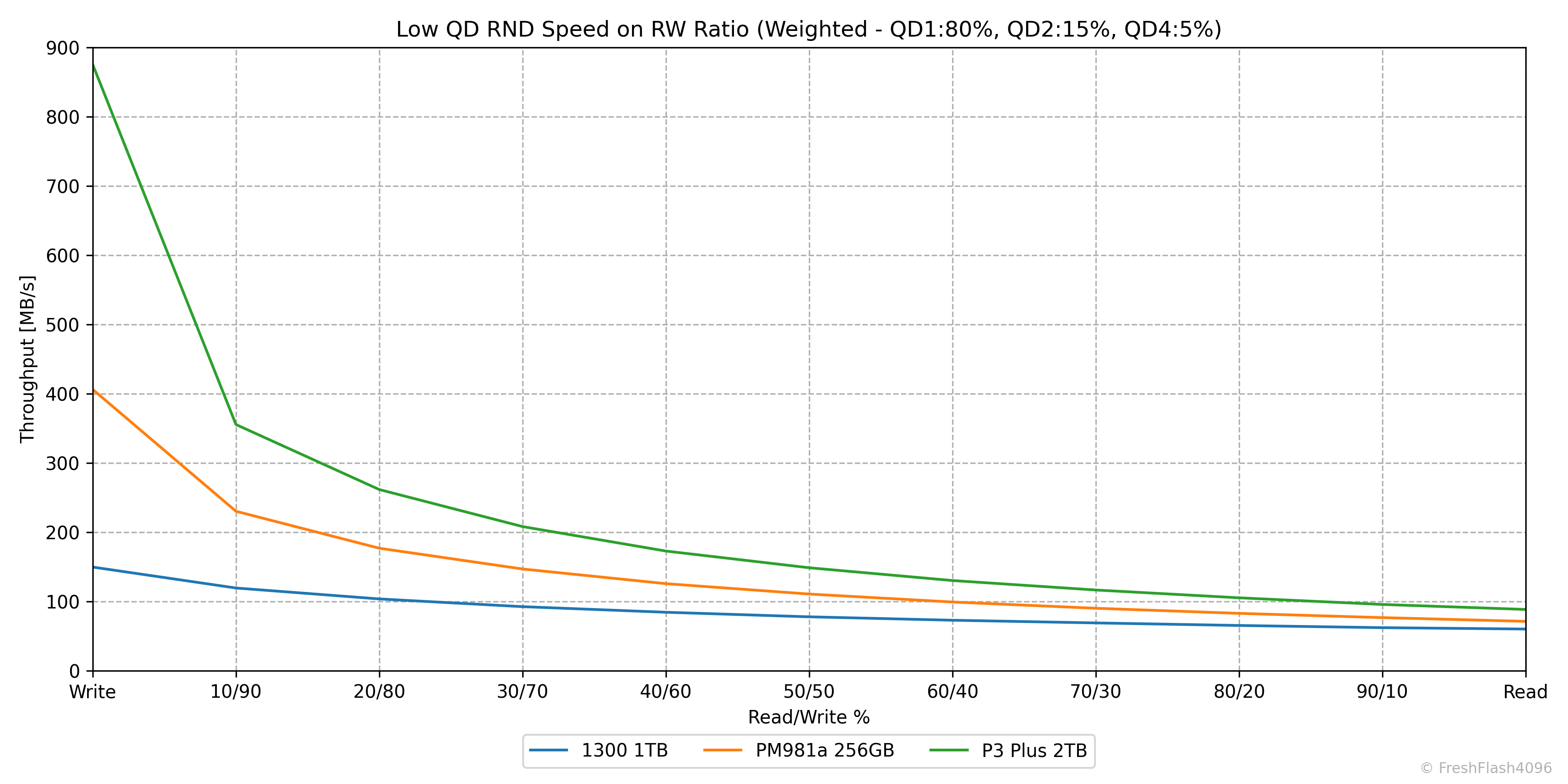
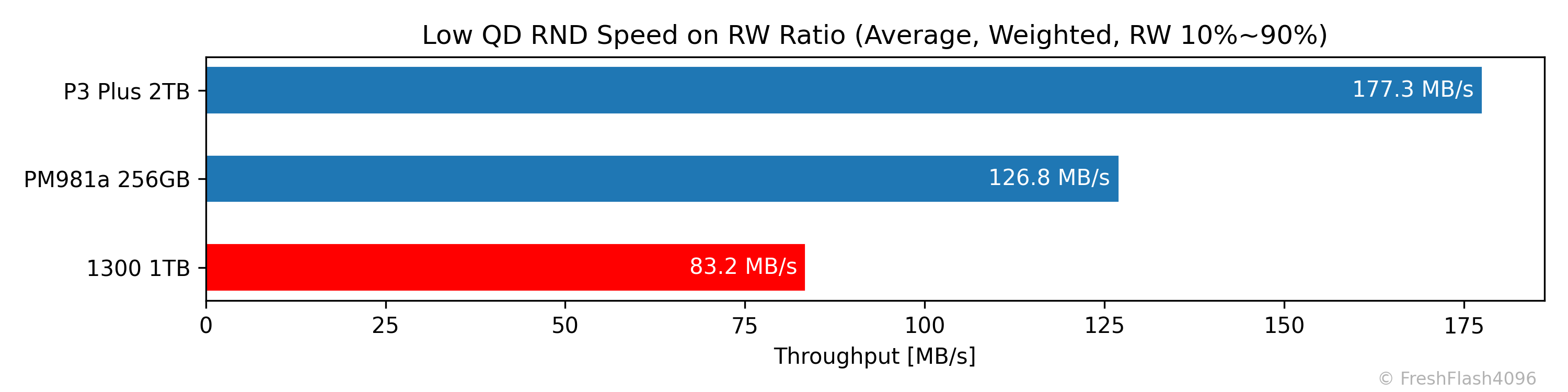
Weighted Graph
QD1 80%, QD2 15%, QD4 5%로 가중치를 부여해 보기 쉽게 나타냅니다.
eSSD Benchmarking
Purge 직후를 제외한 모든 단계 사이에는 휴식 시간이 부여되지 않습니다. Pre-Conditioning은 User Capacity의 2배를 쓰고나서도 Steady State에 진입할 때까지 이를 계속 진행합니다.
Steady State는 SEQ의 경우엔 대역폭의 기울기가 ±10%인 상태를 30초간 유지하는 것을 기준으로 하며, RND의 경우에는 IOPS의 기울기가 ±10%인 상태를 30초간 유지하는 것을 기준으로 합니다. 이를 달성할 수 없을 땐 User Capacity의 23배까지 쓰기를 진행합니다.
모든 워크로드는 User Capacity의 전체 영역에 대해서 진행하며, 각각 30초의 적응 시간을 가진 후에 5분 동안 성능측정을 진행합니다. 다시 말해, 128k Read 성능을 측정한다면 QD1 ~ QD256까지 총 9개의 작업이 있으며, 모든 작업이 30초의 적응 시간과 5분의 측정시간이 부여됩니다.
역시 자세한 벤치마크 방법론에 대해서는 이전에 작성한 Refresh Benchmark를 참고해주시길 바랍니다.
4-Corners Performance
SEQ Pre-Conditioning
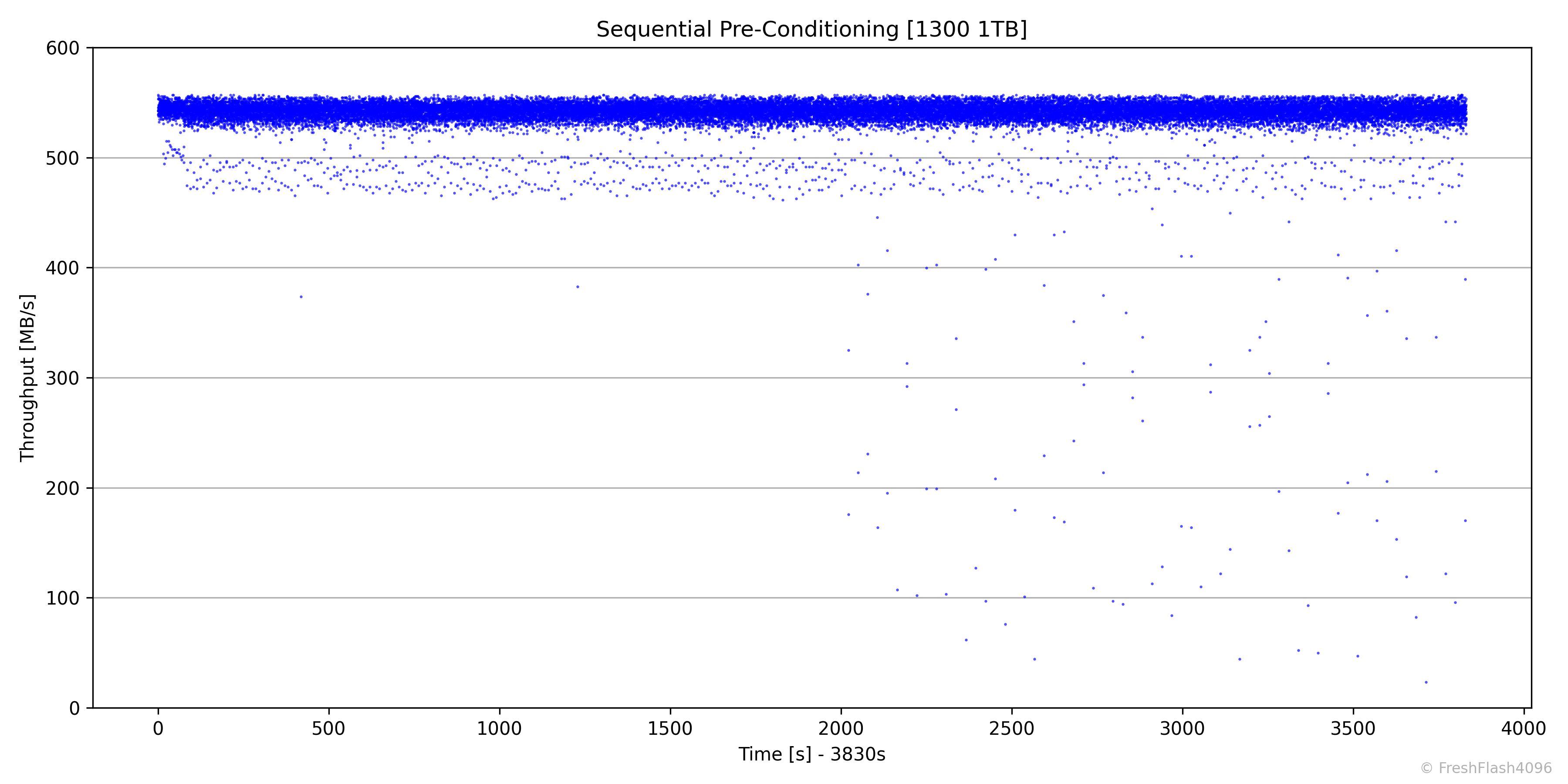
SEQ Pre-Conditioning은 약 1시간에 걸쳐 진행되었으며, 527MB/s로 Steady State에 진입했습니다.
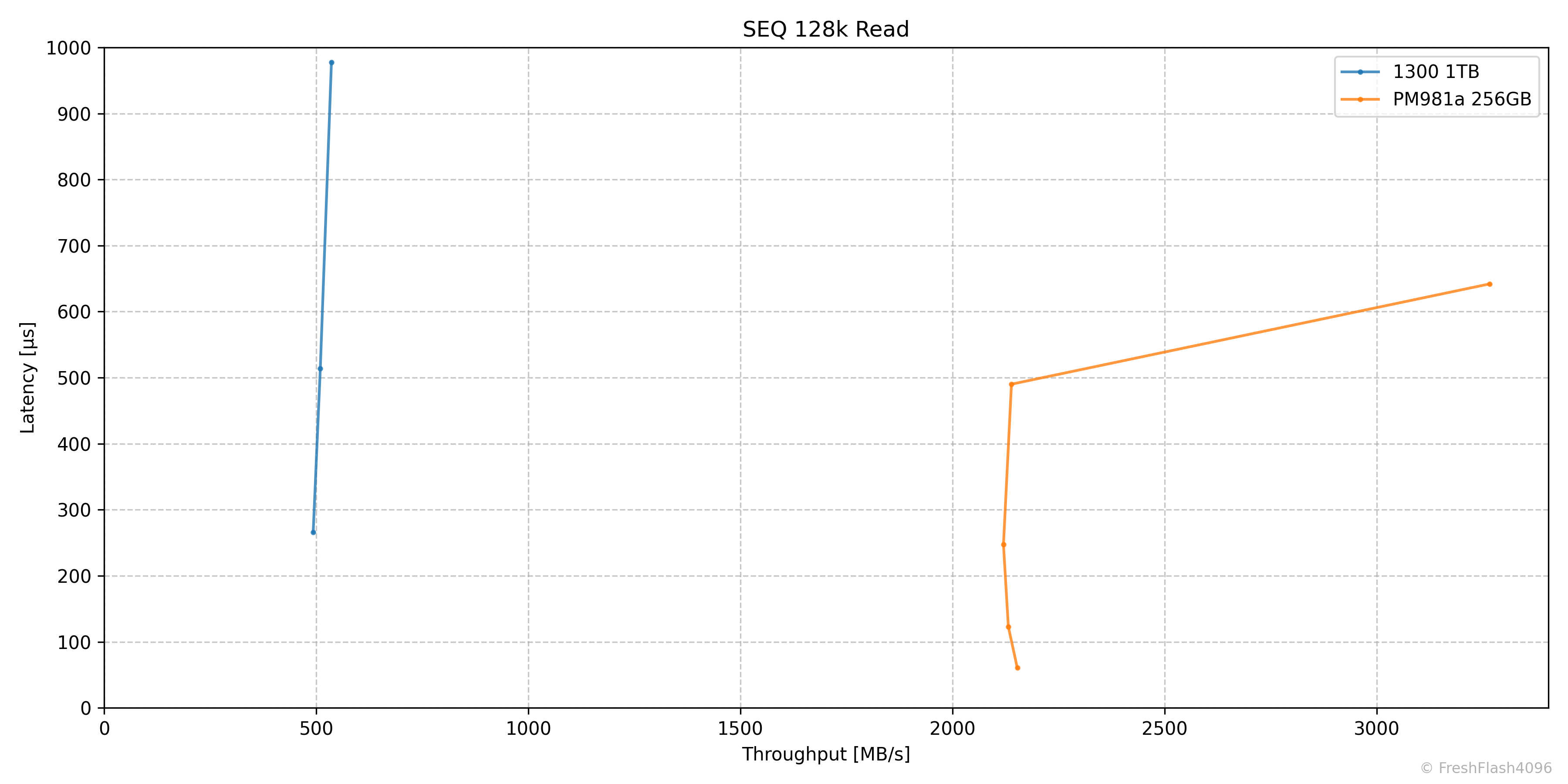
SEQ 128k Read
SEQ 128k Write
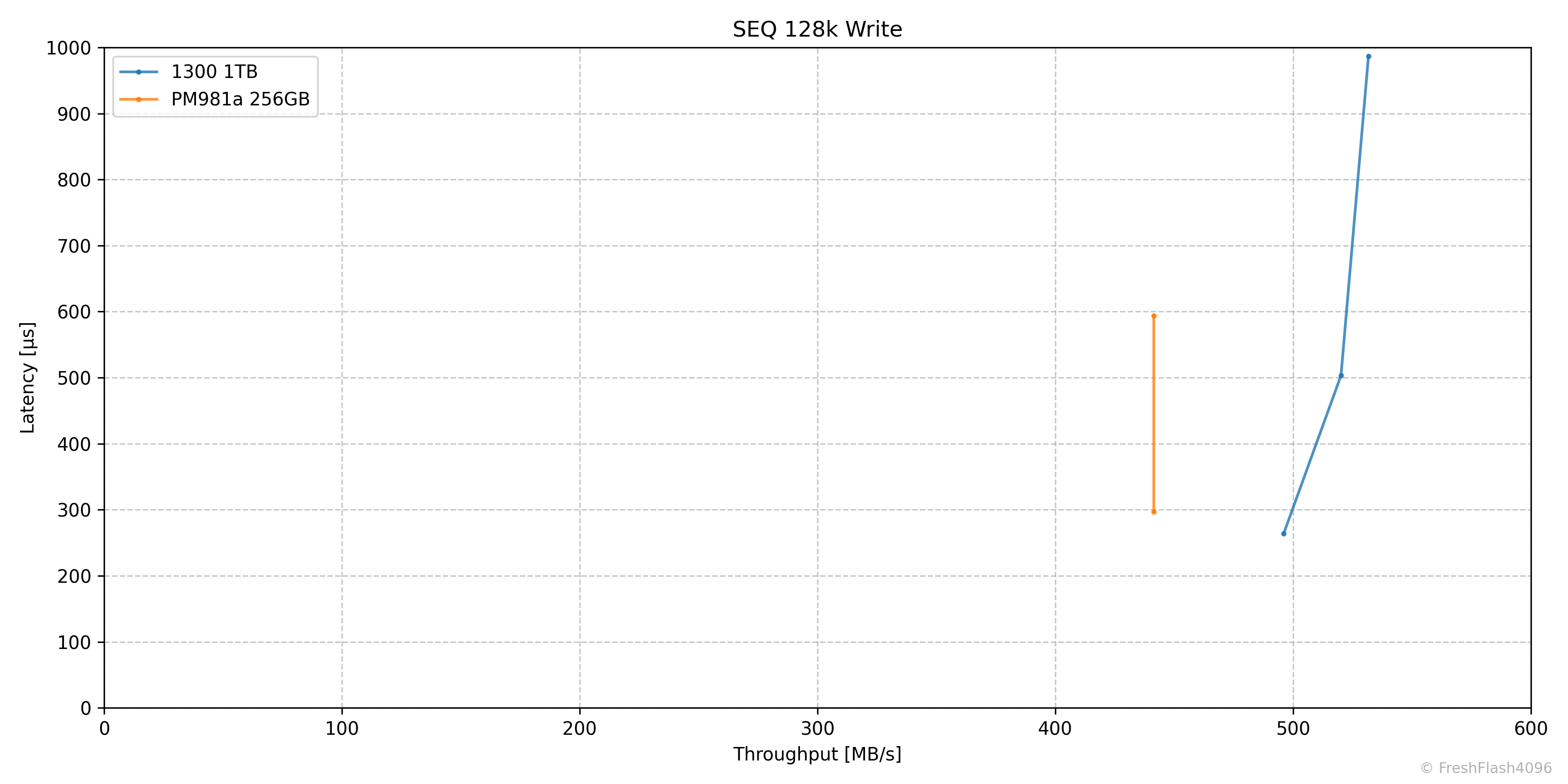
Fill Drive에서 예상할 수 있지만, Steady State에서 순차 쓰기는 1300 1TB가 PM981a 256GB에 비해 우수했습니다. 물론, 용량이 다르다는 점이 중요합니다.
RND Pre-Conditioning
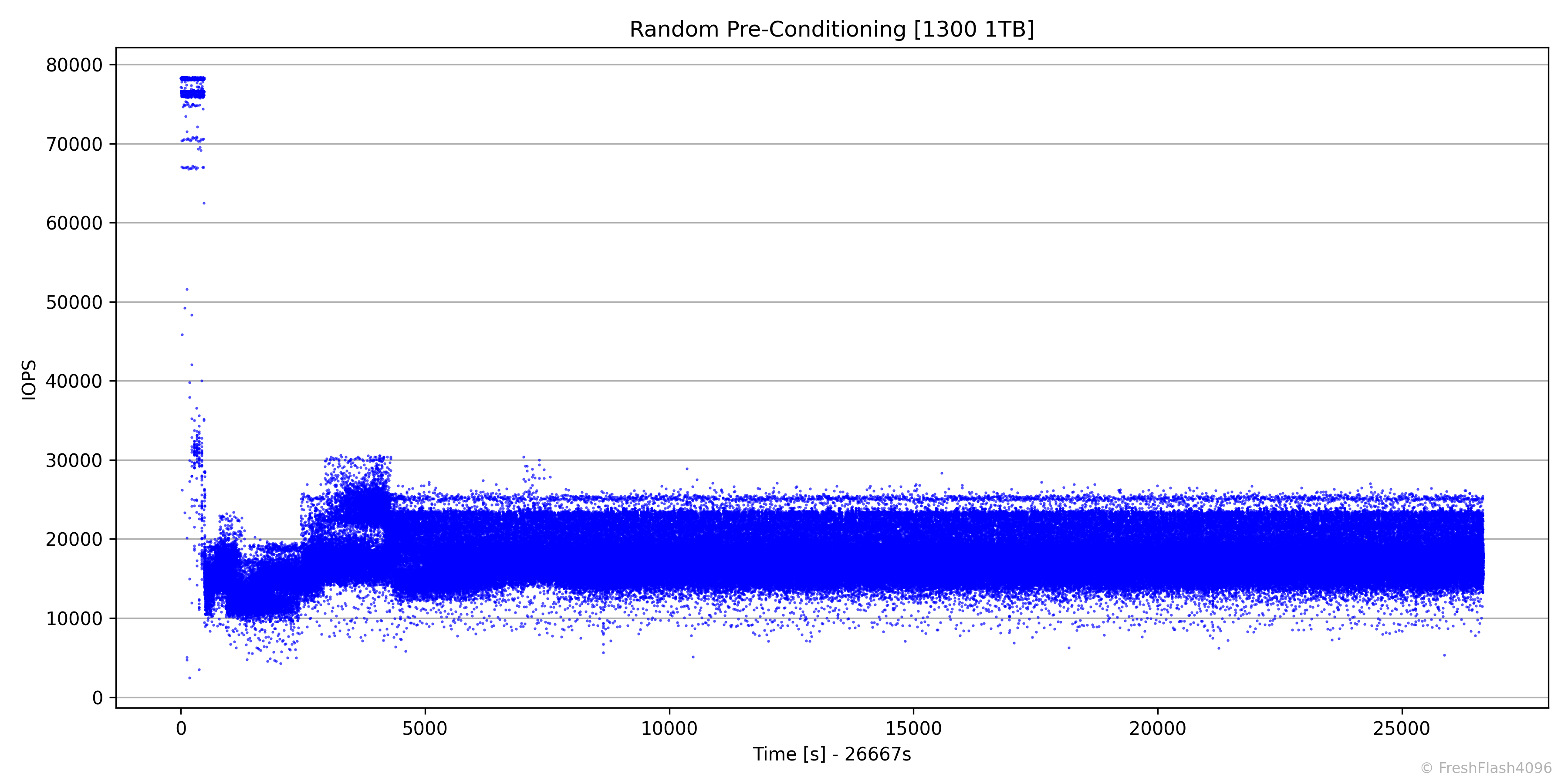
RND Pre-Conditioning은 7시간 30분이 안 되게 소모되었으며, 17.5k IOPS로 Steady State에 진입했습니다.
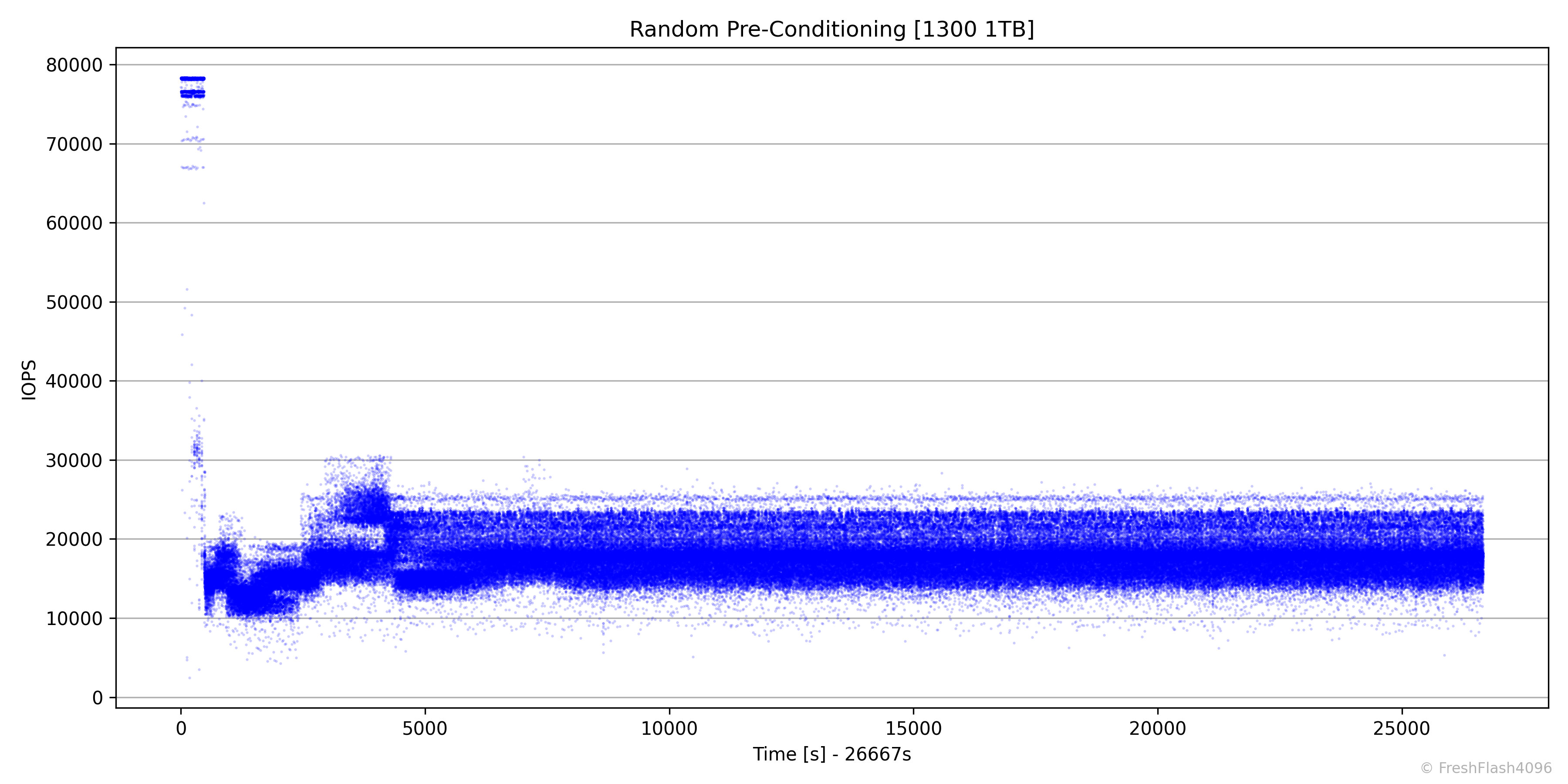
점의 투명도를 높여보았습니다. 이제서야 파란 점들 사이의 빈 공간이 살짝 보입니다.
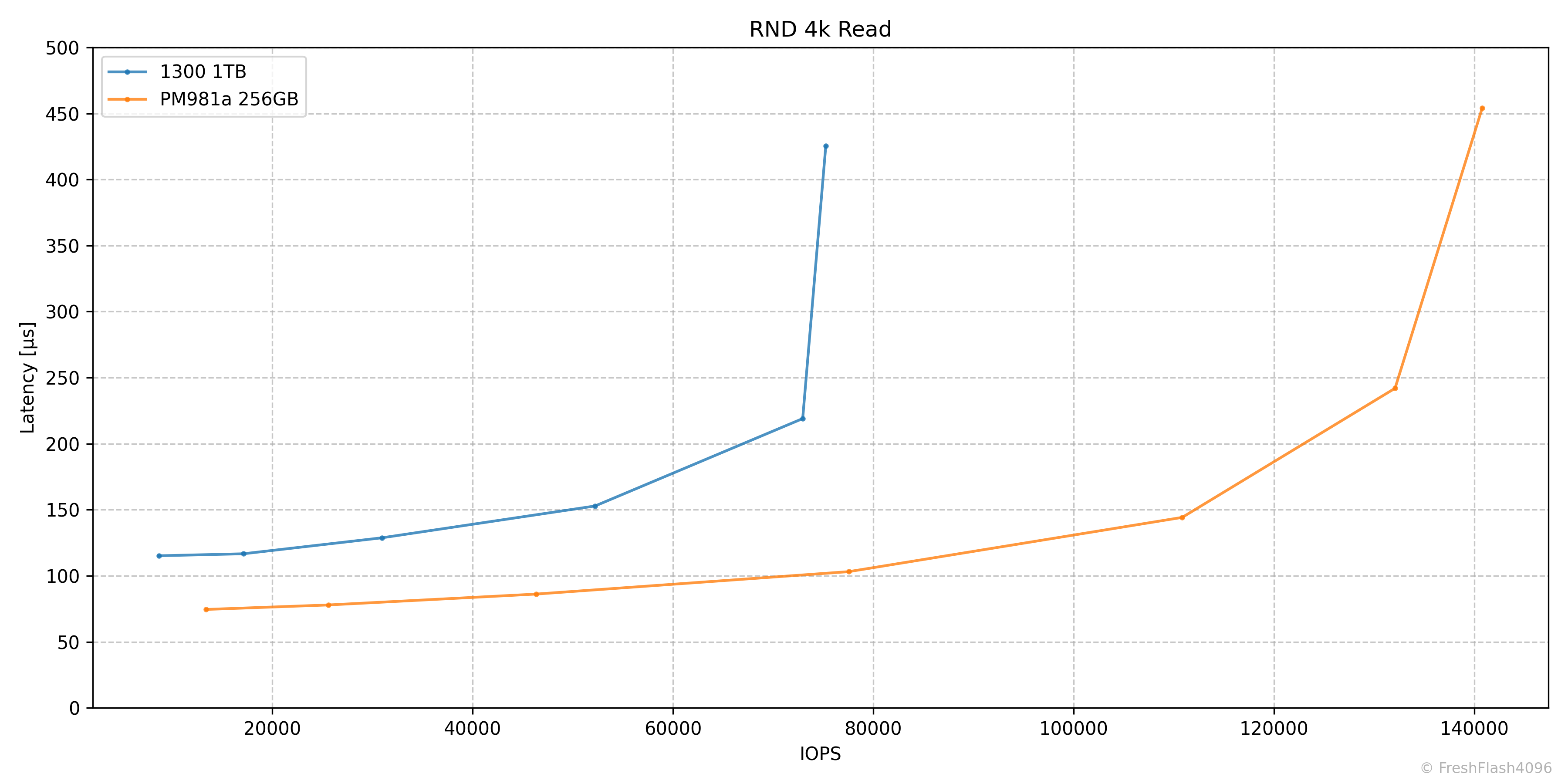
RND 4k Read
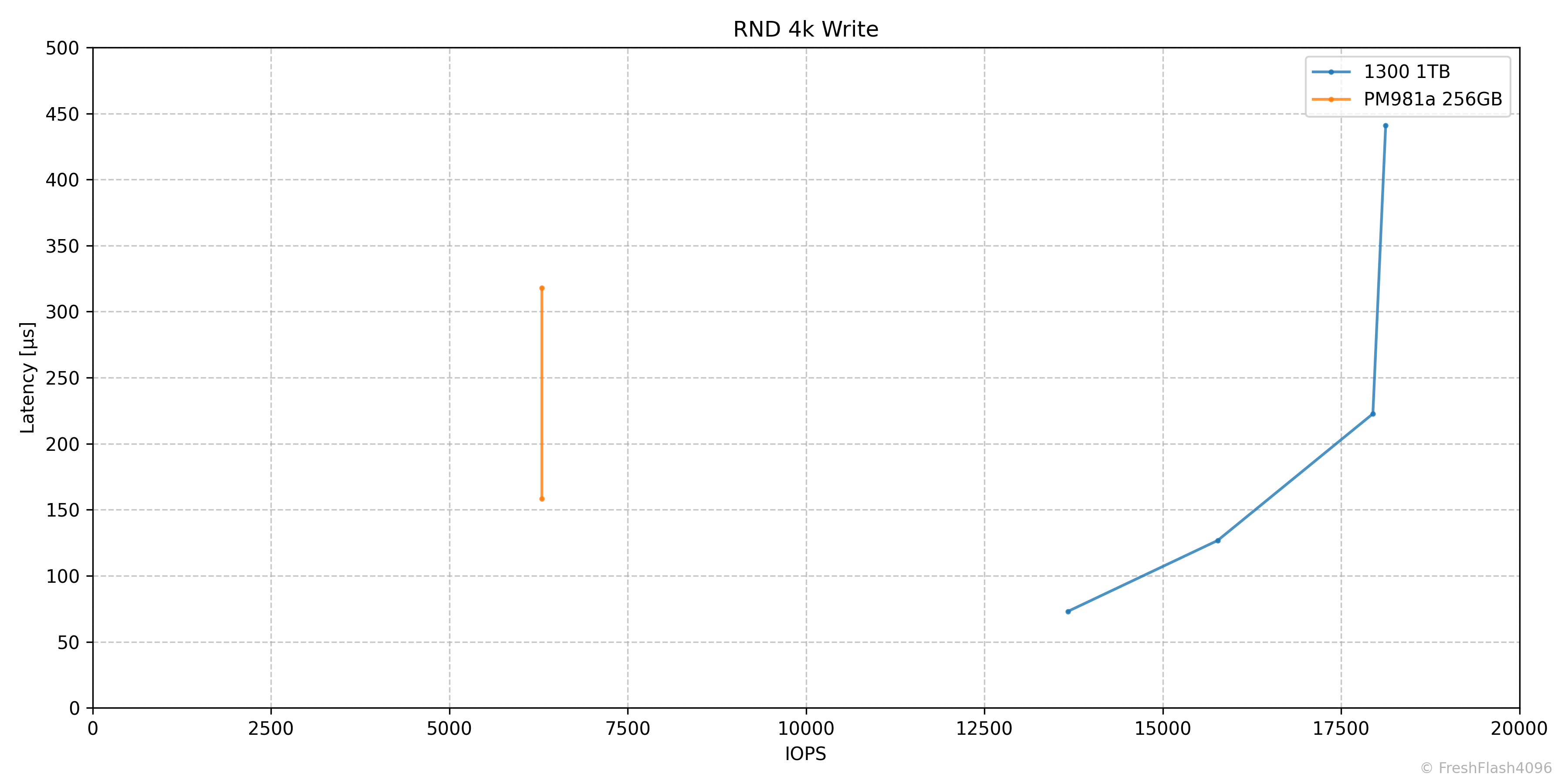
RND 4k Write
4-Corners Consistency
QD에 따른 4-Corners Performance의 안정적인 정도를 제시합니다. 상위 99.9%값과 평균을 이용하는데, SEQ 128k에서는 Bandwidth를 기준으로, RND 4k에서는 IOPS를 기준으로 계산합니다. 참고로, RND 4k에서 QD1에 대한 값은 이후 Tail Latency에서 자세히 살펴보기에 제외됩니다.
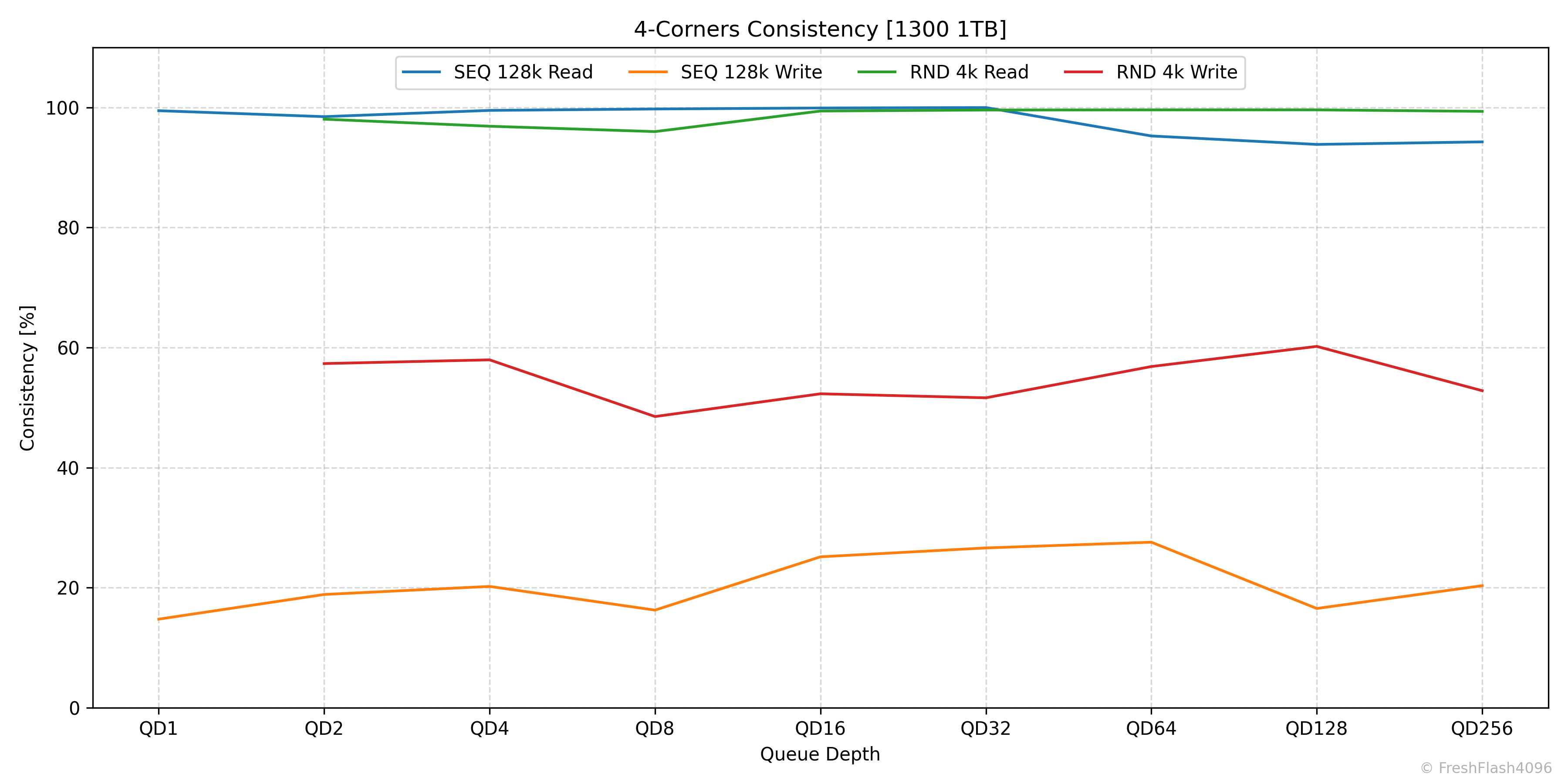
SATA SSD이기에 QD32까지가 유효한 값이라는 것을 기억해주시기 바랍니다.
Specific Workload Performance
4-Corners Performance가 아닌 워크로드를 분리했습니다. 단, 워크로드 이름은 편의상 붙인 것뿐이며, 실제 환경에서는 다양한 Block Size와 RW 비율이 나타난다는 것을 명심해야 합니다. Block Size들의 정확한 비율과 RW 비율을 결정하기 힘들어 대략 분류한, 가상의 워크로드입니다.
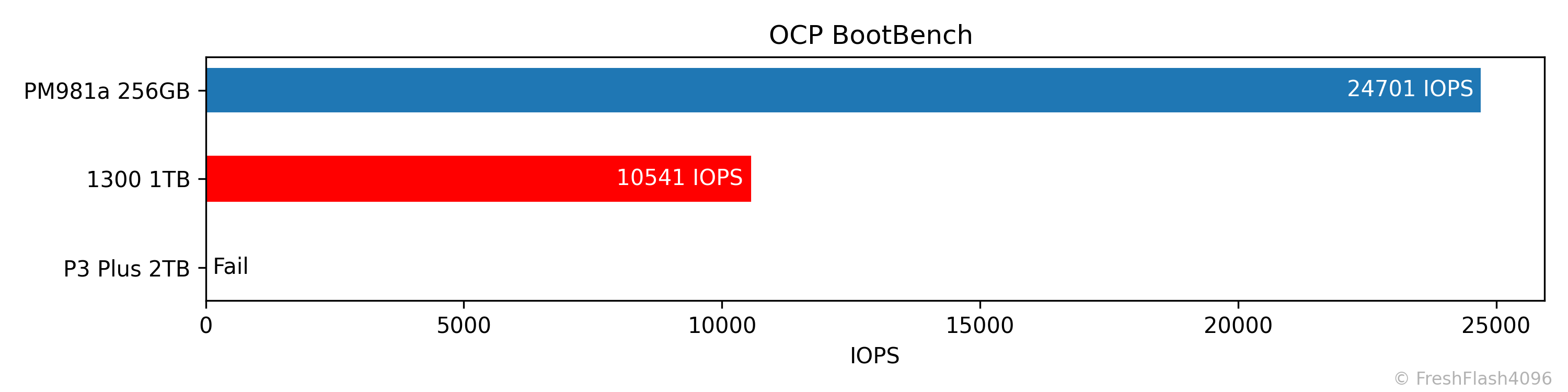
Boot Workload (OCP BootBench)
Hyperscale에서의 Boot Drive로 사용될 때의 성능을 측정하는 벤치마크입니다. SEQ Write로 User Capacity가 2번 채워지면, 동기 쓰기, TRIM, 읽기가 동시에 가해지며, 결과의 지표는 읽기 IOPS입니다. 60k IOPS를 통과하면 합격입니다.
Read Intensive Workload (SEQ 128k R95:W05)
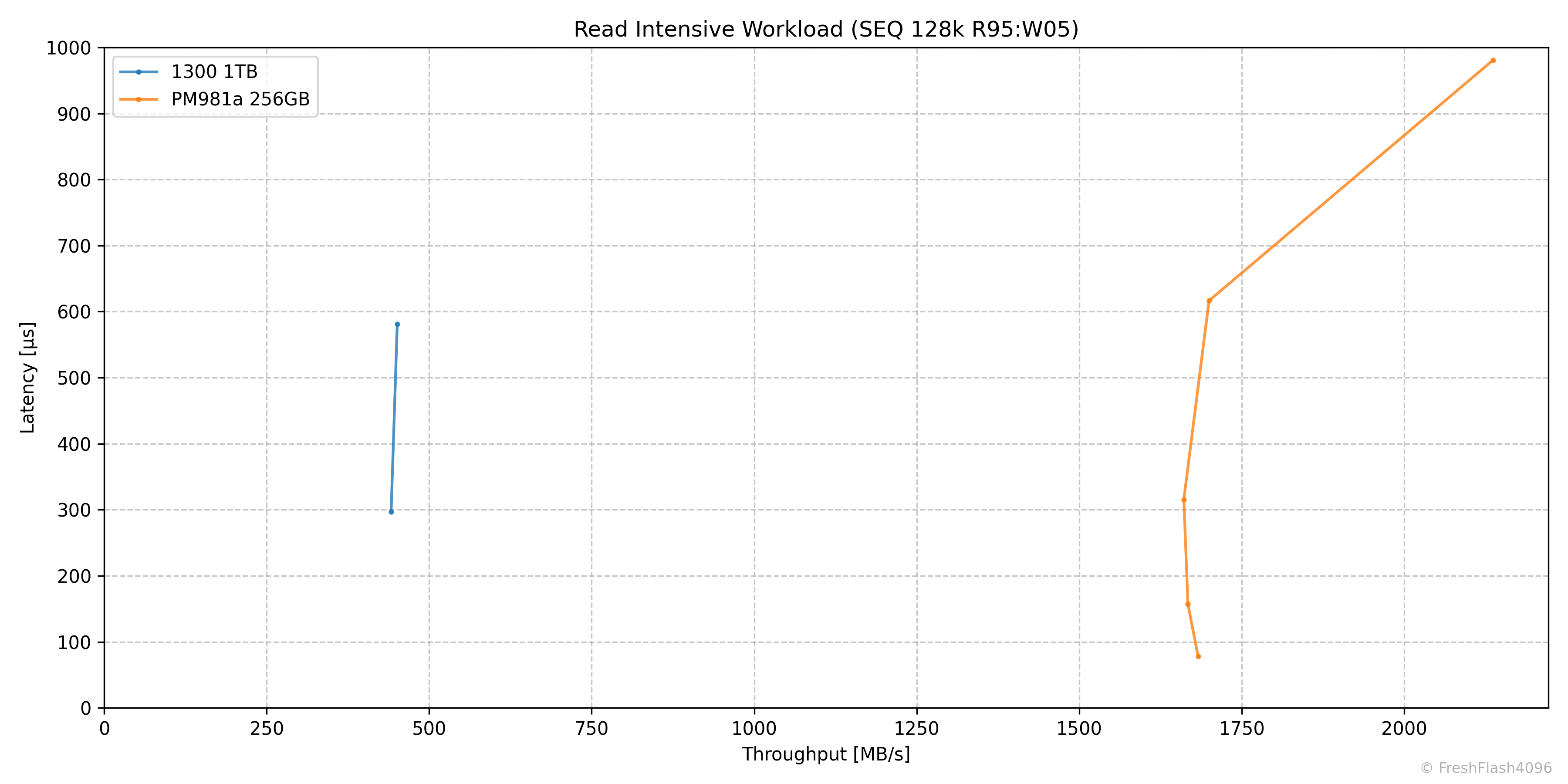
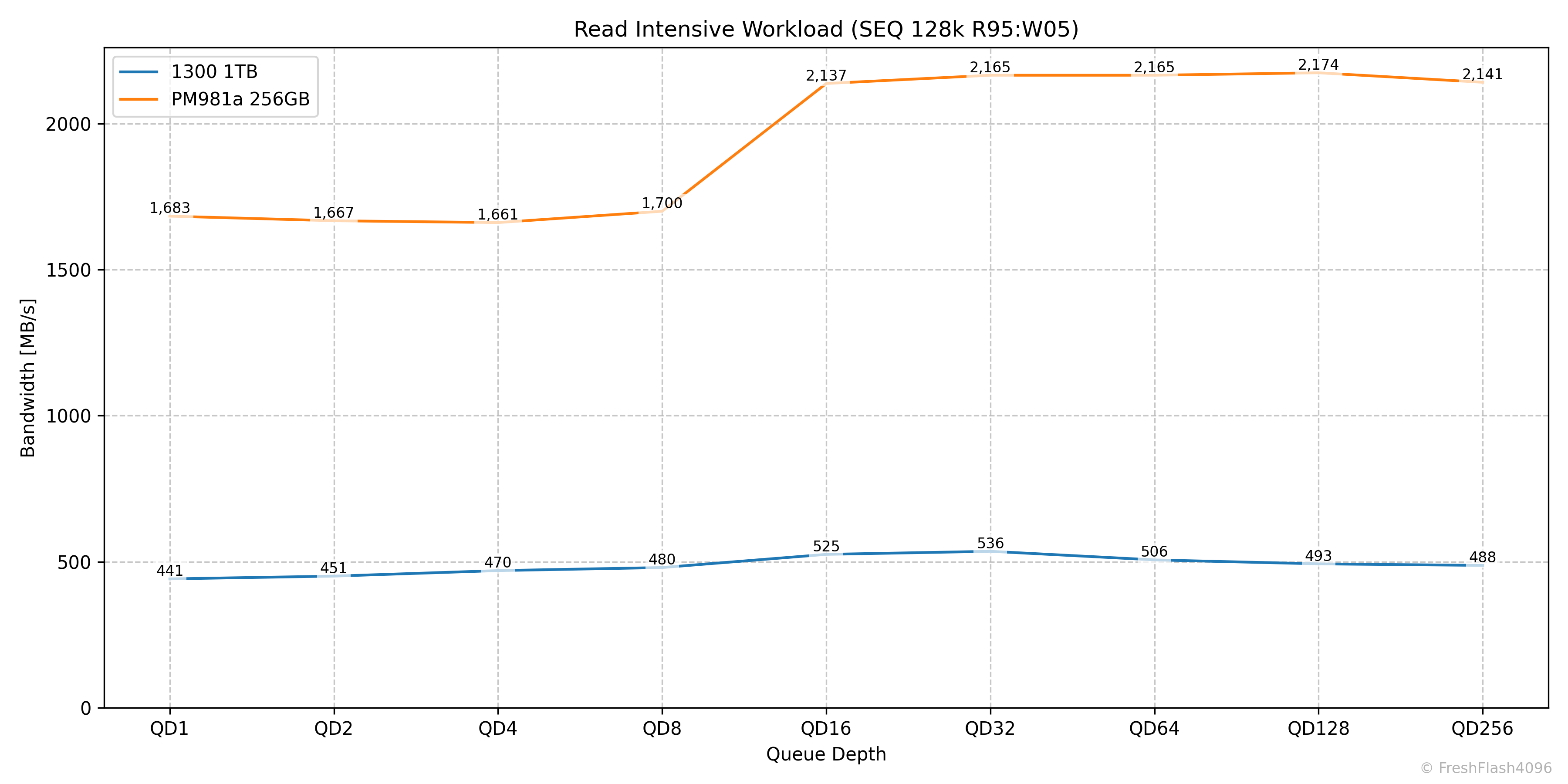
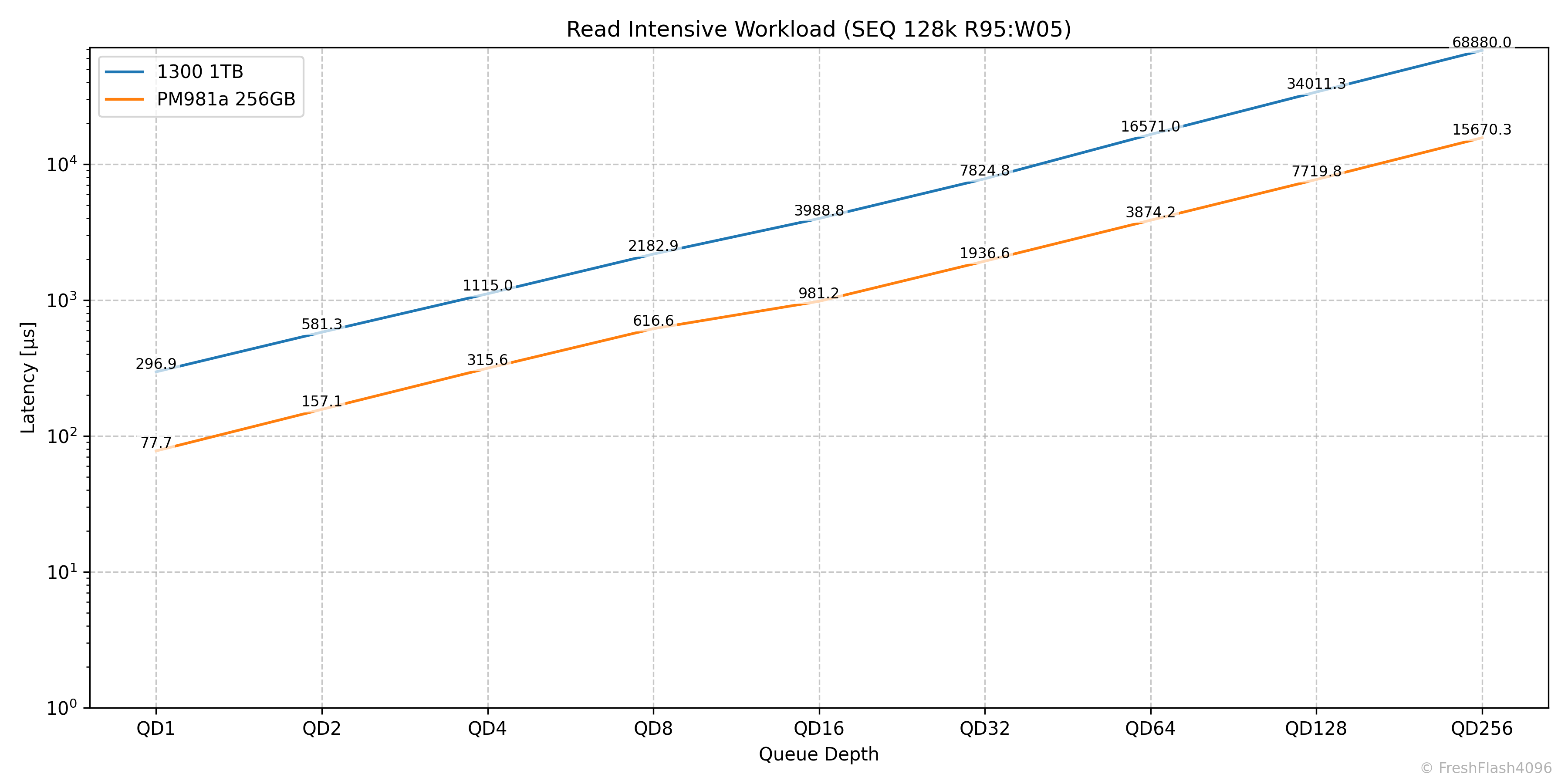
그래프는 적절한 지연시간으로 잘라냈지만, Throughput자체는 QD32까지 미세하게 증가하는 모습을 보여줍니다.
Mainstream Workload (RND 4k R70:W30)
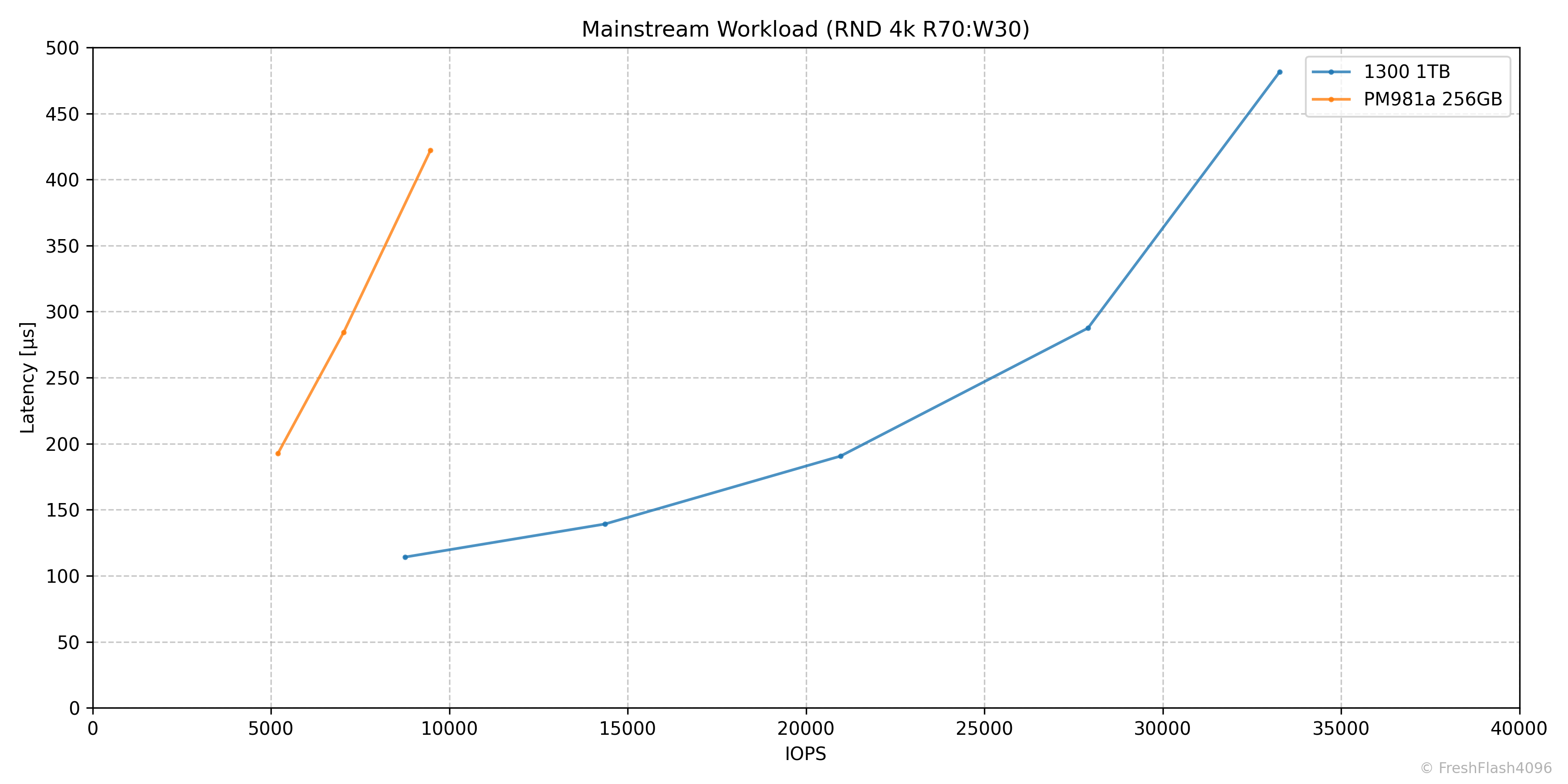
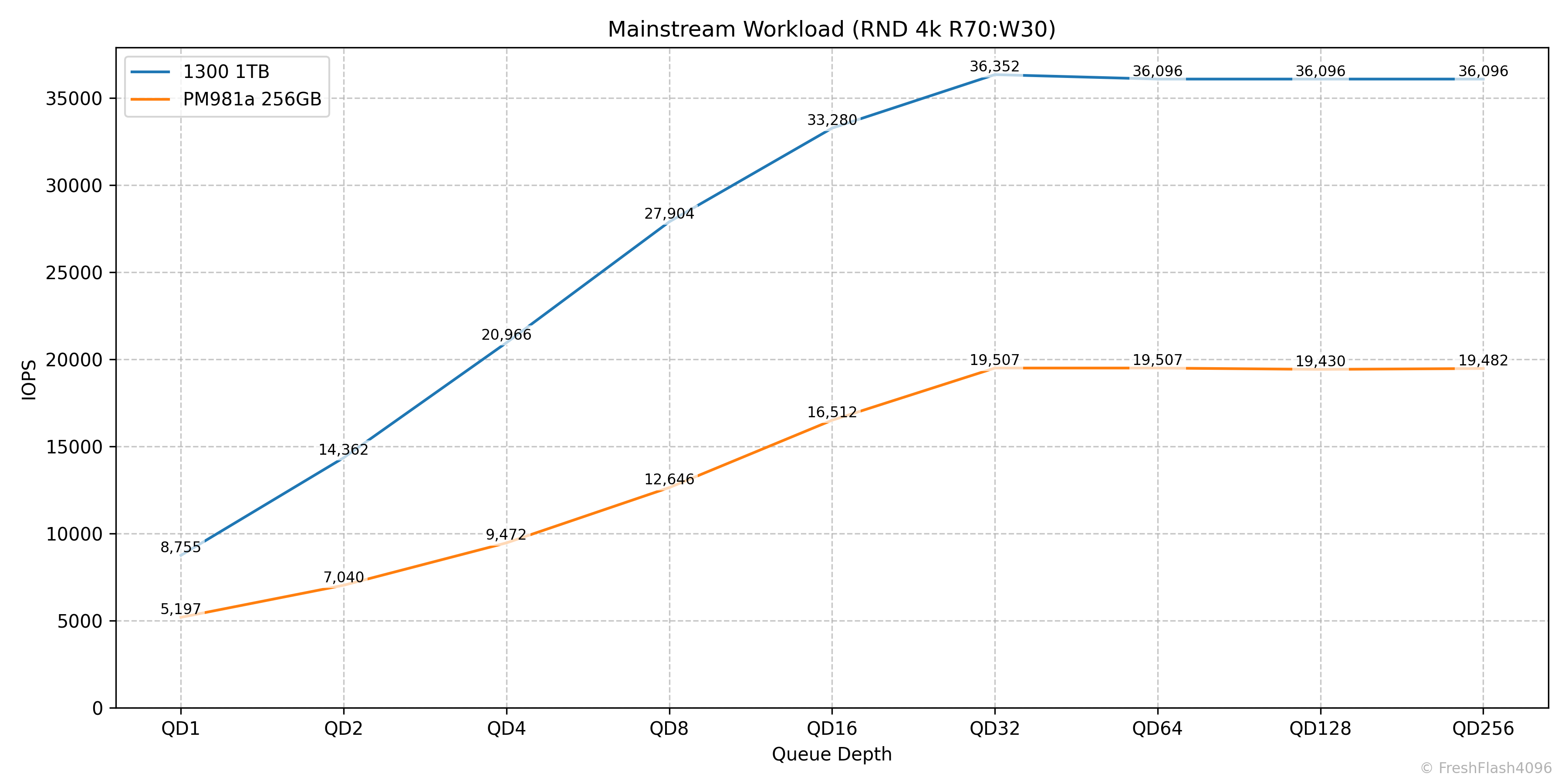
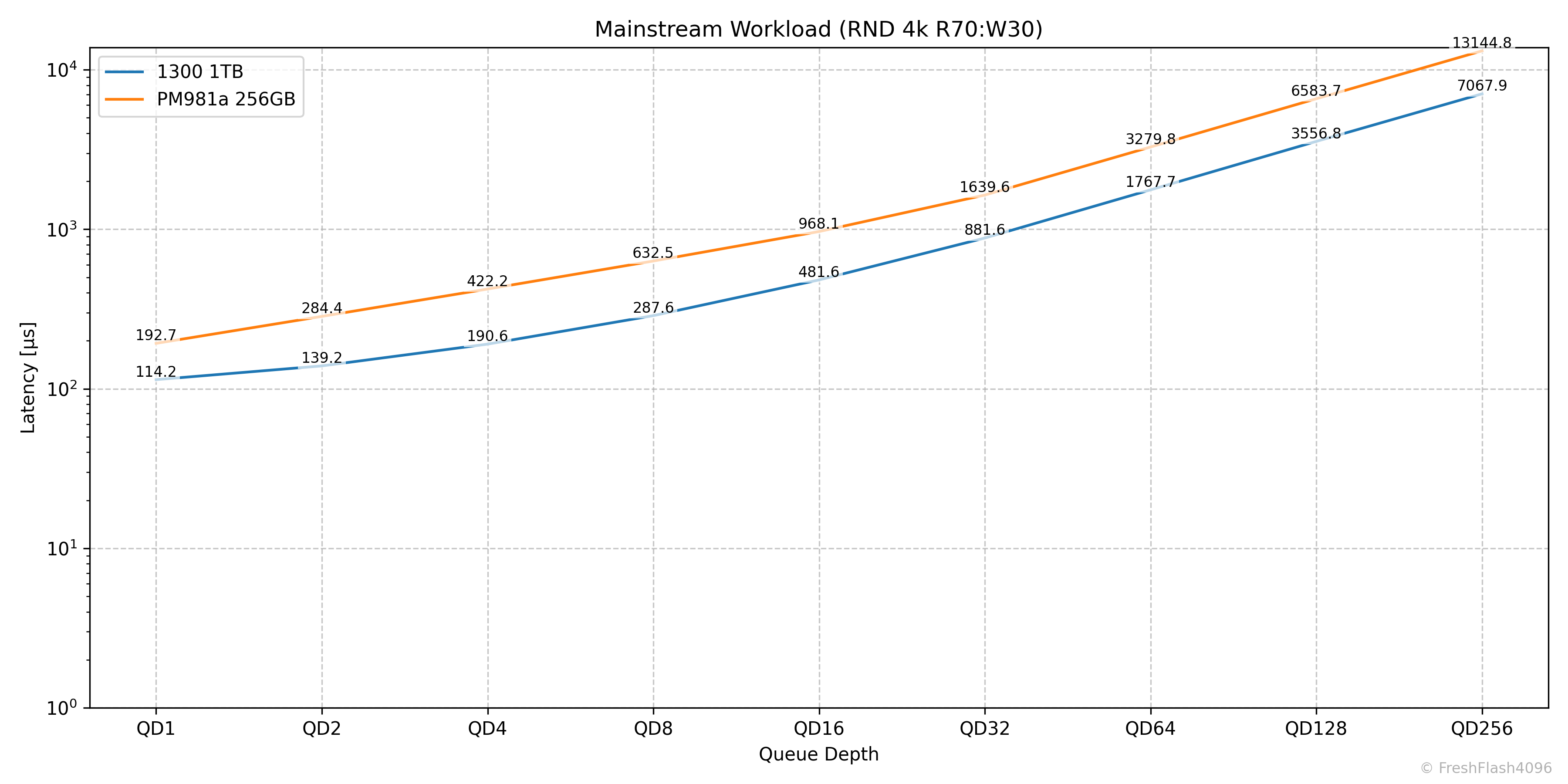
마찬가지로 종합 그래프엔 QD16까지 반영되었지만, 실제로는 QD32에서 36k IOPS를 보여주는 것을 확인할 수 있었습니다.
Write Intensive Workload (RND 4k R50:W50)
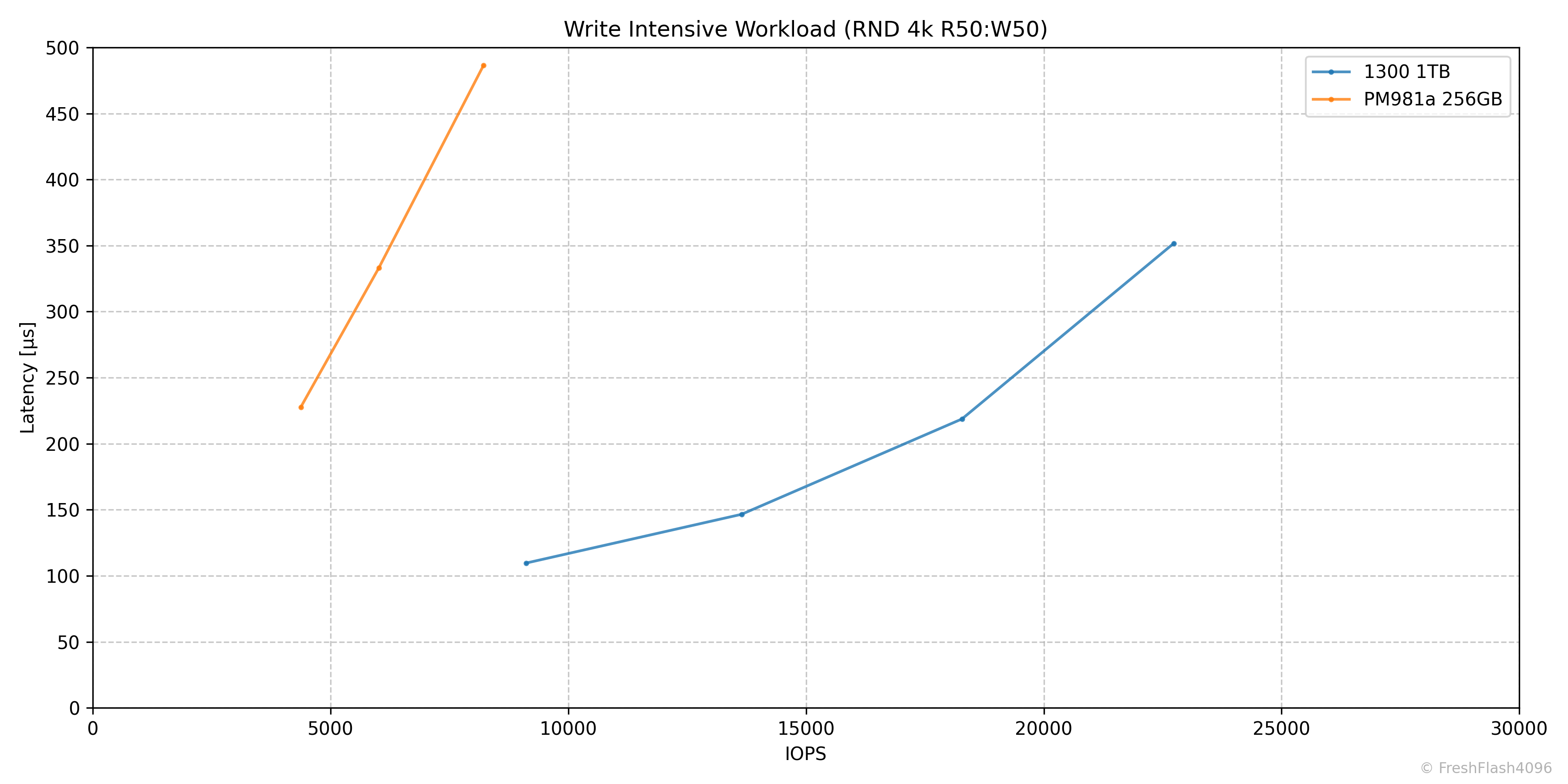
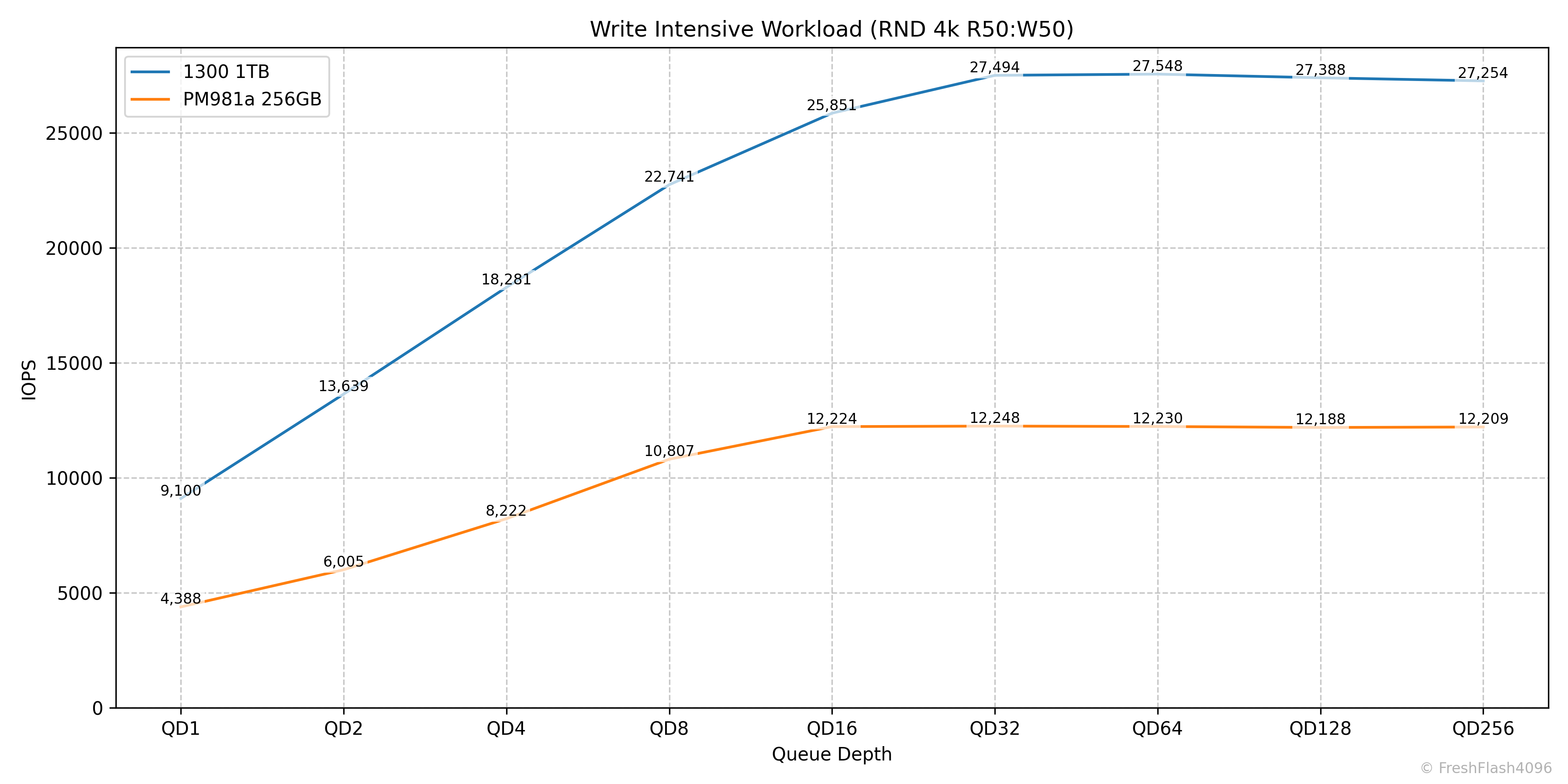
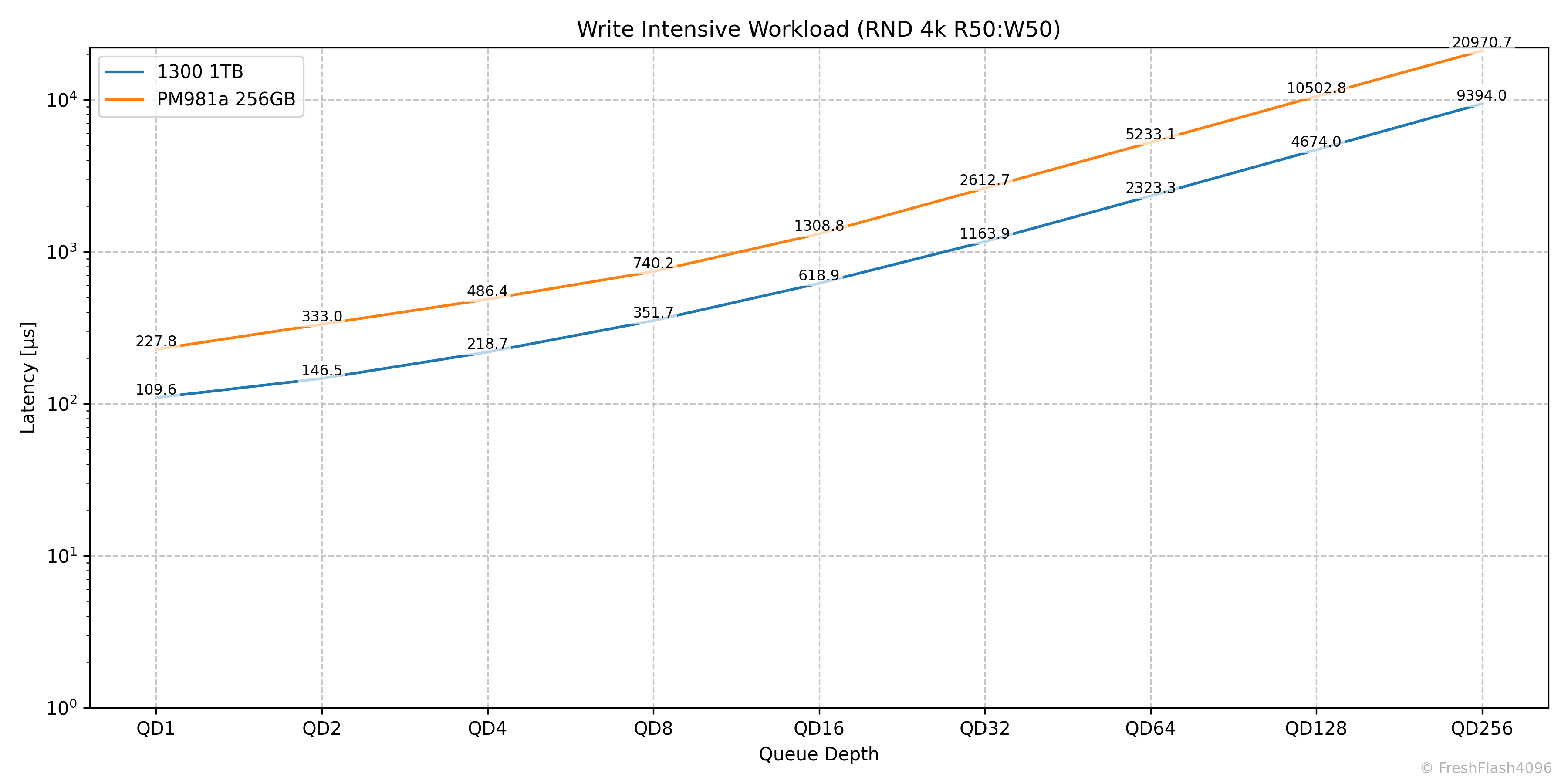
QD32까지 착실하게 Throughput이 증가해 27.5k IOPS를 보여줍니다.
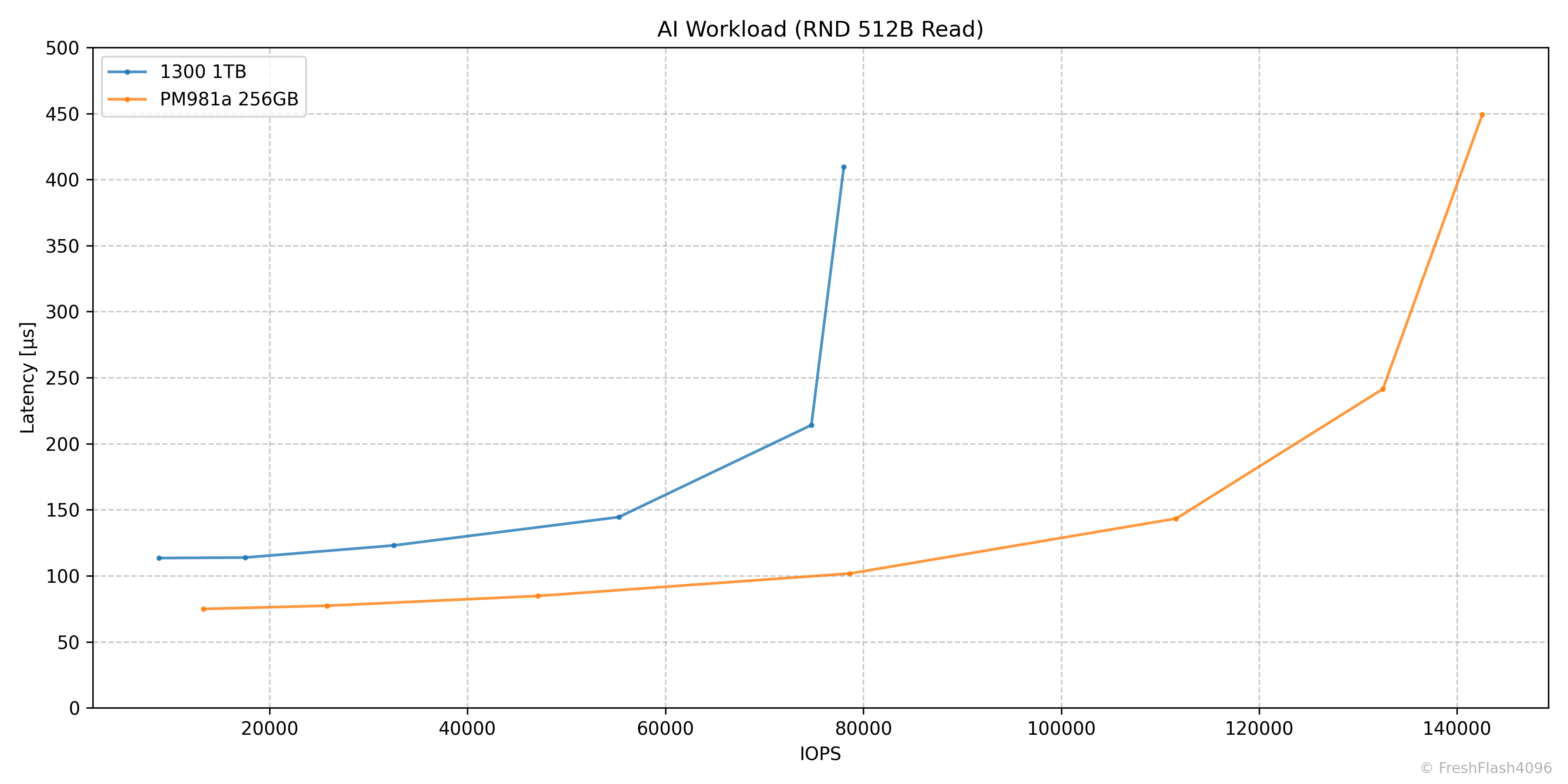
AI Workload (RND 512B Read)
Random 4k QD1 Tail Latency
Latency에서 가장 느린 구간을 의미합니다. 그렇기 때문에 QoS(Quality of Service)에 큰 영향을 미치고, 실제로 eSSD의 데이터시트에서는 QoS를 명시하고 있습니다.
여기에선 100ms나 10ms 단위가 아닌, 모든 개별 I/O에 대한 지연시간을 카운트하여 그래프를 그립니다. 그렇기 때문에 데이터가 상당히 방대해, 이 항목은 RND 4k QD1에 대해서만 진행합니다.
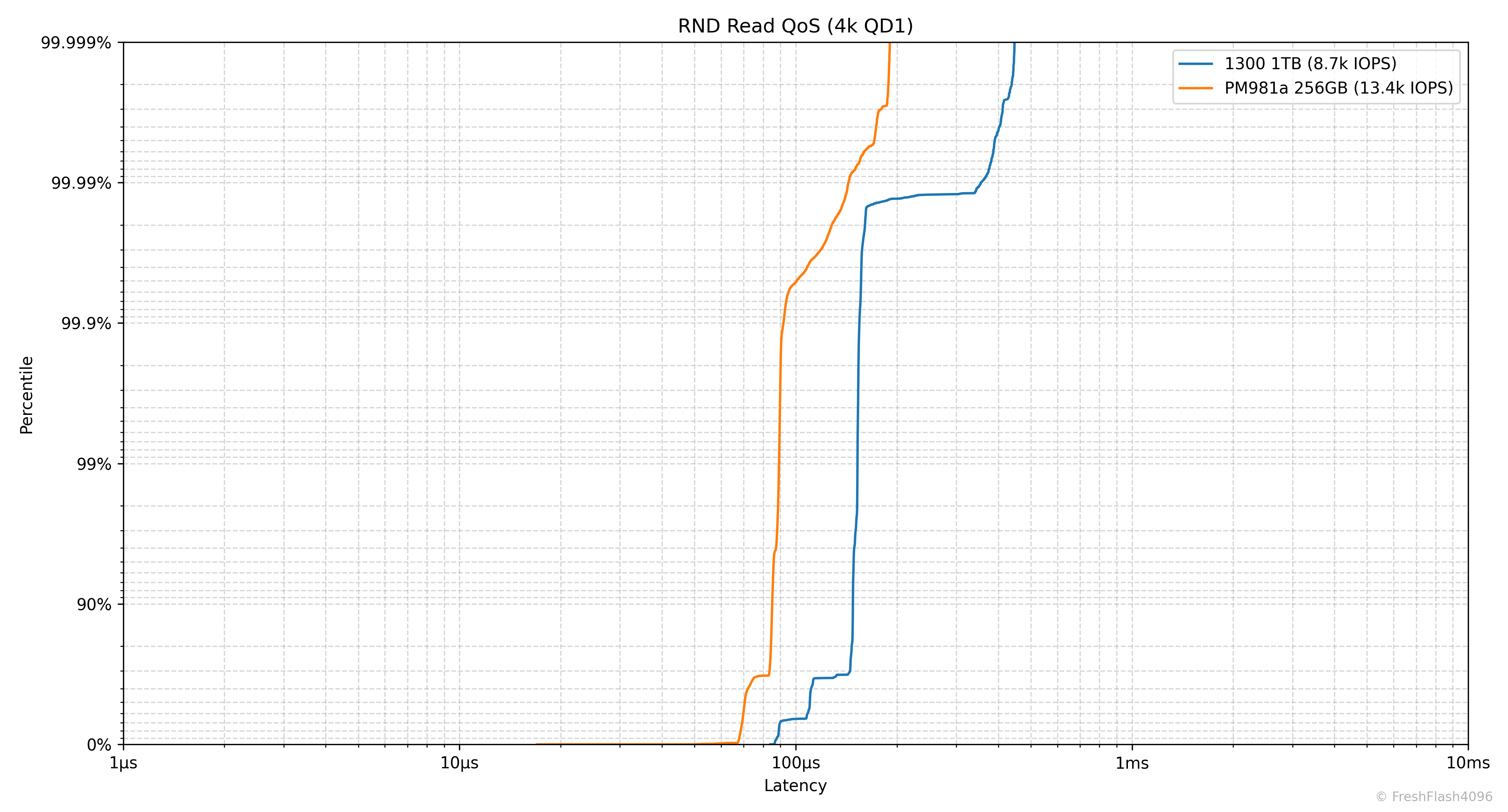
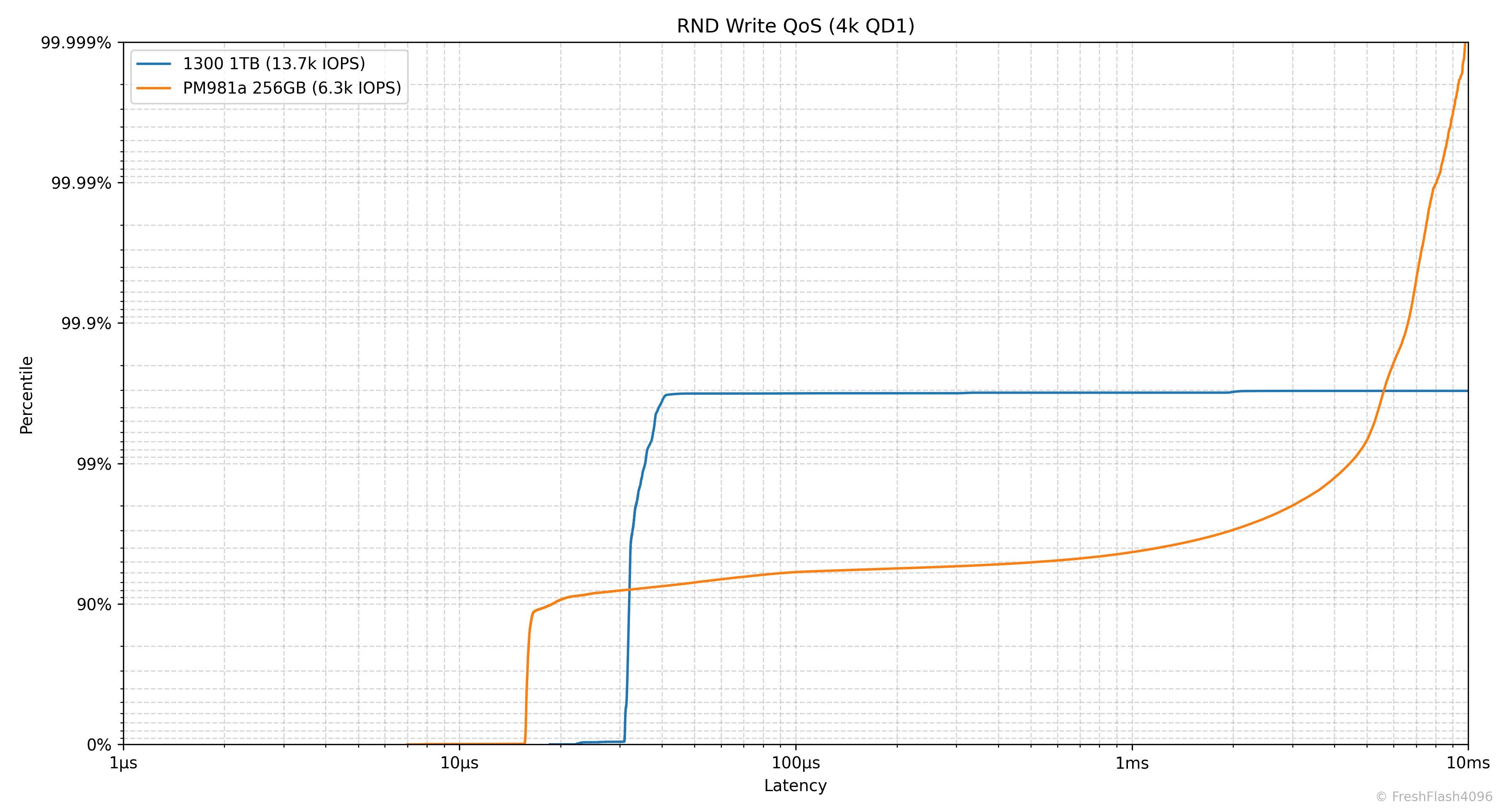
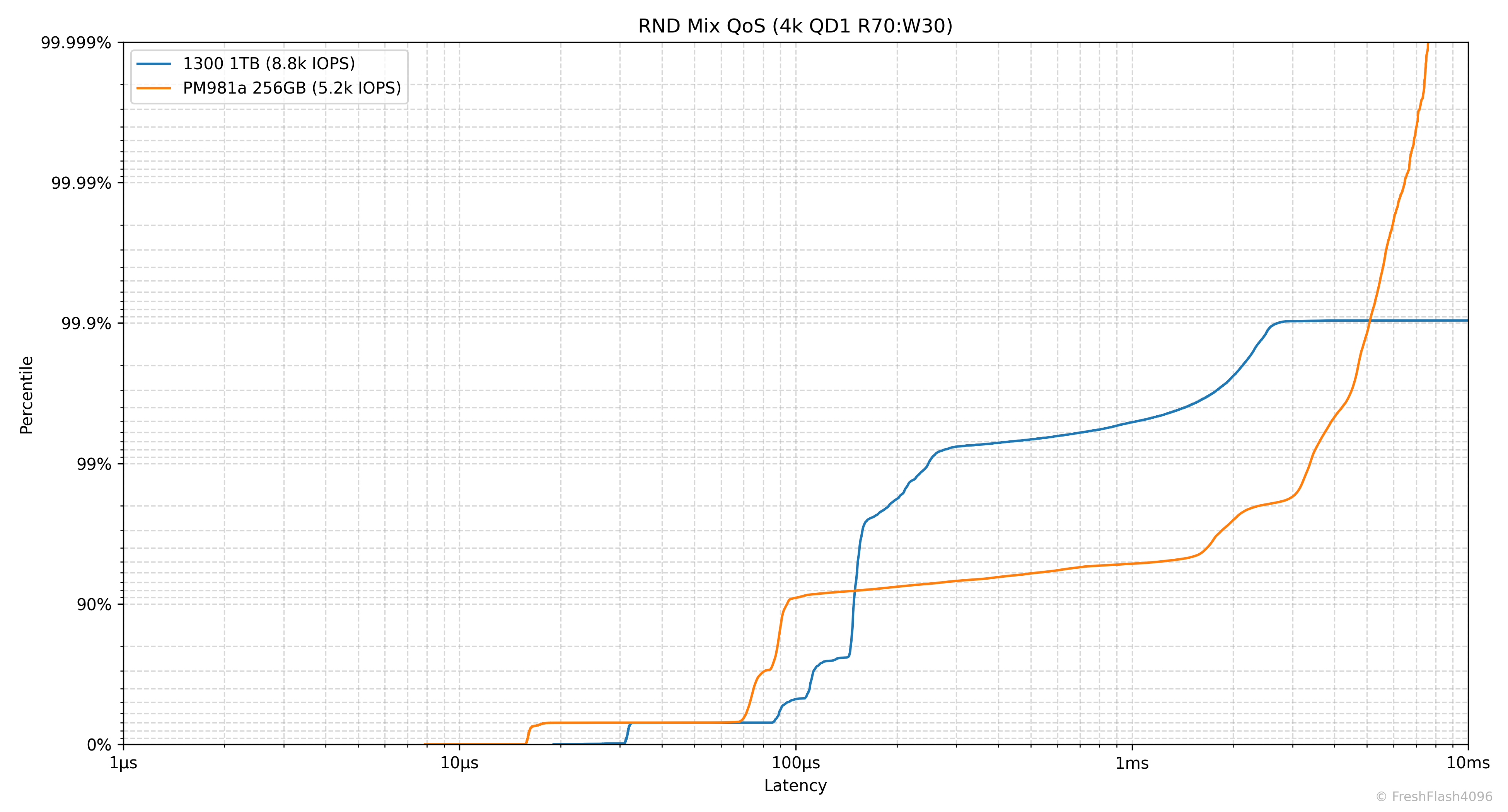
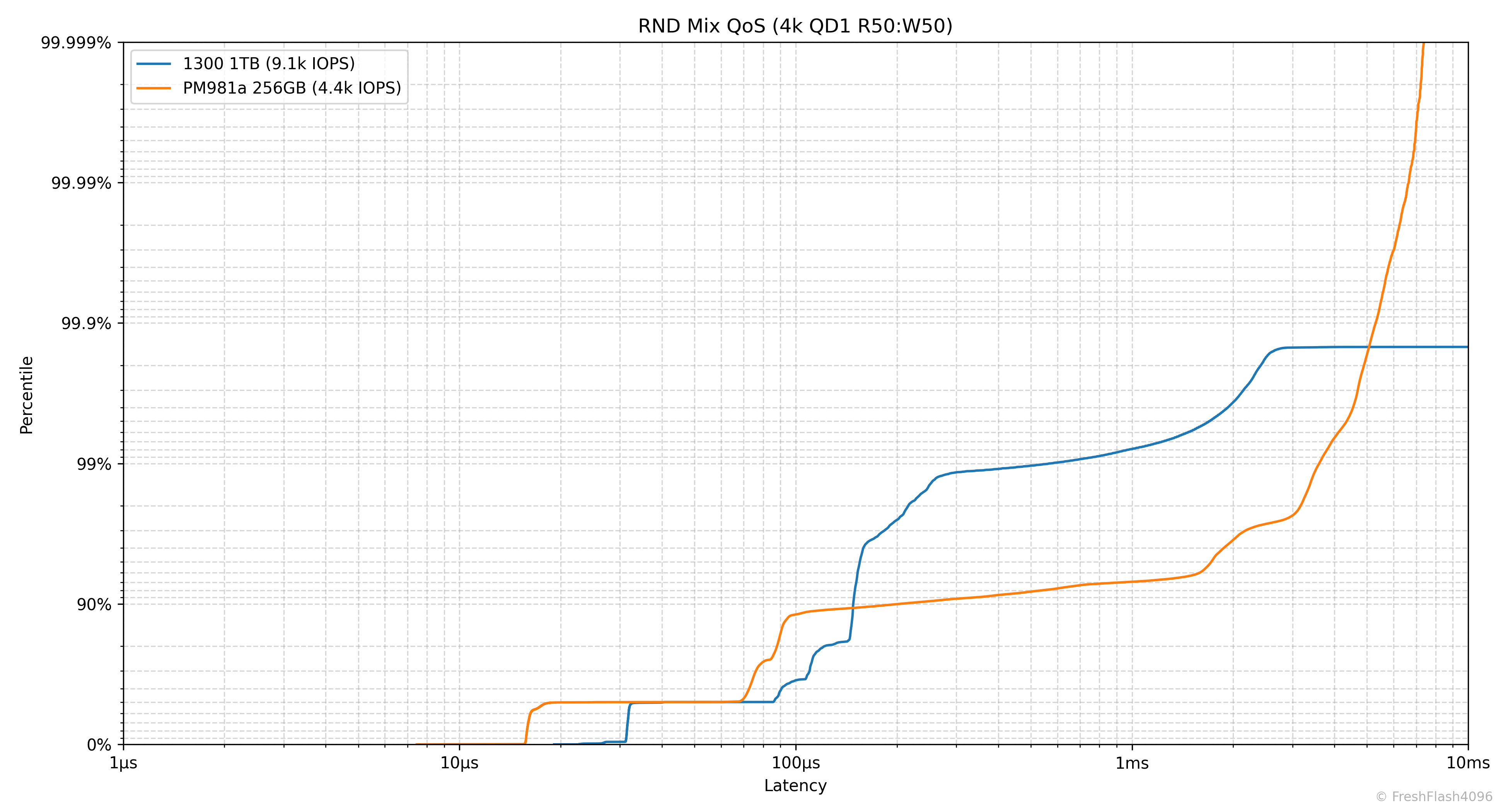
읽기가 아닌, 쓰기나 혼합된 워크로드에 주목해주세요. 99.999%의 QoS에서 PM981a 256GB는 모두 10ms 이하의 지연시간을 보였으나, 1300 1TB는 그렇지 못했습니다. 어지간해서는 99.9%에서 10ms를 초과하는 모습을 보여주네요.
SSD의 성능 측정이 단순히 IOPS의 평균치나 대푯값을 보여주는 것으로 끝나면 안된다는 것을 알려줍니다. 뭐, cSSD의 Steady State 성능이라 관리되지 않는 QoS는 당연하다고 볼 수 있지만요.
| RND Read | Datasheet | Benchmark Result |
| Typical Value [Burst] | 85 µs | 87 µs |
| Typical Value [Steady State] | - µs | 111 µs |
| QoS (99.999%) [Steady State] | - ms | 449 µs |
| RND Write | Datasheet | Benchmark Result |
| Typical Value [Burst] | 40 µs | 32 µs |
| Typical Value [Steady State] | - µs | 44 µs |
| QoS (99.999%) [Steady State] | - ms | 25 ms |
Burst 성능과 Steady State 성능을 한 곳에 모아보았습니다. Burst의 Typical Value는 서로 Span 수치가 다르지만, 어느정도 지켜지는 모습을 확인할 수 있습니다.
앞서말한대로 RND Write에서 Steady State의 Typical Value (50%)는 44µs로 데이터시트의 수치와 극적인 차이가 발생하지 않지만, 99.999%에서는 µs단위가 아닌 ms단위로 측정을 할 필요가 있었습니다.
참고로, 9가 하나 더 늘어난 99.9999%는 이 지연시간이 2배로 늘어납니다.
Closing
이 리뷰를 작성하기 위해 키보드를 잡은 것이 올해 1월 20일이었습니다. 그런데, 결국 마무리와 배포는 3개월이 지난 4월 18일에 하게 되었네요. 다른 리뷰보다 빈약한 설명과 날림 글이었다고 생각됩니다.
앞으로도 제 설명보다는 그래프 위주로 리뷰를 업로드 할 것 같습니다. 밀린 데이터를 다 쳐내고 다시 제자리로 돌아온다면, 그때는 단순한 SSD 리뷰가 아니라 좀 더 생산적인 글을 작성하고 싶네요. 아직 공유하고픈 논문들도 많고요.
이것이 사라져버린 그래프 제작 코드가 적용된 마지막 리뷰입니다. 다음 리뷰는 LLM과 함께 리팩토링을 진행한 코드들의 결과물을 보여드릴 것 같네요. 이번에야말로 쌓인 데이터들을 빠르게 쳐내고 제가 하고 싶은 걸 느긋하게 해보겠습니다.
취업도 해야하고요.
1300은 적절하게 처분할까 고민 중입니다.



Comments