Refresh Benchmark
Change log
2025.11.16 - Performance by RW Ratio/Weighted Graph에서 order graph 정의 수정
2025.11.20 - 일부 오타 수정 및 OCP BootBench ioengine=libaio 명시
2025.11.23 - Performance by RW Ratio 조건 오기입 수정
2025.12.01 - DUT ~ 4-Corners Consistency 단계 추가 및 Fill Drive P99 명칭 수정
2025.12.23 - 하이퍼링크 오류 수정
2026.01.20 - SATA SSD의 테스트에 대한 내용을 전반적으로 추가
부랴부랴 급하게 벤치마크 방법에 대한 글을 썼던 것이 4개월 전입니다. 1년은 된 기분인데 말이죠.
보드의 바이오스 버전도 강제로 바뀌었고, P5800X를 약식으로 테스트한 결과, 벤치마크 방법에 한계가 있다는 것을 인지해 수정을 가했습니다. 이렇게 된 김에 그냥 아예 새로 진행하기로 마음먹었죠. 다만, 여태 올라온 SSD들에 대해서는 다시 게시물을 올리지 않고, 처분하지 않고 남아있는 SSD에 한하여 재측정을 진행해 개인적으로 데이터를 쌓을 생각입니다.
최근 리뷰에선 벤치마크 방법 등에 대해 생략하였는데, 독자가 제 리뷰를 계속해서 읽어온 것이 아닐 확률이 더 높은 만큼, 앞으로는 매 게시물에 간단하게라도 포함하려고 합니다.
그럼, 새롭게 바뀐 벤치마크 방법에 대해서 마음을 잡고 이전보다 더 자세하게 작성하고자 합니다. 약간은 공격적으로 말이죠. 내용이 상당히 많으니 주의해 주세요.
목차
Definitions
- 4-Corners Performance: 스토리지 성능에서 기본적인 4가지 요소를 지칭하며, 순차 읽기, 순차 쓰기, 랜덤 읽기, 랜덤 쓰기를 말합니다.
- BS(Block Size): 한 번의 I/O 작업으로 전송되는 데이터의 크기 단위입니다.
- cSSD(Consumer SSD): 일반 소비자용 SSD를 의미합니다.
- DUT(Device Under Test): 벤치마크나 테스트의 대상이 되는 하드웨어를 의미합니다.
- eSSD(Enterprise SSD): 기업용, 데이터센터용 SSD를 의미합니다.
- FOB (Fresh Out of the Box): 사용하거나 데이터를 기록하기 이전의, 완전한 초기 상태의 SSD를 의미합니다.
- IOPS (I/O Operations per Second): 초당 처리하는 I/O 작업의 수를 의미합니다.
- Logical Block Address (LBA): OS나 파일 시스템이 참조하는 주소로, 논리 장치의 시작 부분으로부터 해당 블록이 포함된 오프셋입니다.
- Purge: FOB 상태로 되돌리는 작업을 의미합니다.
- RND(Random): 무작위적인 접근을 의미합니다.
- R/W(Read/Write): 읽기와 쓰기 작업을 의미합니다.
- QD (Queue Depth): 동시에 처리 중인 I/O 요청의 수이며, 병렬 처리 수준을 의미합니다.
- SEQ(Sequential): 순차적인 접근을 의미합니다.
- Thread: OS나 CPU에 의해 정의된 실행 context입니다. Process, Worker라고도 합니다.
- Thread Count (TC): 테스트에서 지정된 Thread의 수를 의미합니다.
- User Capacity: 파일 시스템이나 OS에서 접근할 수 있는 LBA 범위를 의미합니다. Over-Provisioning이 적용된 용량은 제외됩니다.
Why Storage Benchmark is Hard?
예로부터 컴퓨터는 계층 구조를 취하고 있습니다. 주 기억장치인 Memory 아래에 오는 보조기억 장치의 대표로는 HDD가 있었죠. 지금도 HDD는 계속해서 발전해 나가고 있습니다. 최대 속도를 개선한 Seagate MACH.2를 비롯해 드라이브의 용량 밀도를 증가시키는 HAMR도 있습니다. 용량이라고 하면, 더 많은 플래터를 욱여넣는 것도 하나의 기술이죠. 아, OCP의 NVMe HDD도 상당히 흥미롭습니다.
하지만, 2025년에 보조기억 장치라고 하면 가장 먼저 떠오르는 것은 SSD일 것입니다. 적어도 일반 소비자의 HDD 사용량은 이전에 비해 굉장히 줄었으며, 실제로 사용하지 않는 사람도 많죠. SSD가 보급되기 전에 컴퓨터를 만지던 분들도 HDD만을 사용하던 시대로 돌아가고 싶진 않을 것 같습니다. 저는 SSD가 보급된 이후에 컴퓨터를 만지게 되었지만, HDD에 OS를 설치했던 기억을 떠올리긴 싫네요.
HDD가 기술 발전을 하는 것보다 SSD는 더욱 빠르게 발전하고 있습니다. 데이터 저장에 있어서 주(主)가 되는 NAND는 물론이고, SSD 내부에서 모든 것을 제어하는 컨트롤러를 구성하는 CPU, 펌웨어에 사용되는 알고리즘도 발전합니다. 한데, 이러한 발전이 일반 소비자에게 있어서 눈에 바로 보이진 않습니다. 보이는 것이라고는 스펙 시트에 기재된 최대 속도라고 주장하는 말뿐이죠.
SSD는 외부에서 내부를 알 수 없는 일종의 블랙박스입니다. 이는 성능 측정에 있어 어려움을 초래하죠. 예를 들어, 데이터가 정확히 어느 위치에 저장되어 있는지, SLC 용량이 얼마나 차 있는지 외부에선 알 수 없습니다. 이를 위해 사람들은 인위적으로 I/O를 발생시키는 벤치마크 도구를 사용합니다.
어떤 사람들은 SSD의 내부 구조를 파악하기 위해, 또 다른 사람들은 '실제 속도'를 알기 위해 벤치마크를 시행한다고 합니다. 이 '실제 속도'란 것에 대해서 한번 생각해 봅시다.
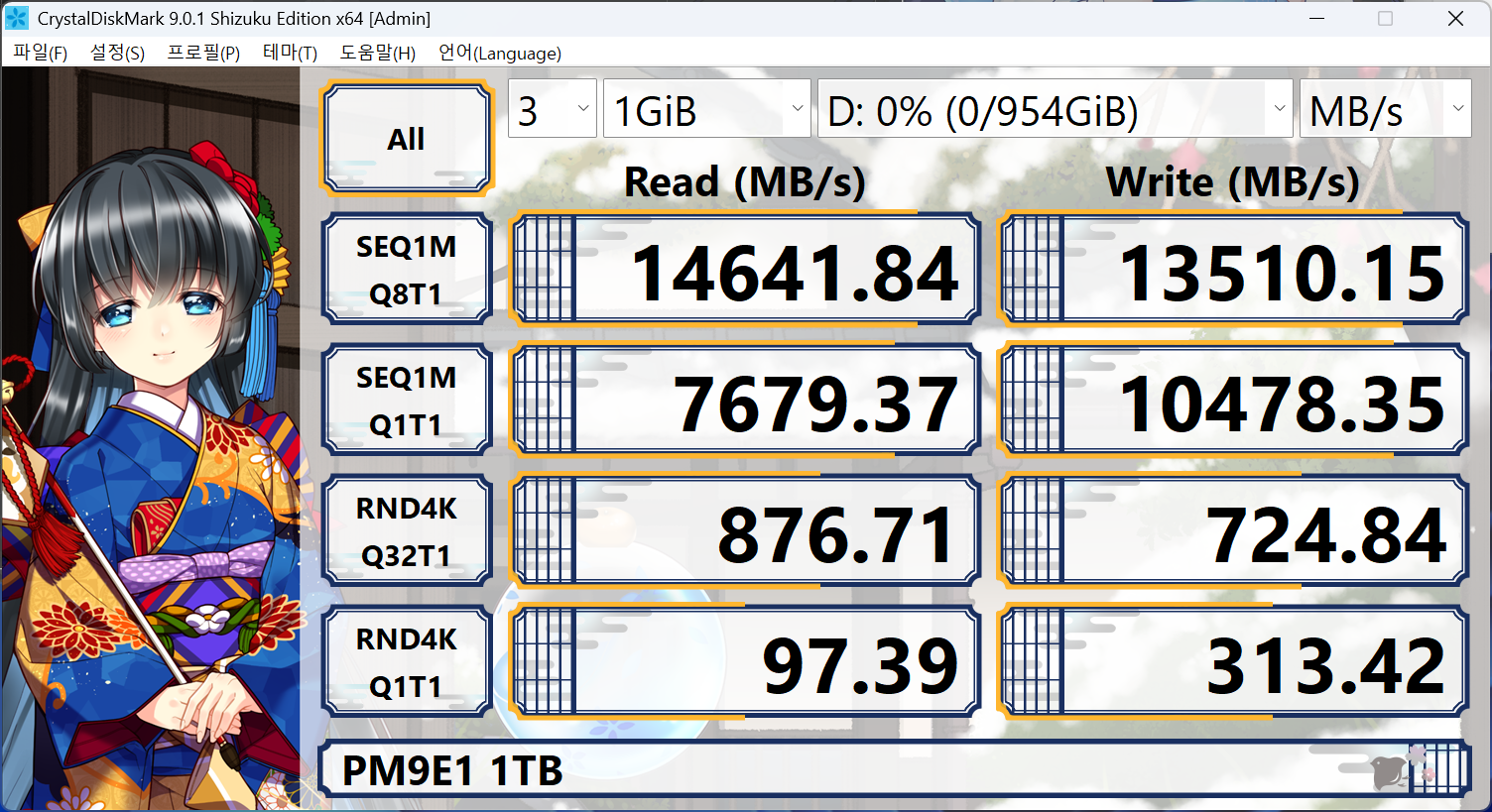
CrystalDiskMark, 흔히 CDM이라고 부르는 이것은 가장 흔하게 볼 수 있는 저장장치 벤치마크 도구입니다. Microsoft의 diskspd를 백엔드로 하여 GUI를 씌운 도구이며, 굉장히 사용하기 편리해 많은 사람이 애용합니다. 드라이브의 성능을 확인하기 아주 좋은 도구 중 하나이기 때문이죠.
그럼, 여기서 최대 성능이 '실제 성능'일까요?
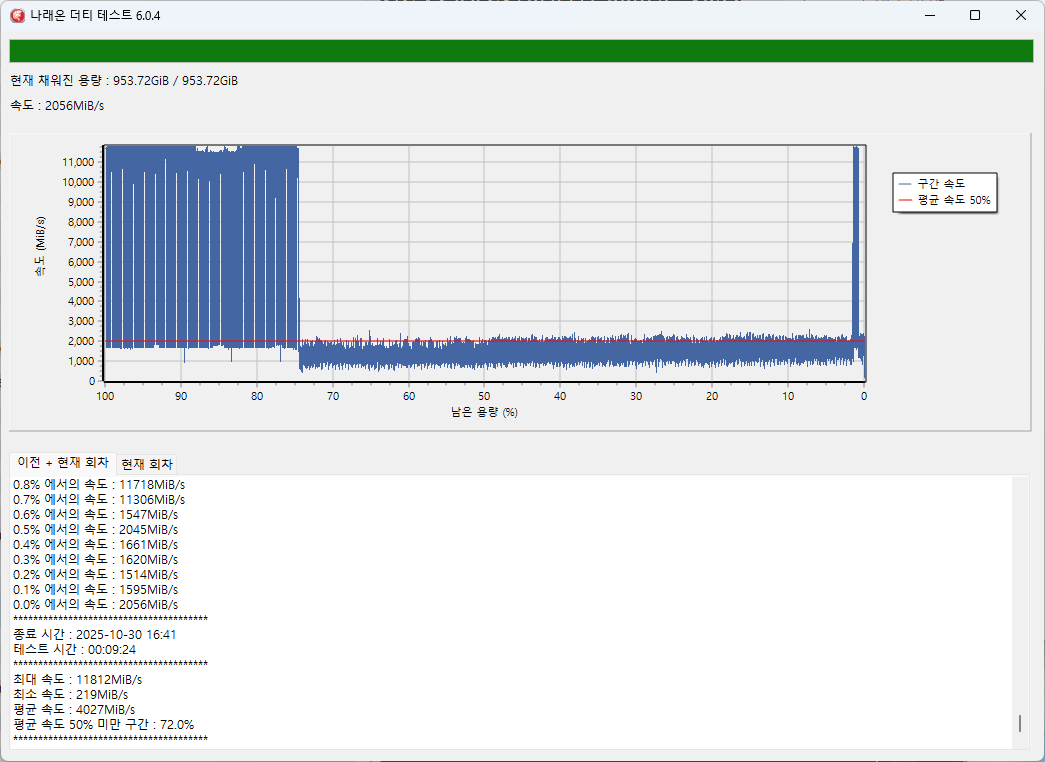
저장장치에 관심이 조금 더 많은 국내 사용자가 사용하는 나래온 더티 테스트라는 도구입니다. 앞에서는 14GB/s에 달하는 최대속도를 보여주었는데, 여기선 앞부분만 그러한 속도에 대응하고 절반 이상은 2GiB/s 주변에서 노는 것을 볼 수 있습니다. SLC 캐시 범위에서 벗어난 쓰기를 진행하기 때문에 발생하는 상황입니다.
그럼, 이 뒷부분에 해당하는 성능이야말로 '실제 성능'일까요?
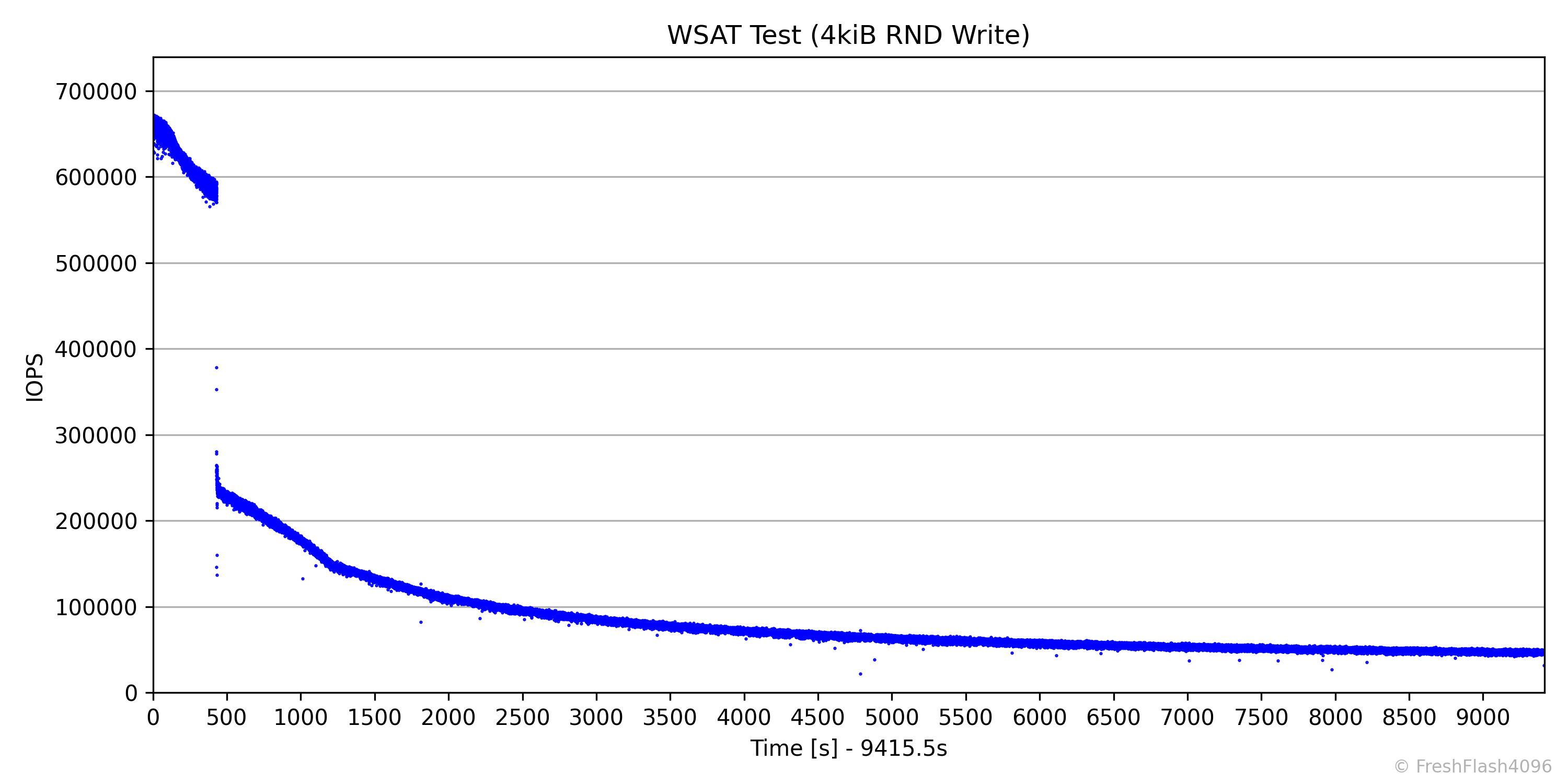
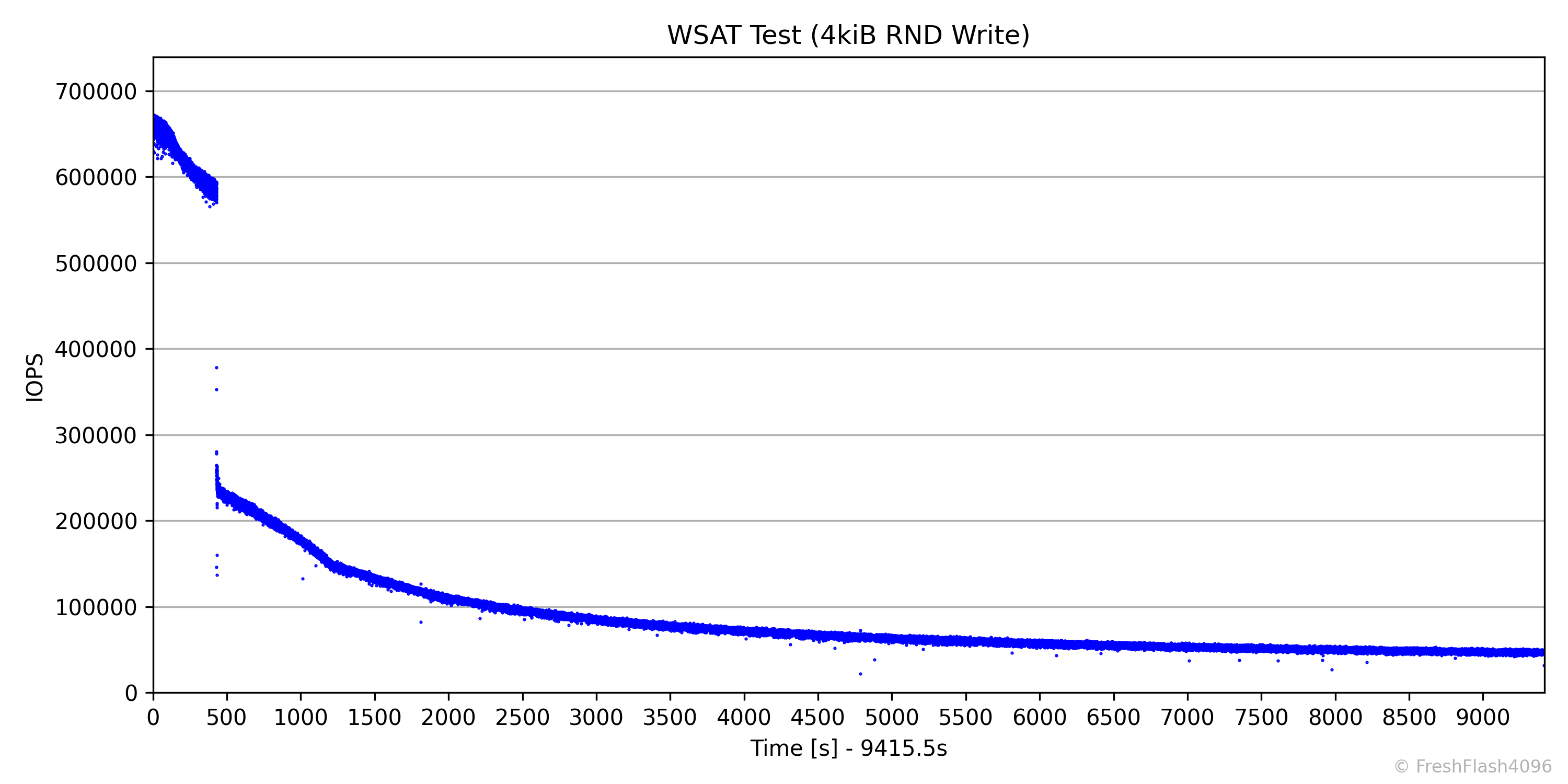
저장장치에 관심을 더 오랫동안 가졌다면, MLC를 사용한 마지막 SSD인 970 PRO에 대해서 들어보셨을 것입니다. MLC라는 이유로 '불변의 성능' 을 보여준다고 말하는 분들이 계시는데, 위는 RND 4k Write를 계속해서 가한 결과입니다. 이 그래프에서 뒤쪽에 위치하는, 속도가 변하지 않는 안정적인 상태를 Steady State라고 합니다.
그럼, 이 Steady State의 성능이 '실제 성능'일까요?
간단하게 몇 가지 케이스만 보여드렸는데도 상당히 고려해야 할 부분이 많은 것이 보일 겁니다. SSD의 성능 테스트는 난도가 높으며, 절대로 쉽지 않습니다. 특히나 '실제 성능'과 보통 같은 의미로 말하는 '체감 성능'을 이야기하기엔 너무 많은 변수를 고려해야 하죠.
너무 힘드네요. SSD 벤치마크에 표준 같은 것은 없나요?
어떠한 것의 기준이 된다고 할 수 있는 표준, Standard. 굉장히 좋은 울림입니다. SNIA(Storage Networking Industry Association)은 SSD를 위한 SSS-PTS, 성능 측정 사양을 냈습니다.
다행이네요. 그럼, 이대로만 하면 SSD의 체감 성능을 알 수 있나요?
아쉽게도 현실은 쉽지 않습니다. SSS-PTS의 내용은 약간의 난도가 있기도 하며, 수행하는 데 시간도 굉장히 오래 걸립니다. 이를 완전히 따라 벤치마크를 진행하는 리뷰어는 제가 아는 한 없습니다. 힌트를 얻어 벤치마크를 진행하는 리뷰어는 소수 존재하지만 말이죠.
더 큰 문제는 SSS-PTS가 Steady State의 성능을 측정한다는 것입니다. Steady State는 말 그대로 변하지 않는 안정적인 상태로, SSD에 있어서는 유사 최악의 상황을 가정합니다. 진정한 의미로 성능을 비교하기엔 알맞겠지만, 일반 소비자의 워크로드와는 상당히 다릅니다.
조금 시각을 바꾸어 봅시다. 체감 성능(體感 性能)이란 무엇일까요? 말 그대로 우리가 느낄 수 있는 성능일 것입니다. 이를 파악하기 위해서는 평상시 우리가 사용하는 SSD에 어떤 부하가 가해지는지 알아야 합니다.
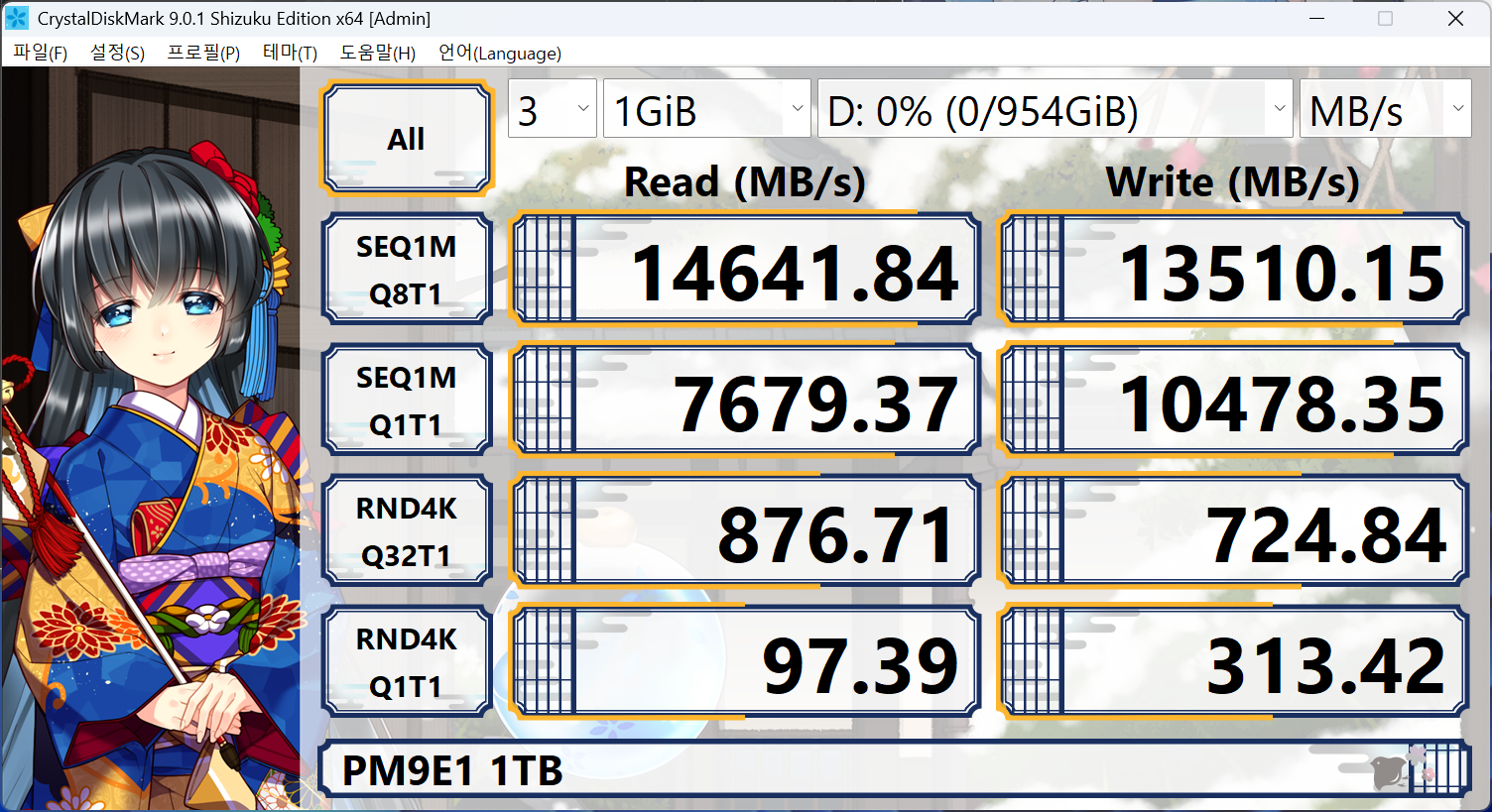
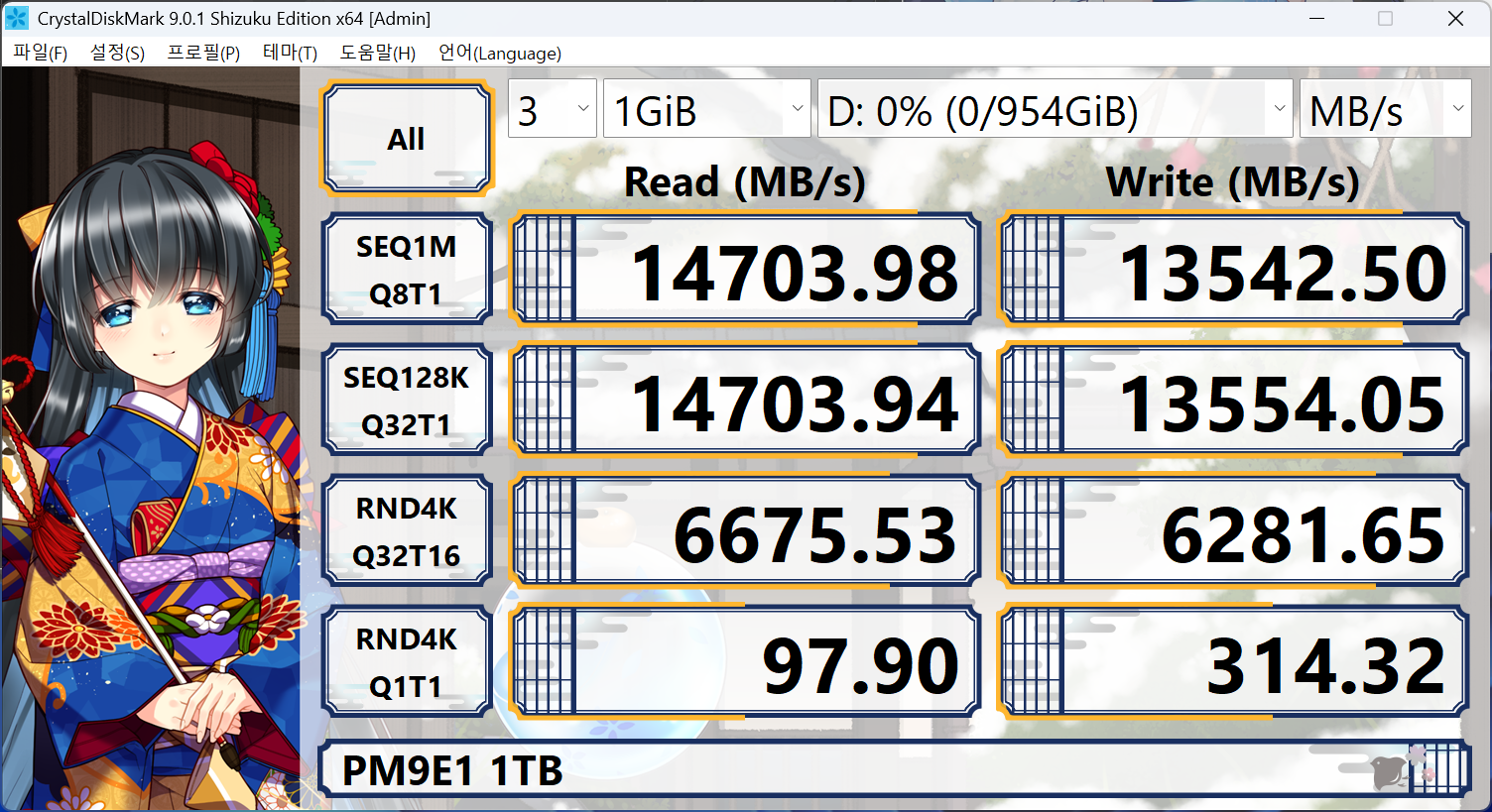
앞서 소개해 드렸던 CrystalDiskMark로 동일한 드라이브를 기본 설정과 NVMe 설정으로 테스트한 것입니다. 동일한 드라이브이지만, 값이 굉장히 들쭉날쭉합니다. 특히, 가장 위와 아래에 해당하는 14000MB/s와 100MB/s는 너무 극단적입니다. 그 외에 좌측과 우측의 프로필을 비교하면, RND 4k는 동일하지만, Q32T1과 Q32T16로 다른 환경임을 가정하고 있다는 것도 알 수 있습니다. 이에 따라서 성능도 상당한 차이를 보이죠.
SSD는 조건에 따라 성능이 천차만별로 변합니다. 거기에 더해 현실 세계에는 굉장히 다양한 부하가 복합적으로 존재합니다. 이것이 SSD 벤치마크에서 체감 성능을 측정하기 어려운 이유죠. 아주 많은, 특히 국내에서 광고를 받고 진행하는 여러 SSD 리뷰는 이러한 고민이 녹아 있다고 생각하긴 힘들었습니다. 그저 유명한 도구를 실행하고, 환경을 통제했다는 언급은 없고, 간단한 온도 측정으로 마무리하는 것이 대부분이었습니다.
... the three leading causes of meaningless or misleading benchmark test results involve the operator. And these are:
#3 - Ignorance
#2 - Errors
#1 - Laziness
SSD 성능 측정에 관심이 많다면 한 번쯤 읽어보셨을 "Lies, Damn Lies And SSD Benchmark Test Result"의 내용 중 일부입니다. 무의미하거나 오해의 소지가 있을 법한 벤치마크 결과에는 크게 3가지의 주요 원인이 있으며, 무지, 오류, 게으름이라고 적나라하게 비판하는 글입니다.
그럼, SSS-PTS나 위 글에서 말하는 것처럼 Steady State에 대한 성능 측정을 개시해야 할까요? 물론, eSSD를 테스트할 때는 이는 절대 뺄 수 없는 과정입니다. 하지만, cSSD에는 다르게 적용되어야 한다고 생각합니다. 워크로드가 달라 가해지는 부하도 다르며, 채용되는 펌웨어의 작동 방식에도 옛날 cSSD와는 큰 차이가 있기 때문입니다. 어렵죠?
약소하지만, 이러한 어려움을 극복하기 위해 어떤 것을 수행하는지, 제 나름대로 고민한 결과를 풀어보고자 합니다.
Hardward Platform

우선 테스트 플랫폼을 소개하고자 합니다. 사진이 좀 못나게 나왔습니다만, 아래의 표를 읽어주시면 좋겠습니다.
| CPU | AMD Ryzen 5 9600X | SMT ON |
| MainBoard | ASUS ROG STRIX B850-I GAMING WIFI | BIOS 1087 |
| RAM | TeamGroup T-create DDR5-5600 CL46 Classic 32GB *2 | JEDEC Std. |
| Boot SSD | Samsung PM981a 256GB *2 | |
| PSU | Corsair SF750 ATX3.1 | |
| Case | Sunmilo H02 | |
| Cooler | Noctua NH-D9L | Full Speed |
| Cooler | Noctua NF-A8 PWM | Full Speed |
| M.2 AIC | ASUS ROG PCIE 5.0 M.2 CARD | |
| U.2 AIC | UMC-PTU-2 | |
| IP-KVM | Sipeed NanoKVM | 1920x1080 |
모든 것은 자기 부담으로 이루어졌습니다. 부품은 물론이고 제가 테스트하는 SSD들도 모두 스스로의 돈이나 지인들의 도움으로 이루어집니다. 그런 면에서 보았을 때, 금전은 상당히 부담되는 요소입니다. Thunderbolt 컨트롤러가 내장된 Intel CPU가 아닌 AMD CPU를 선택한 것도 그러한 이유이며, 상위 등급인 9950X가 아니라 9600X이라는 CPU를 선택한 것도 같은 이유입니다.
OS를 담아놓을 SSD는 2개로, 전면 M.2 슬롯에는 Windows가 설치된 PM981a를, 후면 M.2 슬롯에는 Linux가 설치된 PM981a를 장착합니다. 참고로 두 M.2 슬롯 모두 CPU 직결 슬롯입니다.
DUT가 될 NVMe SSD는 PCIe 5.0 x16을 지원하는 PEG 슬롯에 연결하며, 최대 2-connector Topology까지 허용합니다. CPU와 DUT 사이 물리적인 거리가 멀어지거나 커넥터가 자주 등장할수록 신호의 세기는 약해지기 때문입니다. 실제로 3-connector Topology부터는 최신 기술의 적용에 있어서 슬슬 무리가 있죠.
M.2 NVMe 드라이브의 경우에는 Z790 APEX에 동봉되는 ASUS ROG PCIE 5.0 M.2 CARD를, 2.5" NVMe 드라이브의 경우에는 UMC-PTU-2를 이용합니다. 돈도 없는데 Z790 APEX를 어디서 구했냐 하면, 해당 부품만 중고로 구매했습니다.
SATA SSD는 PROM21(B850 Chipset)에 내장된 SATA 컨트롤러에 의존해 SATA6G_1 포트에 장착합니다. SAS SSD를 테스트할 일이 생긴다면, HBA를 구매해 SATA / SAS SSD의 테스트 방법을 통일할까, 생각도 하고 있습니다.
별도의 언급이 없는 이상, SSD에 전력 제한은 시행하지 않으며, 과열로 인한 성능 제한을 방지하기 위해 Noctua NF-A8 PWM으로 직접 냉각을 진행합니다.
이외에, ASPM(Active-State Power Management)과 관련된 옵션은 BIOS에서 모두 껐으며, SMT(Simultaneous Multithreading)는 켜두었습니다. 예상할 수 있고 일관된 결과를 얻기 위해서 SMT나 Hyper-Threading은 끄는 것이 권장되지만, SMT를 끈 9600X로는 QD가 높은 상황에서 모든 성능을 못 끌어내는 상황을 발견했기 때문에 어쩔 수 없이 SMT를 통해 CPU의 성능을 보완합니다.
Software Platform
Windows
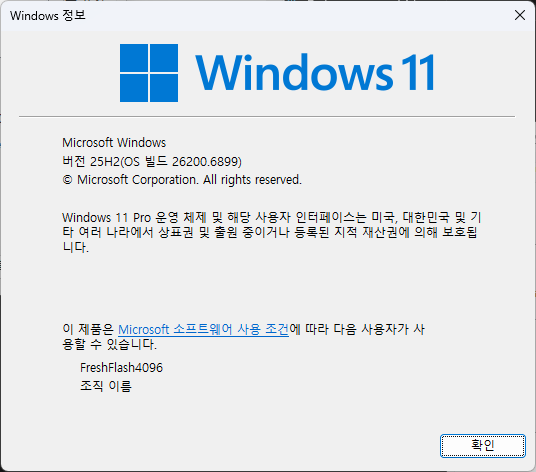
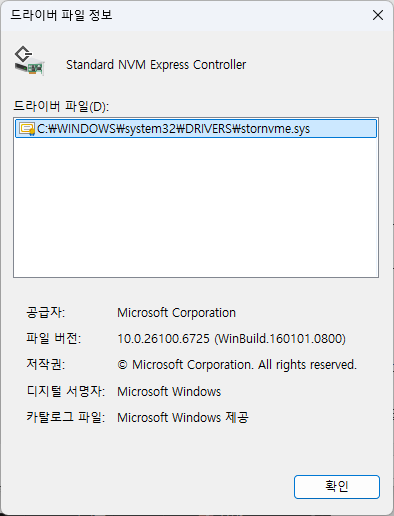
Microsoft Windows 11 25H2(26200.6899)와 기본 Inbox Driver(stornvme.sys 10.0.26100.6725)를 사용합니다. SATA 드라이브에서 적용될 수 있는 Chipset 드라이버의 버전은 7.06.24.2226입니다. 현재 Windows에서는 NVMe Stack을 완전히 Redesign하고 있지만, 아직 제한적으로 사용할 수 있는 상황이기에 실제 리뷰에는 25H2를 사용합니다.
전원 옵션은 고성능으로 설정하고, Indexing Service, Scheduled Defragmentation, System Protection, Windows Defender, Windows Updates를 비활성화했습니다. 혹시 모를 백그라운드 작업에 대비해 네트워크는 연결하지 않습니다.
start /wait Rundll32.exe advapi32.dll/ProcessIdleTasksWindows Defender의 실시간 보호 기능을 끄고, SSD에 대한 정보와 CPU 온도에 대한 모니터링만 활성화한 HWiNFO(v8.34-5870)과 작업관리자를 실행시킨 뒤, 위 명령어를 입력하고 15분 뒤를 IDLE 상태로 정의해 벤치마크를 진행합니다. 또한, DUT는 NTFS의 기본값으로 설정하여 벤치마크를 진행합니다.
Linux
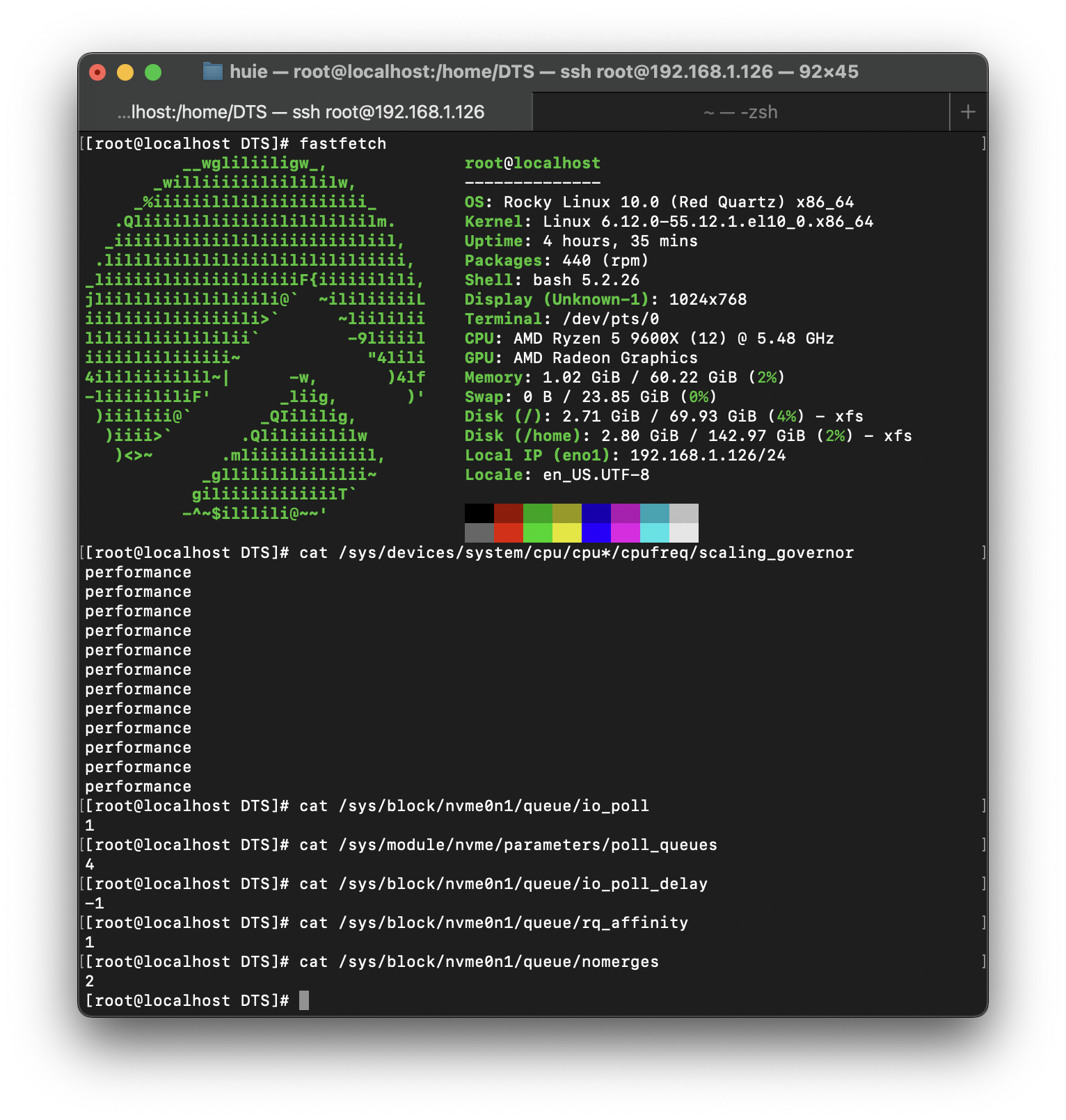
지금 이 시점에서 Linux가 Windows보다 스토리지 벤치마크에서 더 투명하고 고성능을 낼 수 있다는 것에 대해서는 반박의 여지가 없을 것이라고 생각합니다. Rocky Linux 10을 Minimal 옵션으로 설치하였으며, 커널 버전은 6.12.0-55.12.1.el10_0입니다.
CPU governor은 performance로 설정, SSD에 대해서는 I/O Polling을 활성화하고 Polling Queue는 4, I/O 요청을 한 CPU 코어와 동일한 그룹의 CPU 코어에서 I/O를 완료하게 설정, 드라이브의 블록 계층에서 request merging을 비활성화했습니다.
Interrupt vs Polling?
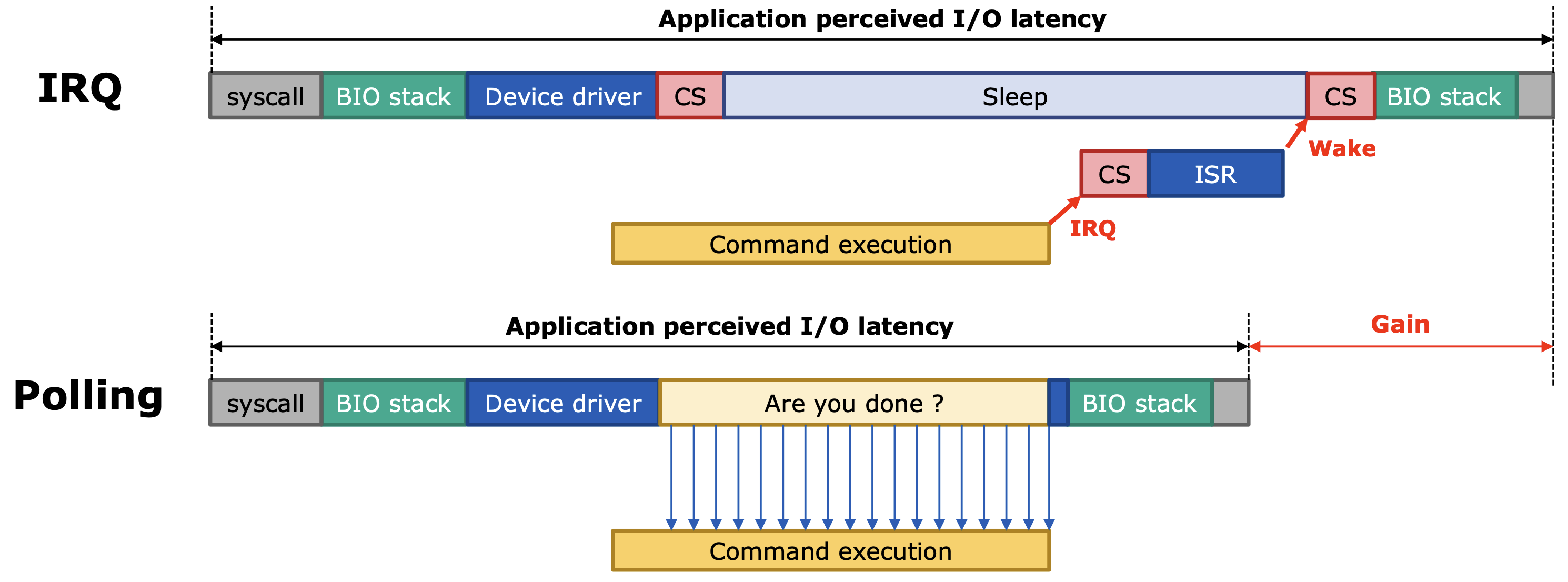
인터럽트(Interrupt, IRQ)와 폴링(Polling)의 차이는 위 이미지를 참고하면 직관적으로 이해가 될 것 같습니다. 인터럽트는 명령이 완료되면 IRQ handler가 CPU를 호출하며, 폴링은 CPU가 직접 명령이 완료되었는지 주기적으로 확인합니다.
기존에 임베디드 수업 등을 통해 IRQ나 Polling을 알고 계신 분이라면 조금 인상이 달라질 수도 있겠네요. 보통은 Polling이 CPU가 확인하는 주기 때문에 더 느린 경우가 많다고 들으셨을 것 같습니다. 실제로 저도 며칠전에 동일한 내용으로 수업을 들었고요. 하지만 최신 시스템에서의 NVMe SSD는 위와 같이 Polling으로 얻는 이득이 더 큽니다.
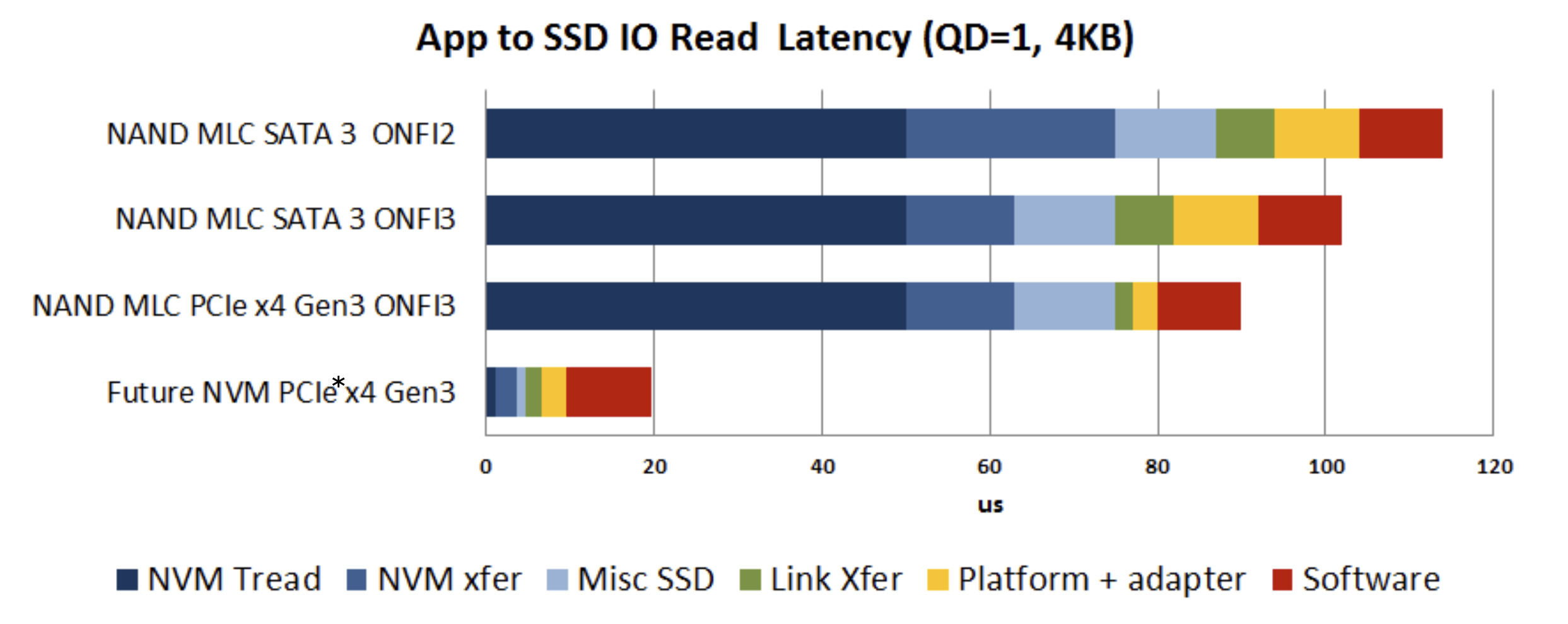
SCM(Storage Class Memory)를 목표로 하는 SSD들을 살펴보면, 전체 지연시간에서 SSD 장치의 비중이 줄어들고, SW가 처리하는 인터럽트와 같은 지연시간의 비중이 많이 늘어나게 됩니다. Optane SSD와 Optane PMEM의 성능 차이도 대부분이 SW로 인해 발생하는 것을 생각하면 영향이 상당하다는 것을 파악할 수 있을 것입니다.
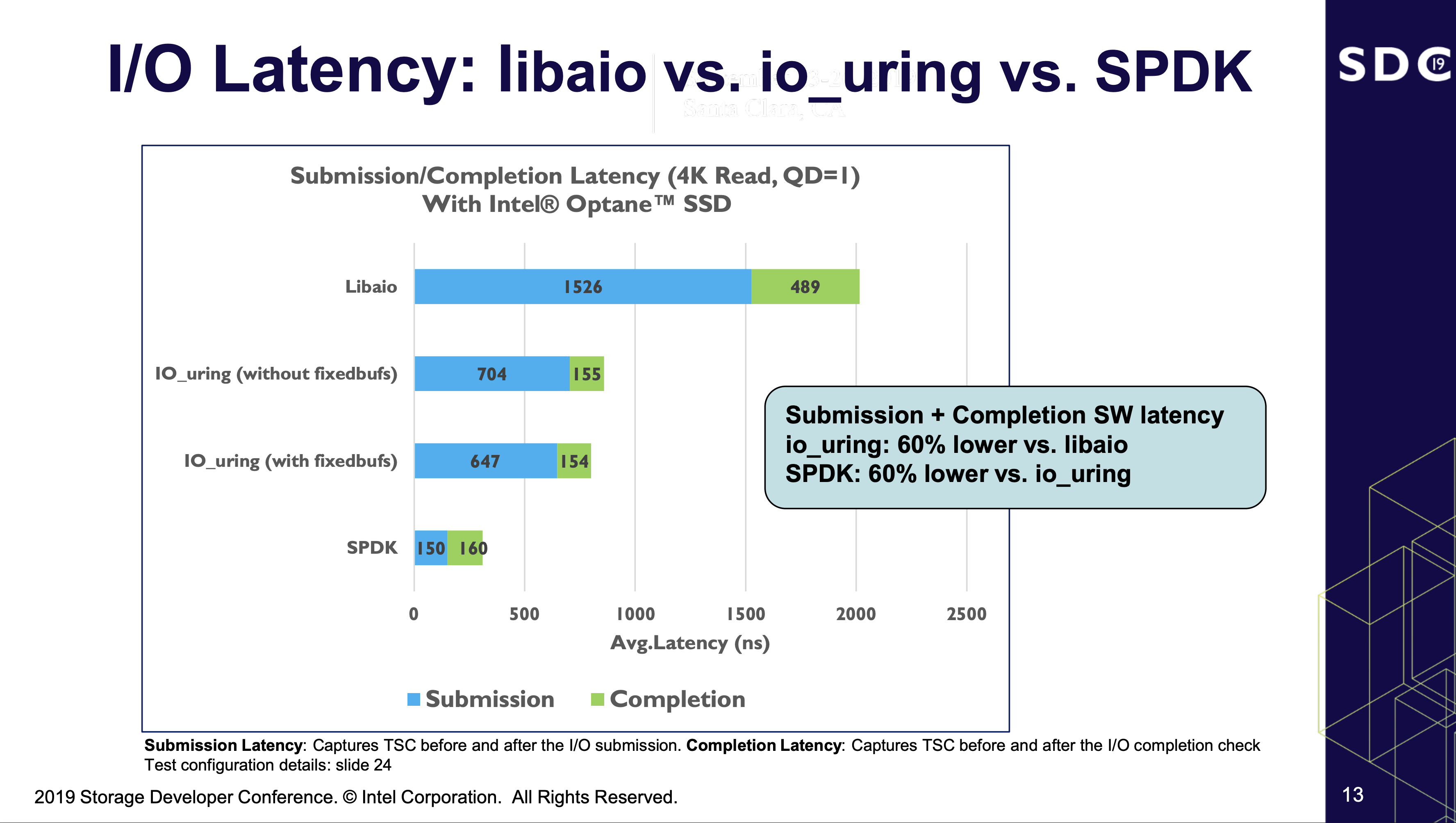
그래서 저는 폴링을 활용하기로 했습니다. SSD의 최대 성능을 확인하기 위해서 말이죠. 이를 위해서는 기존에 Linux 기반의 벤치마크에서 자주 활용되는 Libaio가 아닌, IO_uring이라는 비동기 I/O 엔진을 활용합니다.
IO_uring이나 Libaio의 작동 방식에 대해서는 제 지식이 얕기도 하며, 이 글에 녹여내는 것은 글이 너무 길어질 것 같아 생략합니다. 간단하게 말하자면 IO_uring은 Libaio에 비해 System Call을 획기적으로 줄여 오버헤드를 줄일 수 있습니다. 폴링도 지원하고 말이죠.
FIO (Flexible I/O Tester) 3.41
FIO는 이름처럼 굉장히 유연하고 강력한 벤치마크 도구입니다. 개인적으로는 제대로 된 SSD 리뷰라면, 성능 측정을 할 때 반드시 사용될 도구라고 생각합니다.
테스트 유형별로 달라지는 Queue Depth나 Block Size와 같은 기본적인 옵션을 제외하고 제가 사용하는 것 중에서도 핵심적인 매개변수를 소개하고자 합니다.
| direct=1 | non-buffered I/O를 수행합니다. |
| ioengine=io_uring | 앞서 말했던 io_uring입니다. |
| sqthread_poll=1 | I/O submit은 커널의 polling thread에서 수행됩니다. |
| hipri=1 | polled I/O completion을 시도합니다. (SATA SSD는 제외) |
| registerfiles=1 | 사용하는 파일들을 커널에 등록합니다. |
| fixedbufs=1 | I/O가 시작되기 전에 페이지를 미리 mapping 합니다. |
제가 사용하는 것 이외에도 FIO에는 매우 많은 옵션이 있습니다. 관심이 있으신 분들은 문서를 한 번 읽어보시는 것도 추천해 드립니다.
제 벤치마크는 Windows에서만 사용할 수 있는 특정 프로그램을 제외하면, 모든 것이 Linux에서 FIO를 통해 이루어집니다. FIO는 패키지 관리자를 통해 설치할 수 있는 버전이 낮아 소스코드를 받고 빌드했습니다. 빌드에 사용된 GCC의 버전은 14.2.1 20250110 (Red Hat 14.2.1-7)입니다.
cSSD Benchmarking
그럼, cSSD 벤치마크 방법부터 제시해 보겠습니다.
// NVMe SSD
sudo nvme format -f /dev/nvmeXn1
// SATA SSD
sudo hdparm --user-master u --security-set-pass p /dev/sdX
sudo hdparm --user-master u --security-erase p /dev/sdX
Purge는 위 명령어를 이용해 Linux에서 수행하고 휴식 시간을 부여한 뒤, 아무것도 기록되지 않은 FOB 상태로 진입합니다. 간혹 제조사 도구를 이용해서 Purge를 수행하는 경우도 있으나, 그러한 경우에는 직접 명시합니다.
01. Linux Boot
02. Purge
03. Fill Drive
04. Performance by Active Range
05. Pre-Conditioning
06. Sync Write
07. Performance by RW Ratio
08. SLC Cache Reclaim
09. Purge
10. Windows Boot + IDLE State
11. CDM, 3DMark, SPEC
12. 75% Fill
13. 3DMark, SPEC
cSSD의 테스트 과정은 위와 같습니다. 리뷰 순서와 약간은 다른 것을 확인할 수 있습니다. 모든 단계 사이에는 최소 5분부터 최대 15분까지 충분한 휴식 시간이 부여 되며, SSD에 따라 일부 테스트는 제외됩니다. 예를 들어, 고용량의 eSSD는 SLC Cache Reclaim 같은 테스트를 진행할 의미가 없고 시간과 전기와 수명만 소모될 뿐이니 제외합니다.
CrystalDiskMark 9.0.1
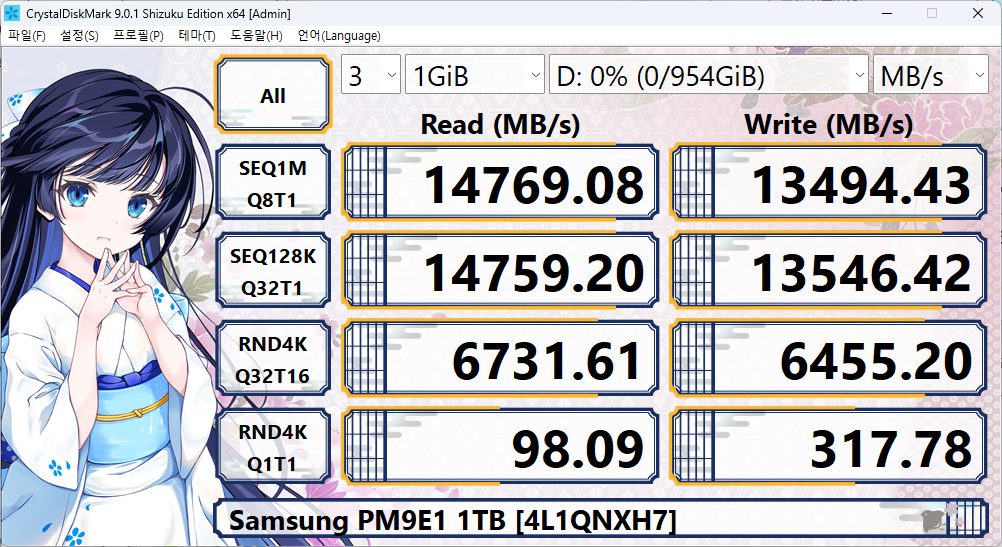
시작은 무난하게 가장 대중적인 도구인 CrystalDiskMark입니다. 앞에서 말씀드린 대로, diskspd를 백엔드로 하여 간단한 사용을 위해 GUI가 씌워진 도구입니다. 국내외로 많은 사람들이 이 도구를 사용하며, 핵심이 되는 옵션을 쉽게 변경할 수 있습니다.
저는 FOB 상태에서만 이 도구를 사용하여 성능을 측정하고, 높은 QD로 설정되어 있는 NVMe 설정으로 진행합니다. 그 외의 옵션은 기본값입니다.
신경 쓰이는 부분이 있는 경우에는 간단하게 보여드리기 위해, 일부 옵션을 조정해 추가로 테스트를 진행합니다.
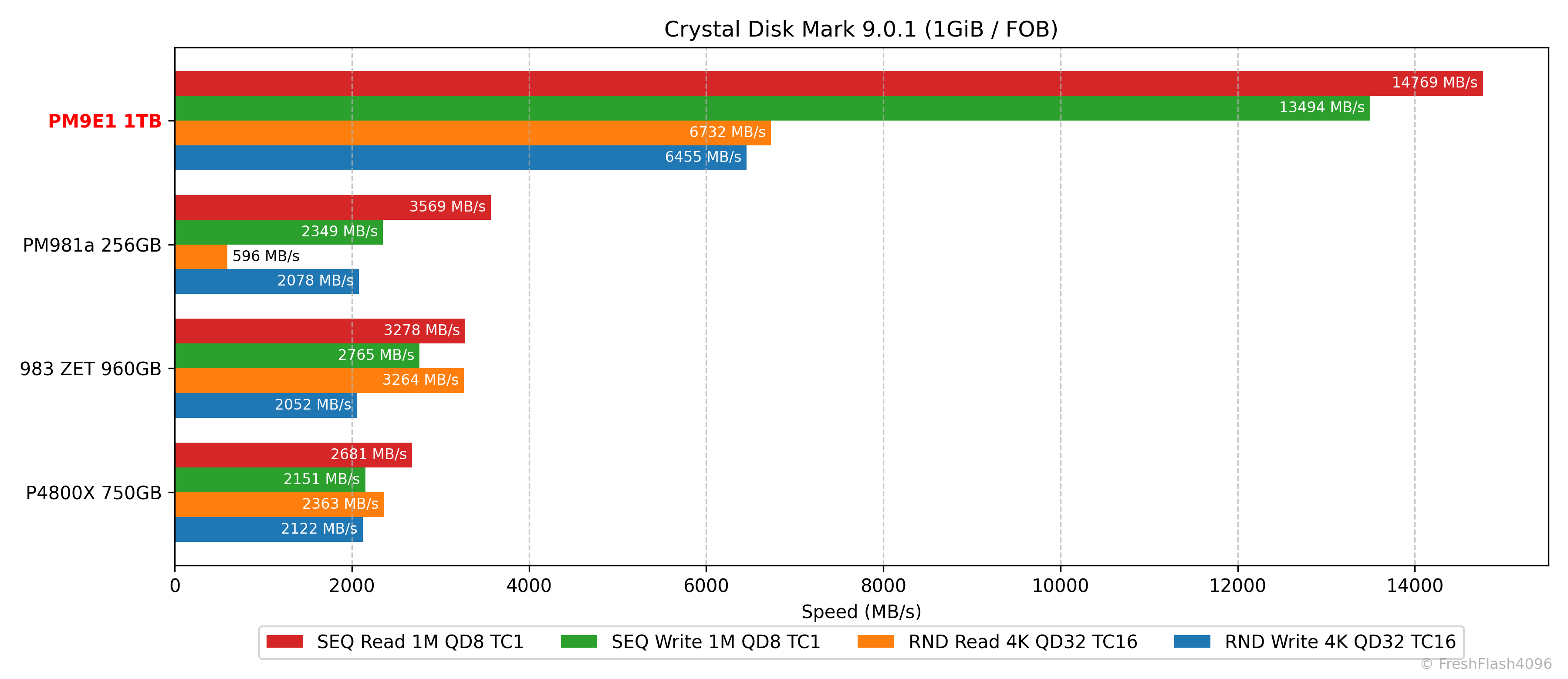

그래프는 SEQ 128k QD32를 제외하고 SEQ Read를 기준으로 비교군을 내림차순 정렬해 제시합니다. RND 4k QD1 성능은 다른 항목들에 비해 성능이 굉장히 낮기 때문에 별도로 제시하는데, 이때의 기준은 읽기입니다.
3DMark Storage Benchmark
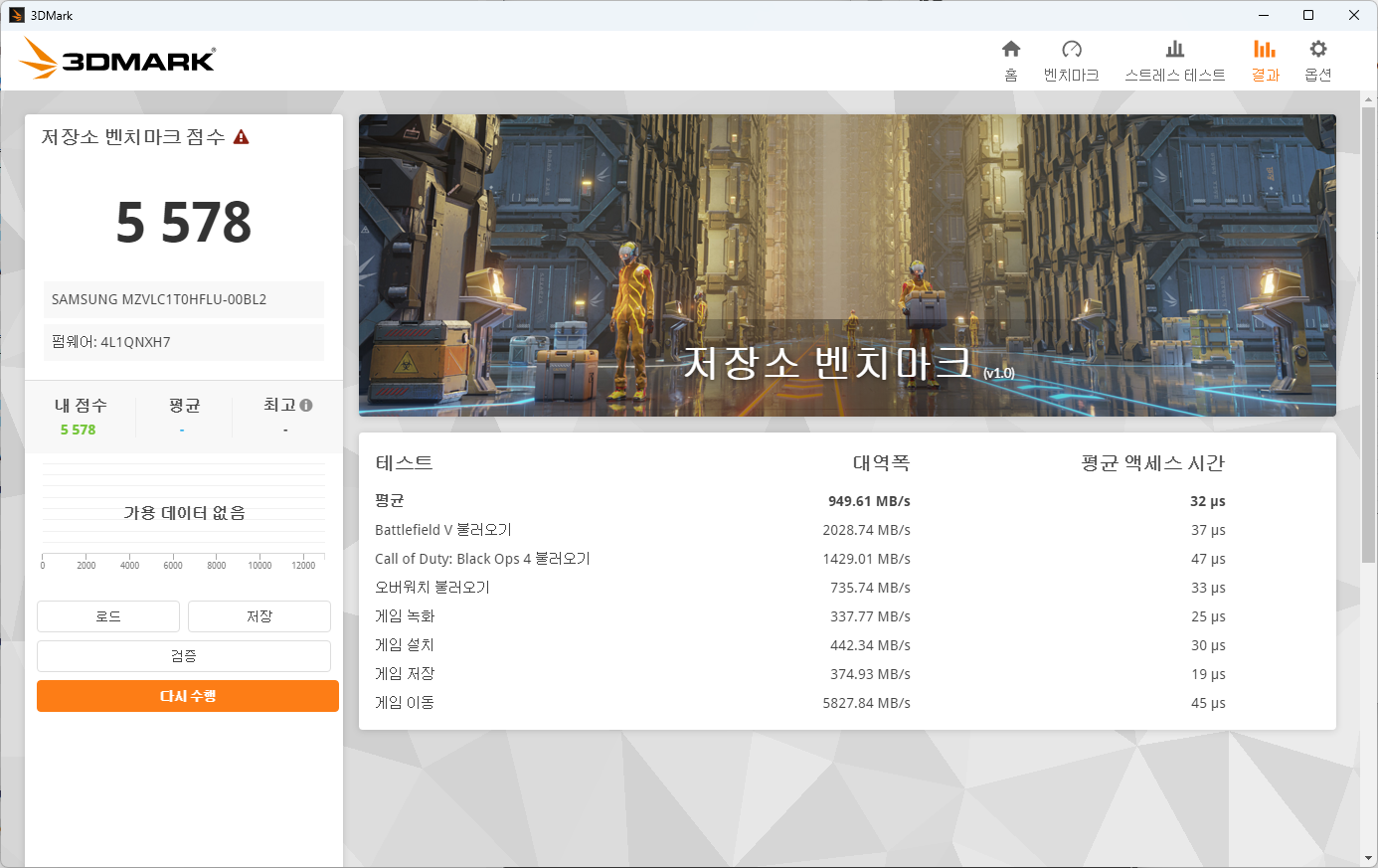
CPU, GPU의 게이밍 성능을 측정하는 3DMark에서 스토리지 벤치마크로 나온 DLC이며, 아래와 같은 항목을 테스트합니다.
- Battlefield V, Call of Duty Black Ops 4, Overwatch의 로딩
- Counter Strike의 이동
- OBS를 통한 Overwatch의 1080p 60FPS 녹화
- The Outer Worlds의 설치 및 저장
최종 점수는 Bandwidth와 Average Access Time을 통해 계산됩니다. 점수 산출의 기준은 아주 어렵지 않으므로 공식 문서를 참고하시기 바랍니다.
게이머들에게 DirectStorage 기능이 주목받고 있다는 얘기를 들었으나, 저는 별도의 dGPU를 가지고 있지 않아 DirectStorage와 GDeflate 기능을 원활하게 시연하기가 힘듭니다. 엔비디아 dGPU가 있다면 벤치마크 항목에 본격적으로 GDSIO를 추가할 수도 있겠지만, 컴퓨터 게임도 하지 않는 제가 SSD 리뷰를 하자고 GPU를 구매하는건... 손이 가지 않더라고요.
아무튼, 3DMark는 CDM의 성능측정을 마치고 5분의 휴식 시간을 부여한 뒤 진행하며, 드라이브를 75%까지 채우고 한 번 더 진행합니다. 이때, 드라이브를 채우는 것은 SEQ 1M QD8 Write 워크로드입니다. 0%와 75%가 채워졌을 때, 두 결과 간 차이가 10% 이내라면 더 큰 값만 제시합니다.
추가로, 대부분의 eSSD에서는 75%가 채워지기 전과 후의 차이가 존재하지 않기에 75%를 채운 뒤의 테스트는 수행하지 않습니다.
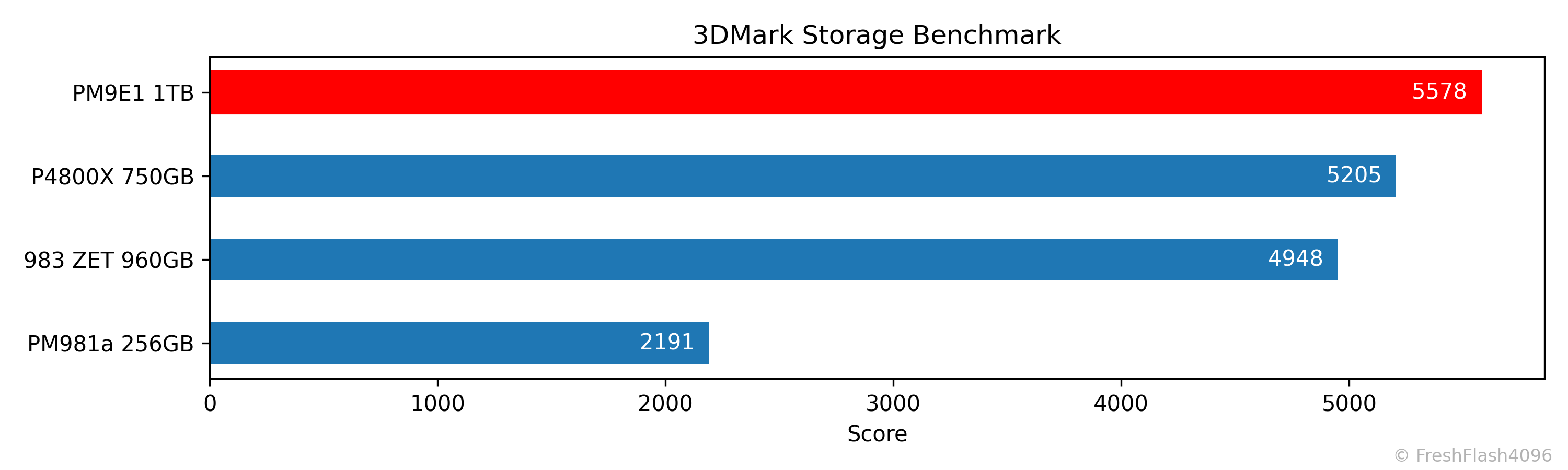
3DMark의 결과는 별도로 제시하지 않으며, 점수만을 기준으로 비교군을 내림차순으로 정렬해 그래프로 출력합니다.
SPECworkstation 4.0 - WPCstorage
약간은 생소할 수도 있는 벤치마크 도구입니다. CPU의 성능을 측정하는 SPEC CPU는 들어보셨다면 조금은 낯설지 않을 수도 있겠습니다. SPEC CPU와 동일하게 SPEC(Standard Performance Evaluation Corporation)에서 워크스테이션의 성능 지표를 측정하기 위해 만들어진 벤치마크 모음집이며, 그중 WPCstorage는 여러 워크로드에 따른 스토리지의 성능을 측정합니다. 워크로드의 종류는 아래와 같습니다.
| 3dsmax | Autodesk 3ds Max의 I/O |
| 7zip | 7-Zip을 통한 압축 및 해제에서 발생하는 I/O |
| ccx | CalculiX CCX의 I/O (유한 요소 해석) |
| cfd | openFOAM의 I/O (유체 역학) |
| energy | OpendTect의 I/O (지진) |
| handbreak | 비디오 트랜스코딩에서 발생하는 I/O |
| icePack | Ansys Icepak의 I/O |
| maya | Autodesk Maya의 I/O (SPECapc for Maya) |
| MayaVenice | Autodesk Maya의 I/O (대용량 장면 로딩) |
| MandE | Adobe Premiere Pro, Blender 등 다양한 미디어 앱의 I/O |
| mcad | Ansys Mechanical, Autodesk Revit, SOLIDWORKS등 다양한 CAD I/O |
| mozillaVS | Microsoft Visual Studio에서 Mozilla Firefox를 컴파일할 때 발생하는 I/O |
| namd | NAMD의 I/O (분자 동역학) |
| proddev | PTC Creo, Siemens NX 등 다양한 설계 및 개발 앱의 I/O |
결과는 Reference Machine(i7-12700, M.2 NVMe 512GB)에 대한 비율로 출력됩니다.
3DMark를 마치고 5분의 휴식 시간을 부여한 뒤 진행하며, 드라이브를 75%까지 채우고 한 번 더 진행합니다. 제시하는 정보에 대한 조건은 3DMark와 동일합니다.
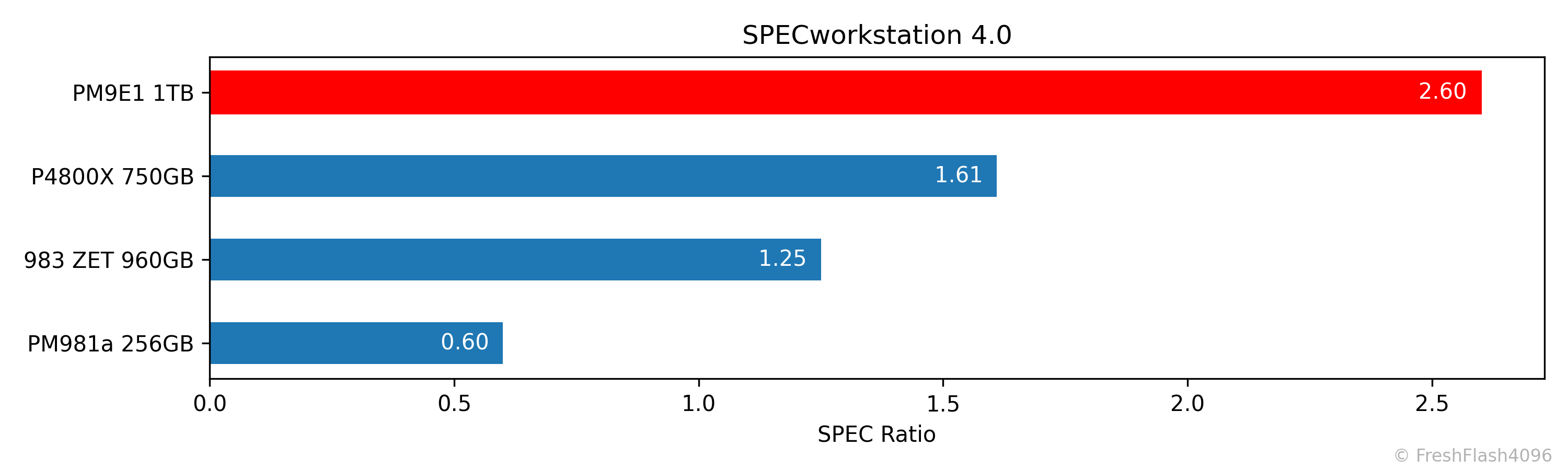
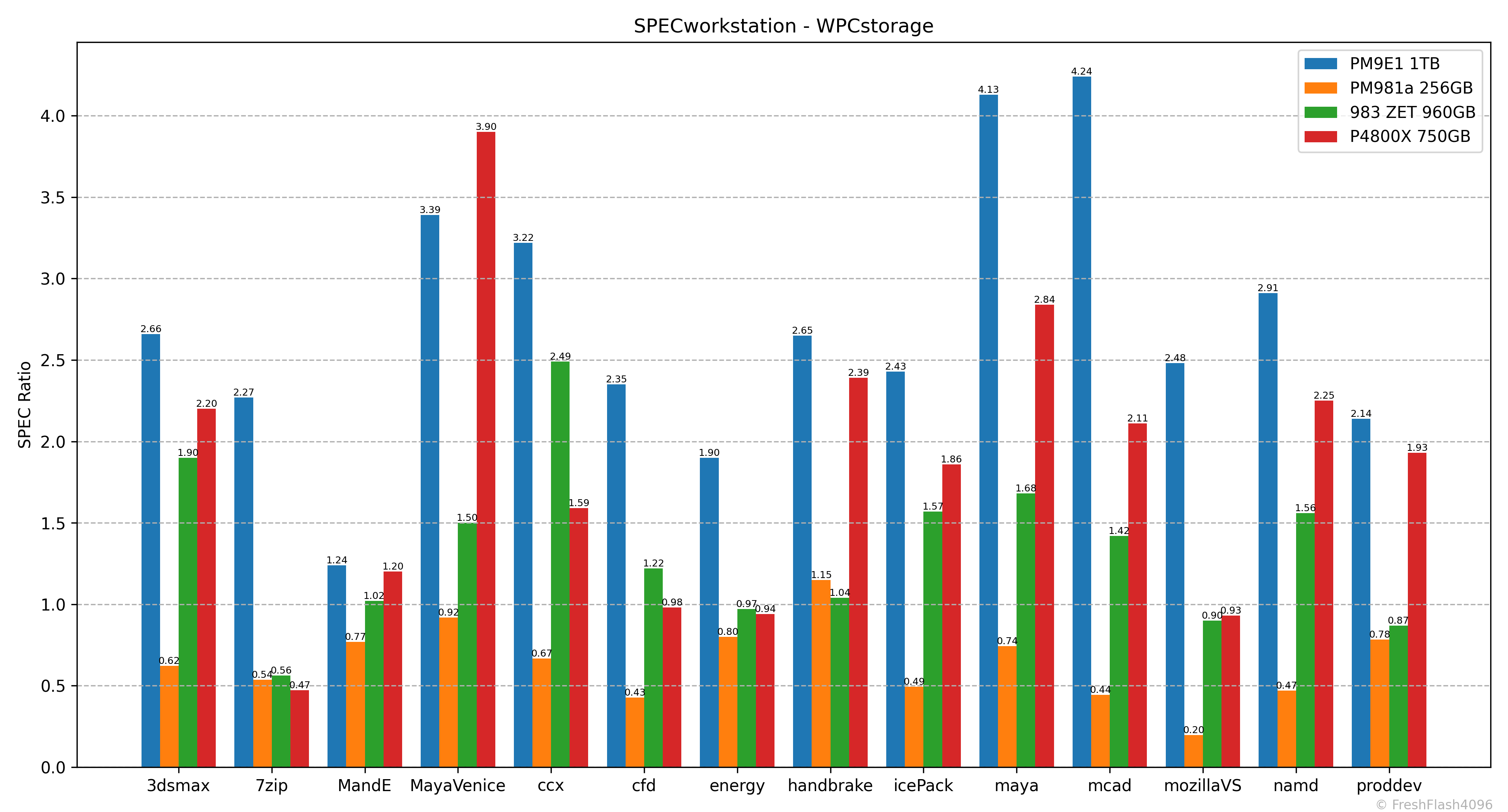
SPEC Ratio를 기준으로, 내림차순으로 정렬해 제시하며, 개별 워크로드에 대한 SPEC Ratio도 별도의 그래프로 제시합니다.
Fill Drive
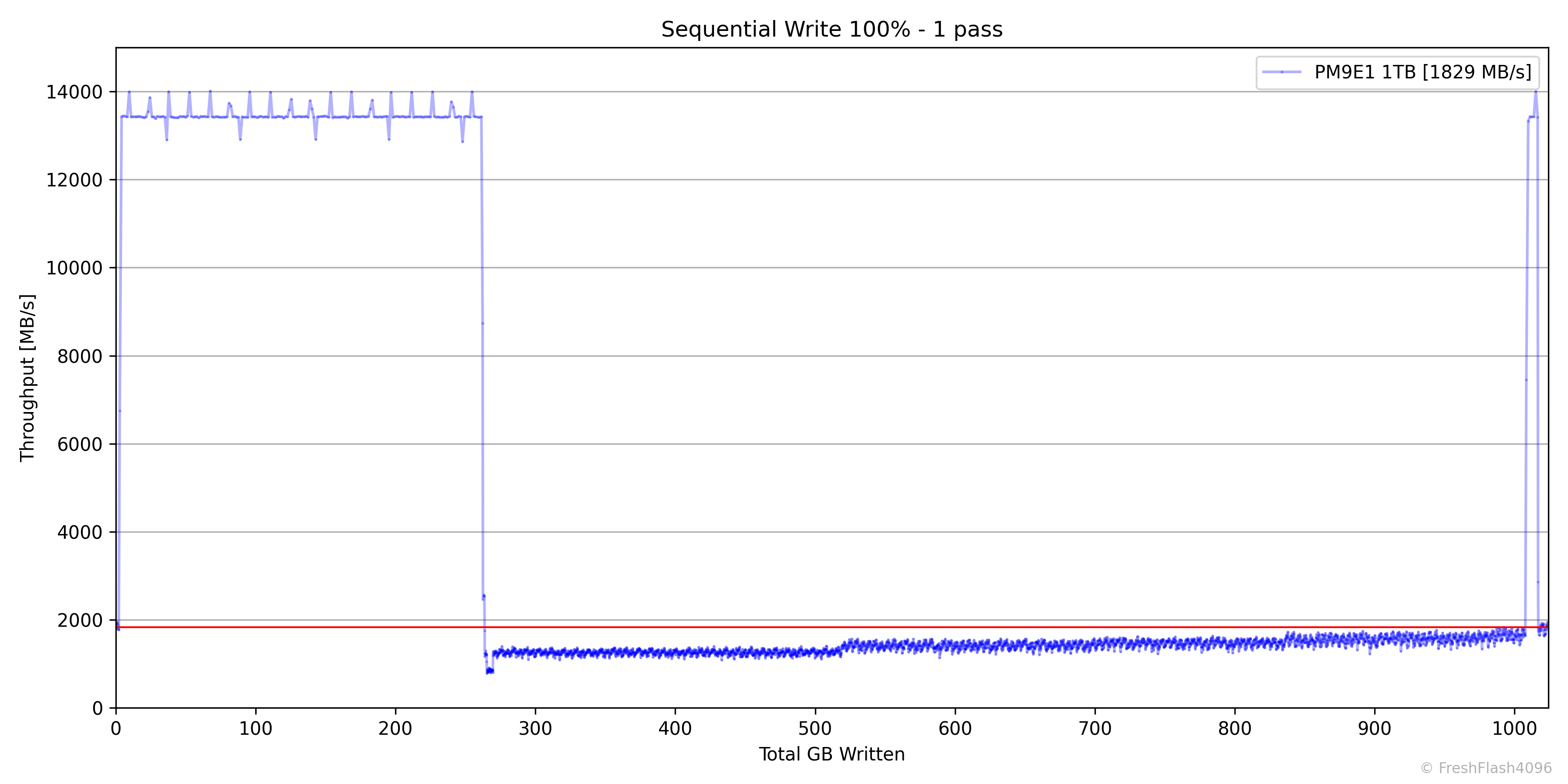
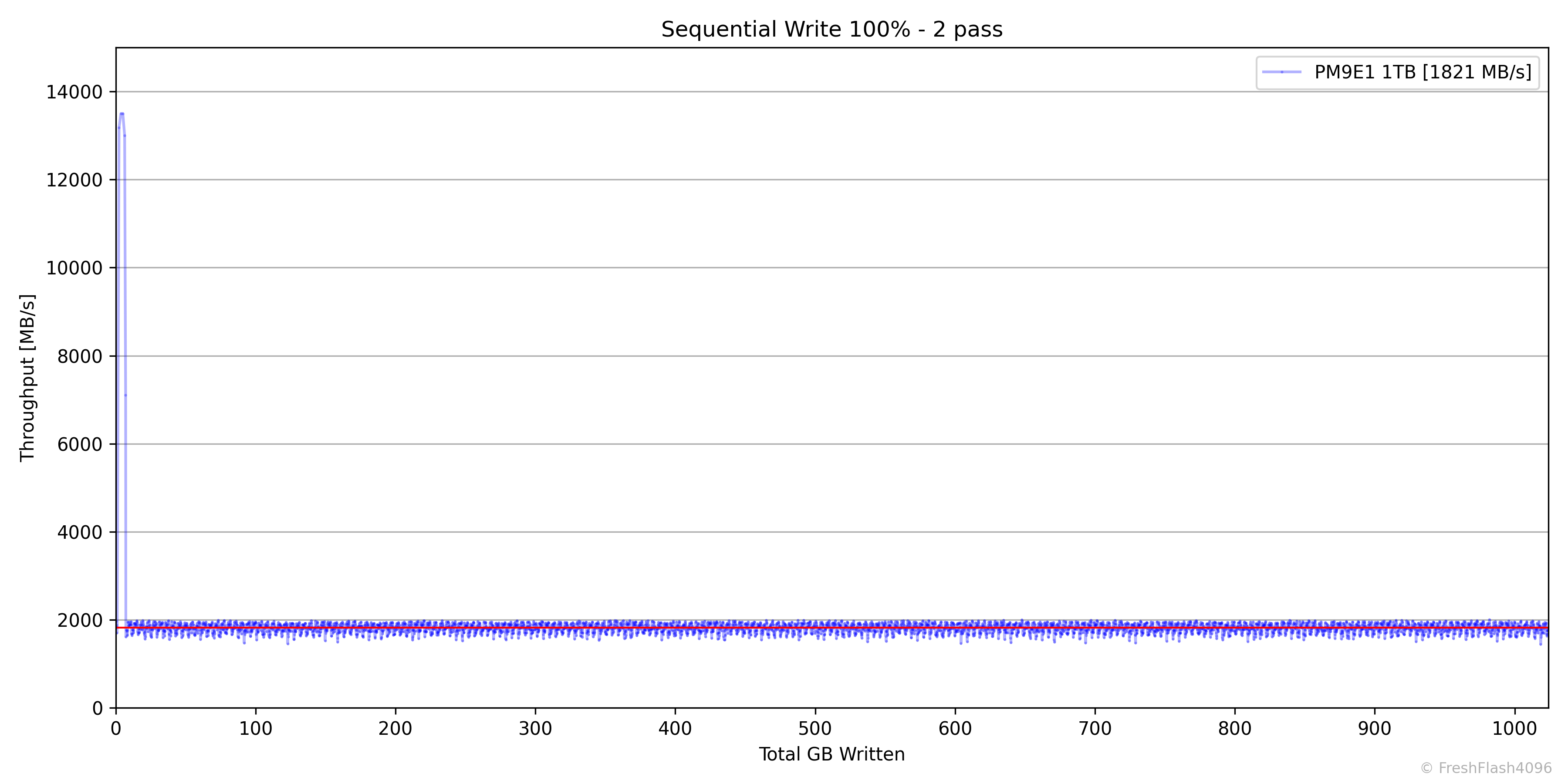
국내에서는 많은 사람이 나래온 더티 테스트를 통해 진행하는 벤치마크입니다. X축이 용량으로 고정되어 있으며, 기록 단위도 용량의 0.1%이라는 것이 상당한 단점이라고 생각하여 직접 진행하기로 했습니다.
워크로드는 SEQ 128k QD256이며, FOB 상태에서 시작해 용량의 100%를 채우고 휴식 시간을 부여한 뒤, 가득 찬 SSD에 동일한 워크로드로 용량의 100%를 채웁니다. 이를 통해 최대, 최소 SLC 캐시 용량을 파악할 수 있습니다.
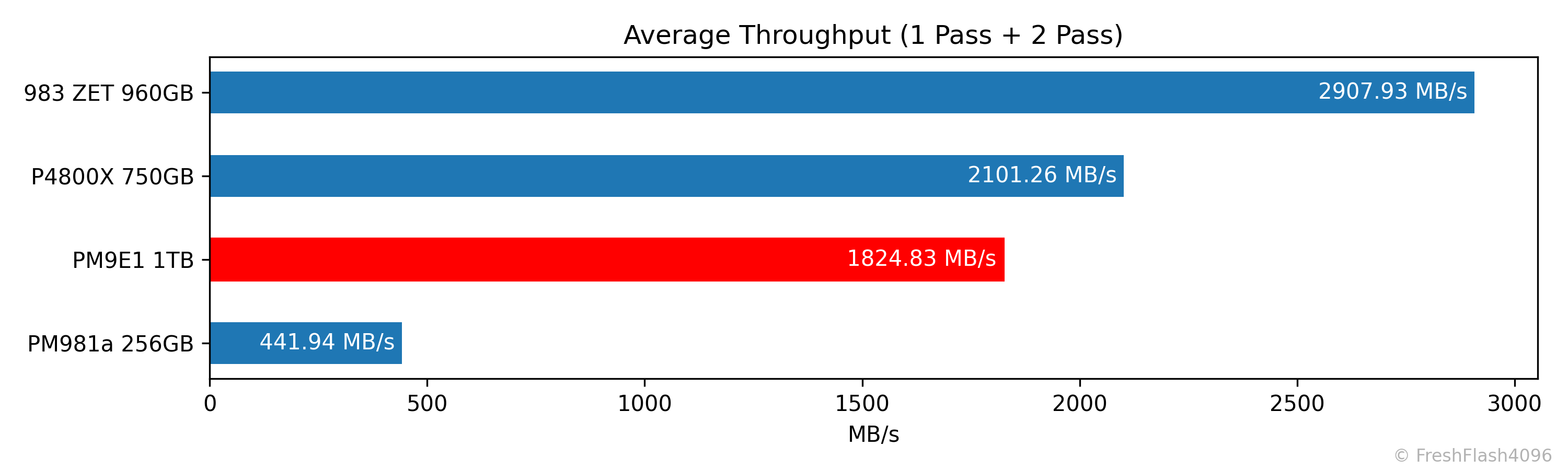
이후, 첫 번째와 두 번째의 속도에 대한 전체 평균을 내어 비교군을 내림차순으로 정렬해 제시합니다.

최대 속도는 보통 스펙 시트에 기재되기 때문에, 잘 명시하지 않는 최소 속도 쪽에 초점을 둡니다. 첫 번째 채우기에 대해서 상위 99%(하위 1%)의 값을 내림차순으로 정렬합니다. (2025. 12. 01. 수정)
Pre-Conditioning
cSSD에서 기대하는 성능은 Steady State가 아닙니다. 이는 엄연하게 소비자 워크로드가 아니기 때문입니다. 그렇다고 FOB 상태로 성능을 측정하는 것은 실제 워크로드를 반영하지 못할 확률이 높습니다. SSD에서 FOB 성능은 기존에 작성된 데이터나 접근하는 위치 등 여러 이유로 사용자가 실질적으로 체감하기 힘들 수 있기 때문입니다.
일반 소비자 워크로드의 특징은 여러 가지가 있습니다만, 일부만 꼽아보자면 다음과 같습니다.
- 유휴시간이 상당하다.
- 일부 영역에만 활발하게 접근한다.
- QD가 굉장히 낮다.
제 cSSD 벤치마크에 있어서 Pre-Conditioning은 아래와 같이 정의됩니다.
- Purge를 통해 FOB 상태로 만든다.
- User Capacity를 모두 SEQ 128k로 덮는다.
- 덮어진 상태 그대로 한 번 더 SEQ 128k로 덮는다. (Fill Drive Benchmark)
- 가장 앞 8GiB만을 RND 4k로 덮어씌운다.
- 사용 중인 공간이 75%가 되도록 가장 뒤의 25%에 대해서 TRIM을 진행한다.
이후, 랜덤 성능은 가장 앞 8GiB만을 대상으로 측정하며, 순차 성능은 나머지 영역에 대해서 측정합니다.
솔직히 말하자면, 이 정도의 Pre-Conditioning은 부족하다는 생각도 합니다. 오래 사용하며 데이터의 노후화가 일어나면 성능에 영향을 줄 때도 있으며, 용량이 작은 SSD에 대해서는 OS 용으로 95% 이상을 채우고 사용하는 때도 존재합니다. 반대로 용량이 매우 큰 SSD에서는 75%라는 수치가 쉽사리 통용되기 어렵다고 볼 수도 있죠.
사람마다, 그리고 SSD의 용량이나 특성 등에 따라 제가 진행하는 Pre-Conditioning은 전혀 현실을 반영하지 않을 수도 있습니다. 하지만 모든 것을 고려하기엔 시간과 예산, 그리고 지식이 턱없이 부족하여 이 정도로 마무리하고자 합니다. 물론 여기까지만 해도, 어떤 상태인지도 모르는 상태의 SSD와 벤치마크 방법을 상세하게 명시하지 않는 많은 국내 리뷰보다는 훨씬 현실을 반영하는 것이 아닌가 생각합니다.
Sync Write
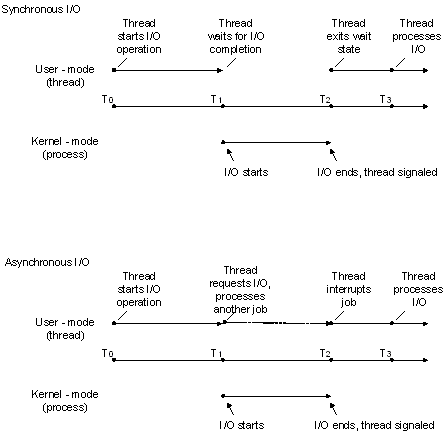
동기(Synchronous) I/O의 성능을 확인합니다. 동기 I/O를 수행하는 Thread는 I/O 작업을 시작하고 요청이 완료될 때까지 대기 상태로 진입합니다. 비동기(Asynchronous) I/O에서는 이와 다르게 I/O 요청이 완료될 때까지 다른 작업을 처리할 수 있습니다.
Linux를 기준으로, fsync()나 O_SYNC를 통해 발생하는 I/O라고 생각하면 됩니다. 이러한 동기 I/O는 파일과 그에 대한 메타데이터를 모두 SSD에 영구적으로 기록해야 할 필요가 있기에 쓰기 시간이 오래 걸립니다.
이러한 이유로 소비자 워크로드에서의 I/O는 대부분이 비동기로, 영구적으로 기록을 하는 것은 데이터를 모아두었다가 주기적으로 시행합니다. 하지만, Homelab을 즐기는 등의 일부 소비자들은 ZFS나 Ceph, DB 등을 사용하는 경우가 있는데, 이러한 경우에는 동기 I/O가 발생하기도 합니다. 그렇지만, 앞서 말한 것들도 cSSD에선 전혀 고려되지 않는 워크로드이기에, 동기 I/O에 대해서는 세대나 라인업과 관계 없이 낮은 성능을 보입니다. 다만, 제조사의 편차는 약간 존재합니다. 펌웨어의 구현 차이라고 생각되네요.
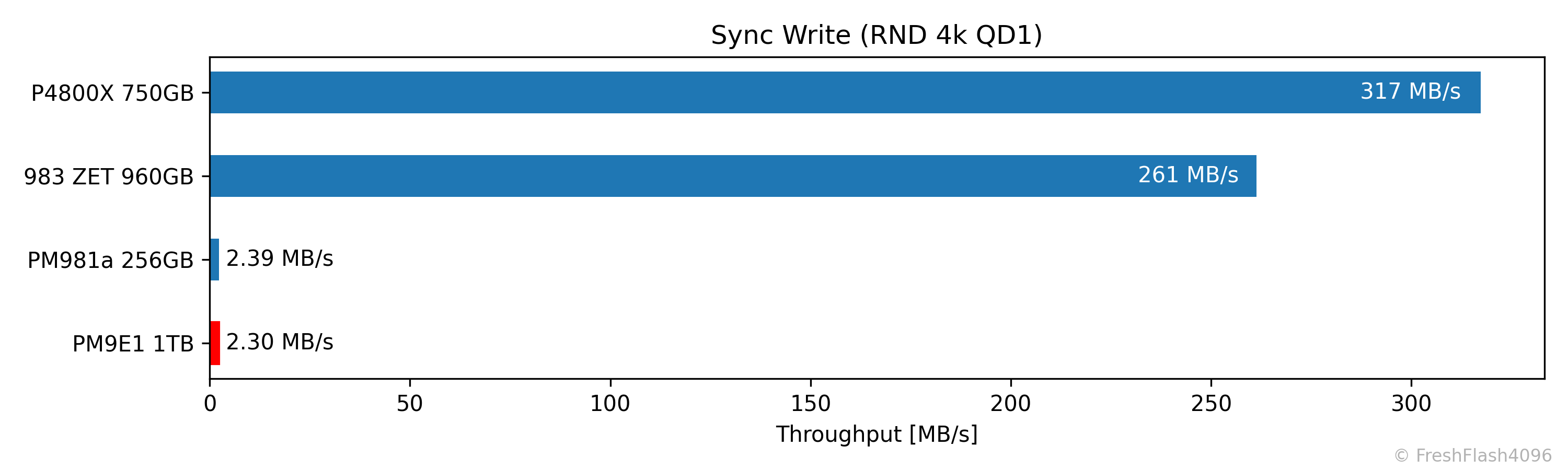
이런 식으로 cSSD에선 굉장히 처참한 성능을 보이지만, 제대로 된 eSSD는 동기 I/O의 성능이 비동기 I/O의 성능과 차이가 없습니다. PLP(Power Loss Protection) 기능이 존재해 갑작스러운 전원 차단에도 메타데이터 등의 갱신이 가능하므로 동기와 비동기 I/O를 구분하지 않아 성능 차이가 존재하지 않는 것이죠.
따라서 eSSD에는 이 벤치마크 자체가 의미가 없습니다. 또한, Burst 성능을 측정하기 때문에 eSSD의 성능 측정에는 알맞지 않기도 합니다. 그렇기에 eSSD의 결과는 비교군으로 제시하지 않습니다.
워크로드는 RND 4k QD1이며, sync=1 옵션을 지정합니다. 이전에 Pre-Conditioning이 완료된 영역(가장 앞 8GiB)에 한정해 완전히 무작위로 접근하며, 총 500MiB의 쓰기를 가합니다. 다만, SSD에 따라 시간이 너무 오래 걸릴 가능성도 있기에 총 벤치마크 시간은 최대 2분으로 제한합니다.
Performance by RW Ratio

cSSD의 스펙 시트는 SEQ RW, RND RW로 이루어진 4-corners performance만 제시합니다. 하지만 일반적인 NAND 기반의 SSD는 읽쓰기 작업이 혼합되어 있을 때 성능이 하락하며, Real World Workloads에서도 혼합된 작업이 발생하는 경우가 많습니다.
Real World Workload를 고려해 QD=1, 2, 4에 대해서만 진행되며, 읽쓰기 비율은 10% 단위로 변경하며 성능을 측정합니다. 각 단계 사이에는 휴식 시간이 부여되어 온전한 성능을 나타낼 수 있도록 했습니다. 앞서 동기 쓰기와 마찬가지로 Pre-Conditioning이 완료된 영역에만 완전히 무작위로 접근합니다. 발생하는 I/O의 양은 하나의 단계에서 1GB 이하로, 굉장히 가벼운 cSSD 워크로드를 염두에 두었습니다. (2025.11.23 수정) 하지만, 아주 느린 저장장치가 있을 수도 있으니, 테스트 시간은 단계별로 최대 30초 제한을 부여합니다.
또한, 동일한 워크로드를 여러 번 실행하여 값을 결정합니다. 값의 결정에는 Intel의 권장 사항을 반영해 중앙값과 상대 표준 오차를 이용합니다.
Median and Relative Standard Error
Intel은 데이터 세트의 실제 값을 보고할 때 중앙값(median)의 사용을 권장합니다. 평균값(average)는 계산을 통해 도출되기 때문입니다.
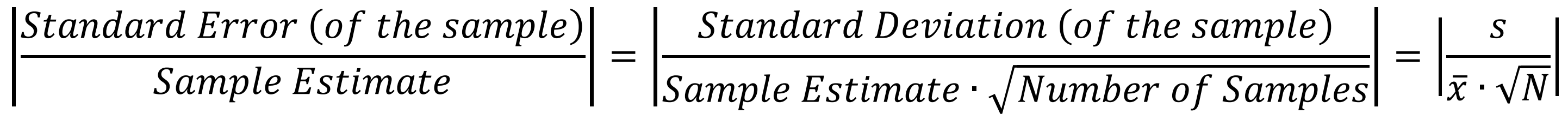
상대 표준 오차(Relative Standard Error, RSE)는 통계량의 신뢰도를 측정하며, 여기서는 데이터 세트의 변동성을 평가하기 위해 사용합니다. 워크로드는 각 5회 이상 반복되며, 가장 최근 3번의 실행에 대해 RSE를 계산하여 5%보다 낮으면 그 중앙값을 채용, 5%보다 높으면 워크로드를 10회까지 반복하여 데이터를 수집합니다.
그런데도 RSE가 높게 유지되면 그 값을 보고한 후, 그래프에 포함합니다.
Weighted Graph
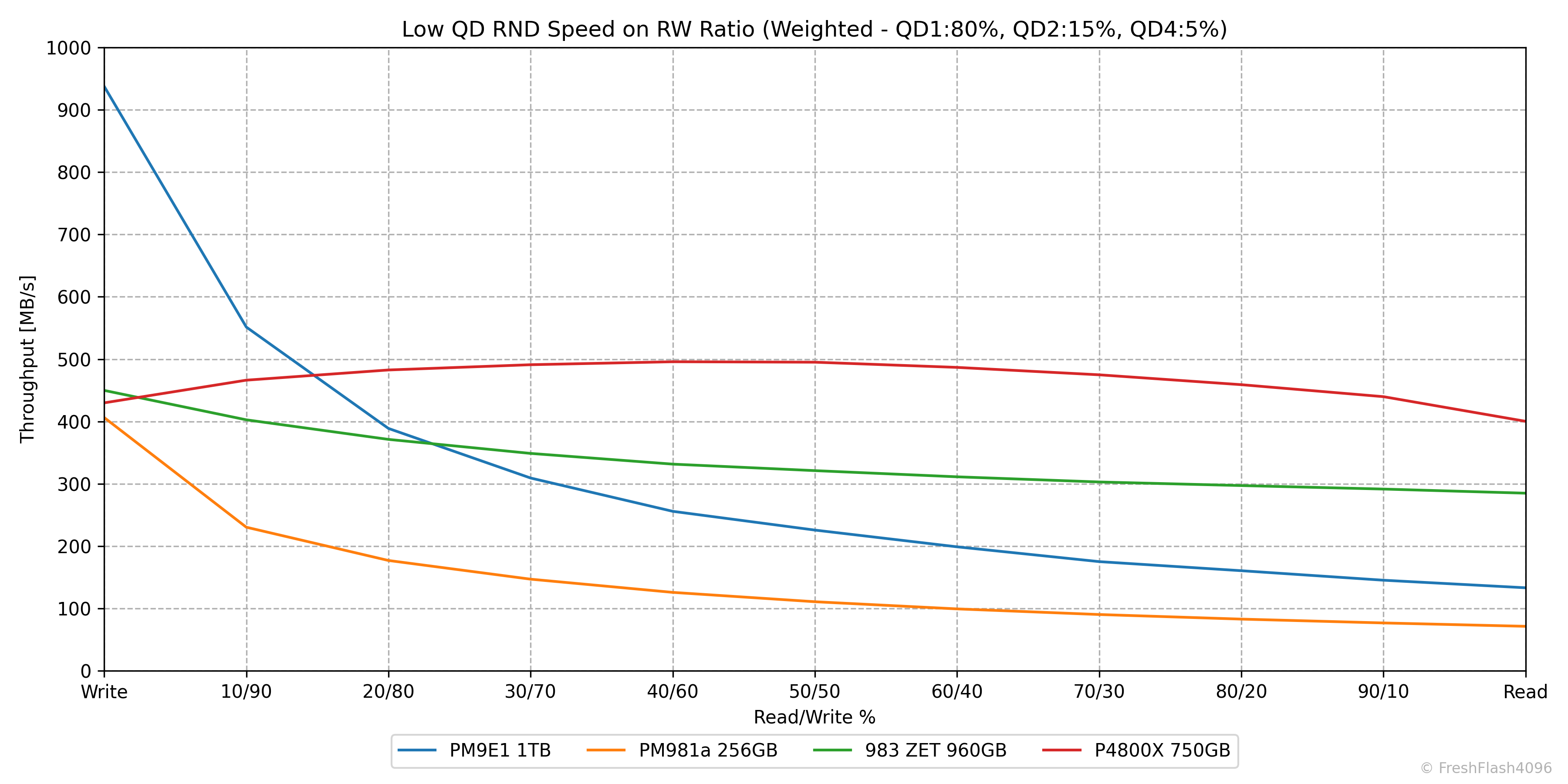
비교군들의 성능을 한눈에 보기 위해 가중치를 적용한 그래프를 제시합니다. 이전에는 QD1 70%, QD2 20%, QD4 10%로 가중치를 부여했지만, 이 비율을 변경해 QD1 80%, QD2 15%, QD4 5%로 진행합니다.
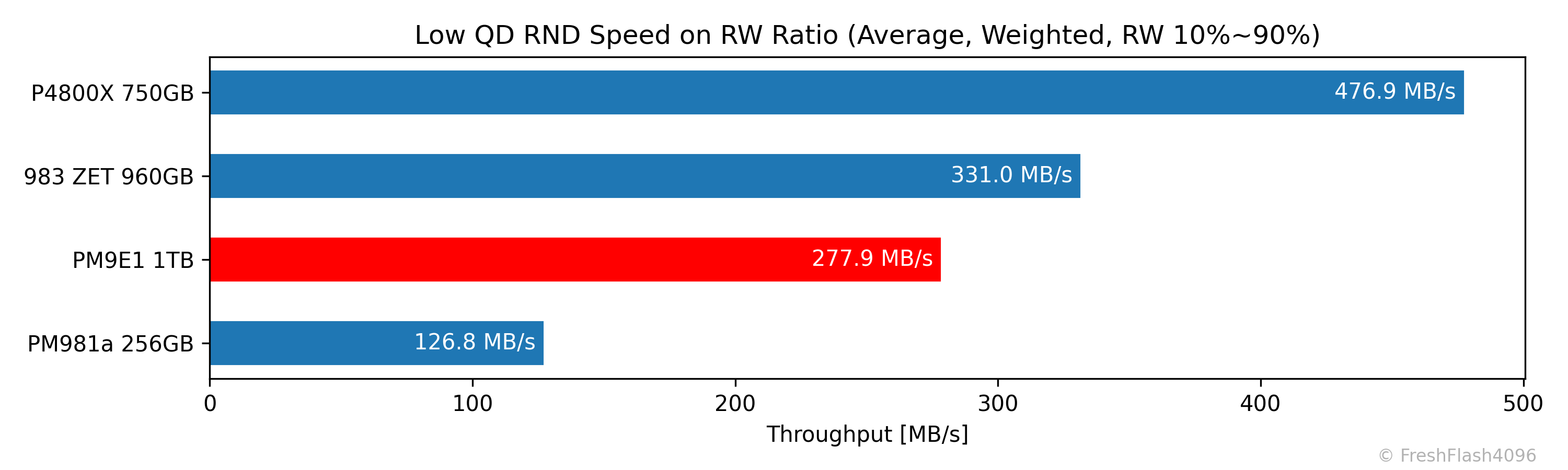
순위를 매길 때에는 가중치를 부여한 값의 평균을 이용합니다. 단, 여기서는 100% 읽쓰기 값을 제외하고 처리합니다. 다시 말해, 혼합된 작업에 대해서만 평균을 내는 것이죠. (2025.11.16 수정)
일반적인 소비자 워크로드에서 쓰기보다 읽기가 많이 발생한다는 것을 고려하면, 위 막대그래프의 값은 쓰기 성능이 조금 더 강조되어 있다고 볼 수 있겠습니다.
Performance by Active Range

SSD에서 DRAM은 NAND의 물리적 주소와 OS가 인식하는 LBA를 변환하는 Mapping Table(L2P Table)의 사본을 저장합니다. 다시 말해, Caching을 수행합니다. DRAMless SSD도 컨트롤러의 SRAM이나 HMB(Host Memory Buffer)를 통해 사본을 저장하죠. HMB의 구현도 계속해서 발전하고는 있지만, 그 영역의 크기가 작아 결국 전체 사본을 저장하지는 못합니다.
그런데도, 접근하는 범위가 좁아 I/O의 지역성이 높으면 처리는 비교적 쉽습니다. Cache Hit가 발생하니까요. 이러한 부분 때문에 앞의 "Performance by RW Ratio" 테스트는 어렵지 않은 테스트입니다.
하지만, 접근하는 범위가 넓어지면 어떻게 될까요? Cache miss가 발생하여 성능이 하락합니다. DRAM이 실장 되어있는 SSD라도 일반적인 DRAM:NAND = 1:1000의 비율을 따르지 않고, 단순하게 L2P Table을 Caching 했다면, Cache miss가 발생하여 전체 드라이브에 접근할 때 성능이 떨어질 것입니다.
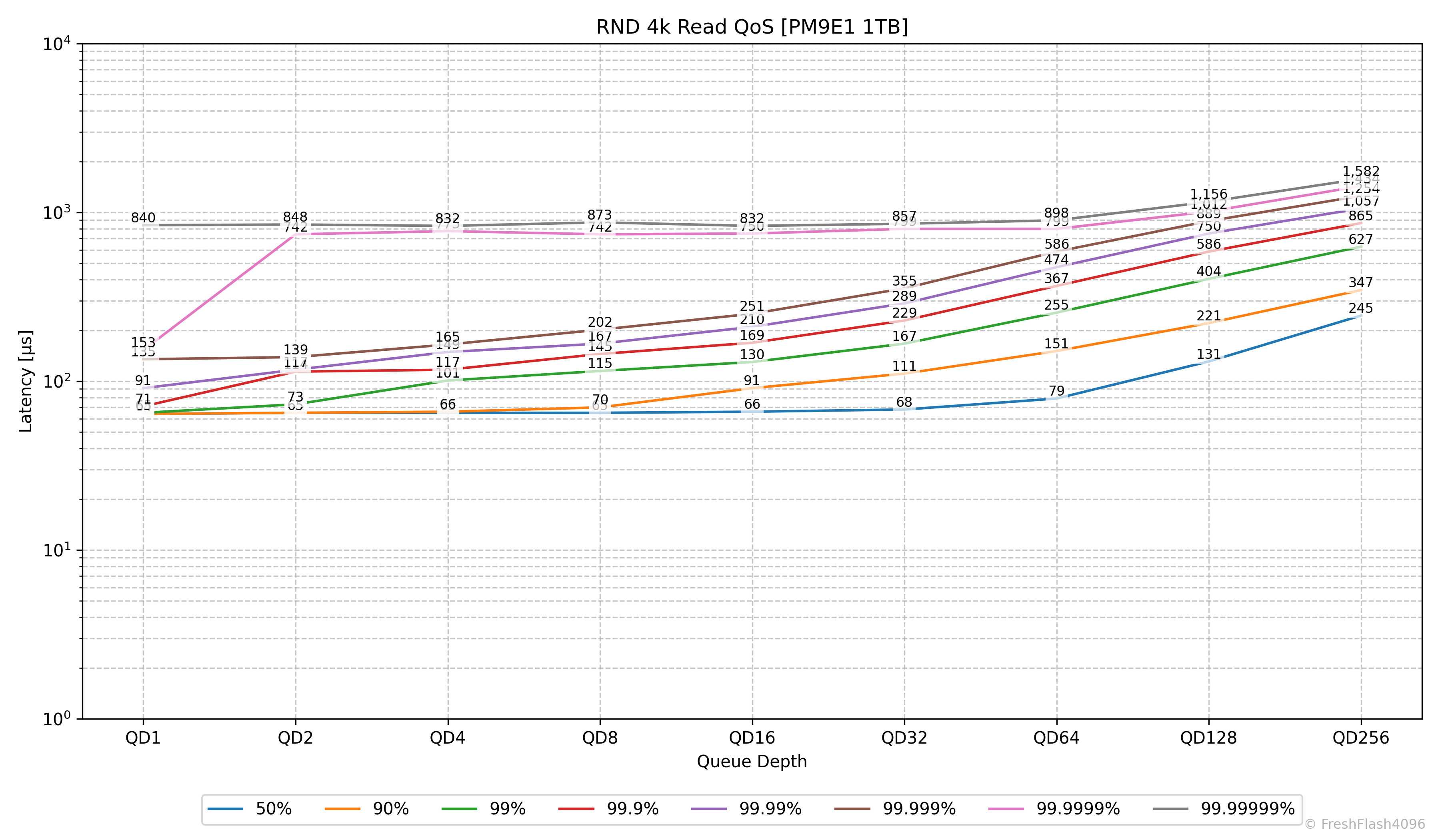
이 테스트는 Fill Drive가 끝난 뒤 휴식 시간을 부여하고 진행되며, 접근하는 영역의 크기는 1GiB로 시작해 마지막으로는 전체 드라이브에 대해 1GiB의 RND 4k QD256 읽기를 완전히 무작위로 수행합니다. 예시로 제시된 그래프는 PM9E1 1TB로, 접근 영역이 넓어지더라도 성능 하락이 없는 것을 확인할 수 있습니다.
평소의 리뷰에선 이를 제시하지 않으며, 성능 하락 등이 발견된 SSD에서만 이 그래프를 포함합니다.
SLC Cache Reclaim
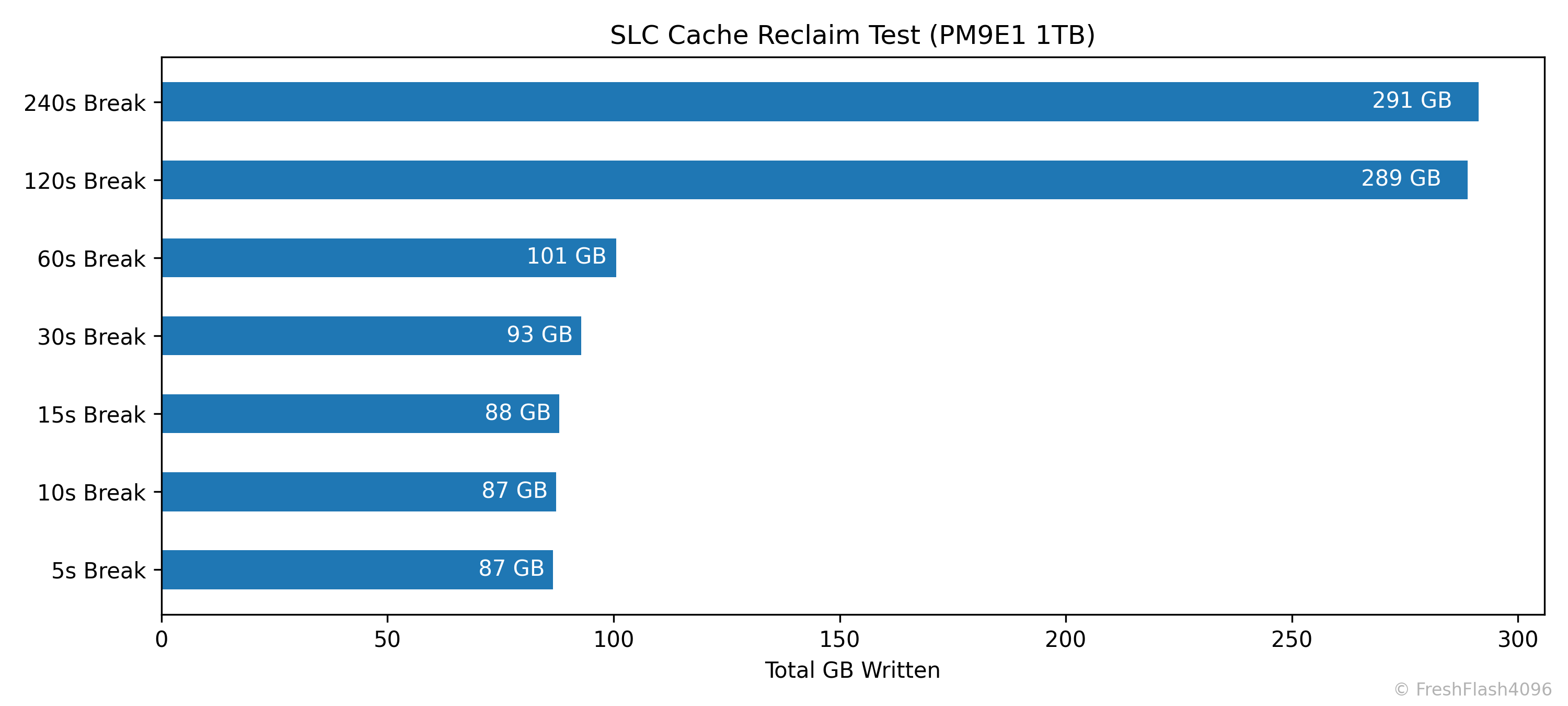
SLC 캐시의 회복에 대해서 알아보기 위해 진행하는 벤치마크입니다. Purge를 수행하고 User Capacity의 50%를 SEQ 128k QD256로 채운 뒤, 잠깐의 휴식을 취하고 다시 SEQ 128k QD256 쓰기를 1분간 진행합니다. 그리고 휴식 시간을 늘려가며 이를 반복합니다.
휴식 시간은 5초, 10초, 15초, 30초, 60초, 120초, 240초로, 총 7회의 Purge - 50% Write - 1min Write의 사이클을 거칩니다. Purge 이후의 휴식 시간도 고려하면 굉장히 오래 걸리고 좀 귀찮죠.
리뷰에서 직접 제시되는 것은 휴식 뒤 1분간 작성한 총 용량만 나타낸 위의 그래프입니다.
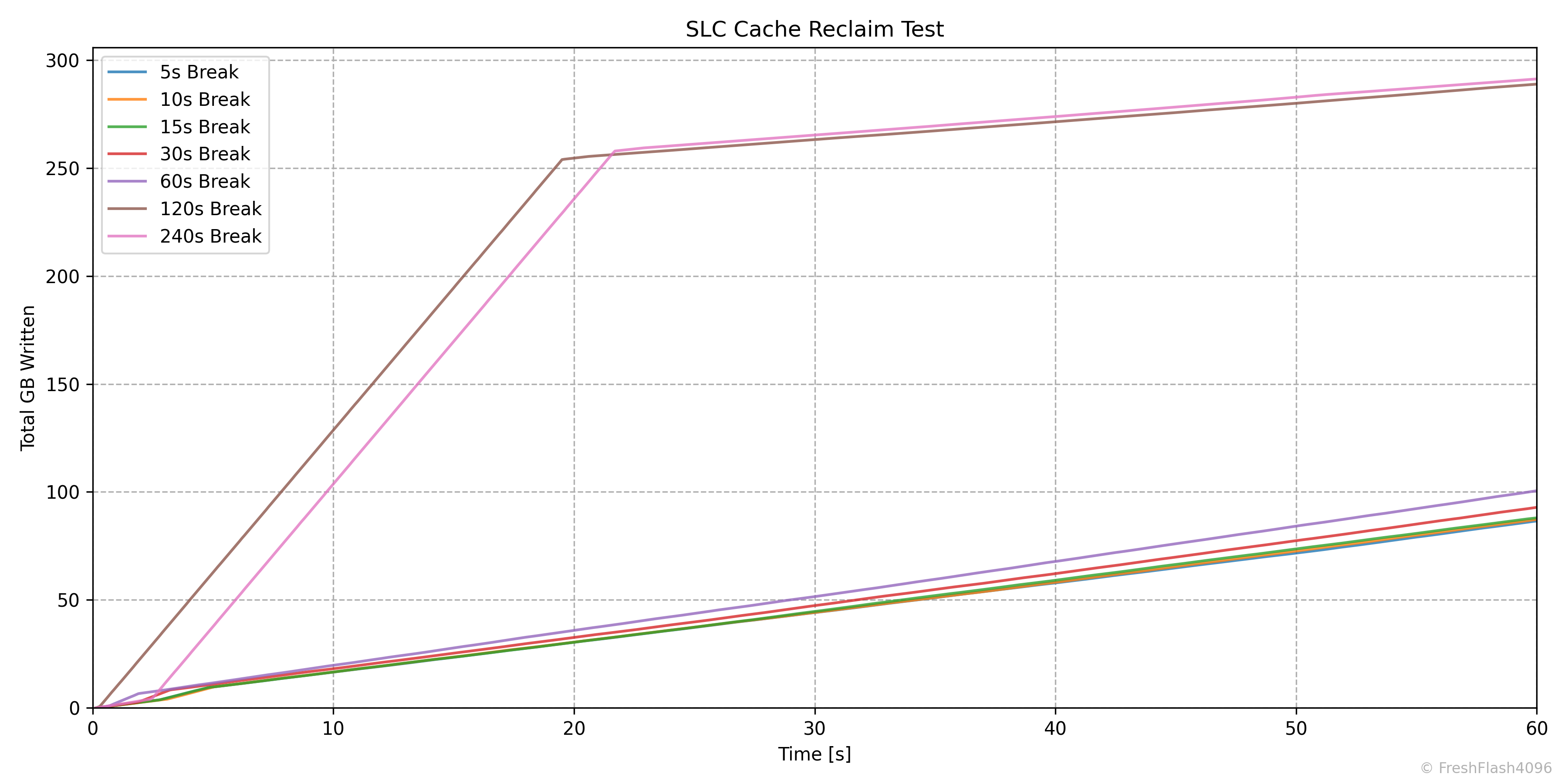
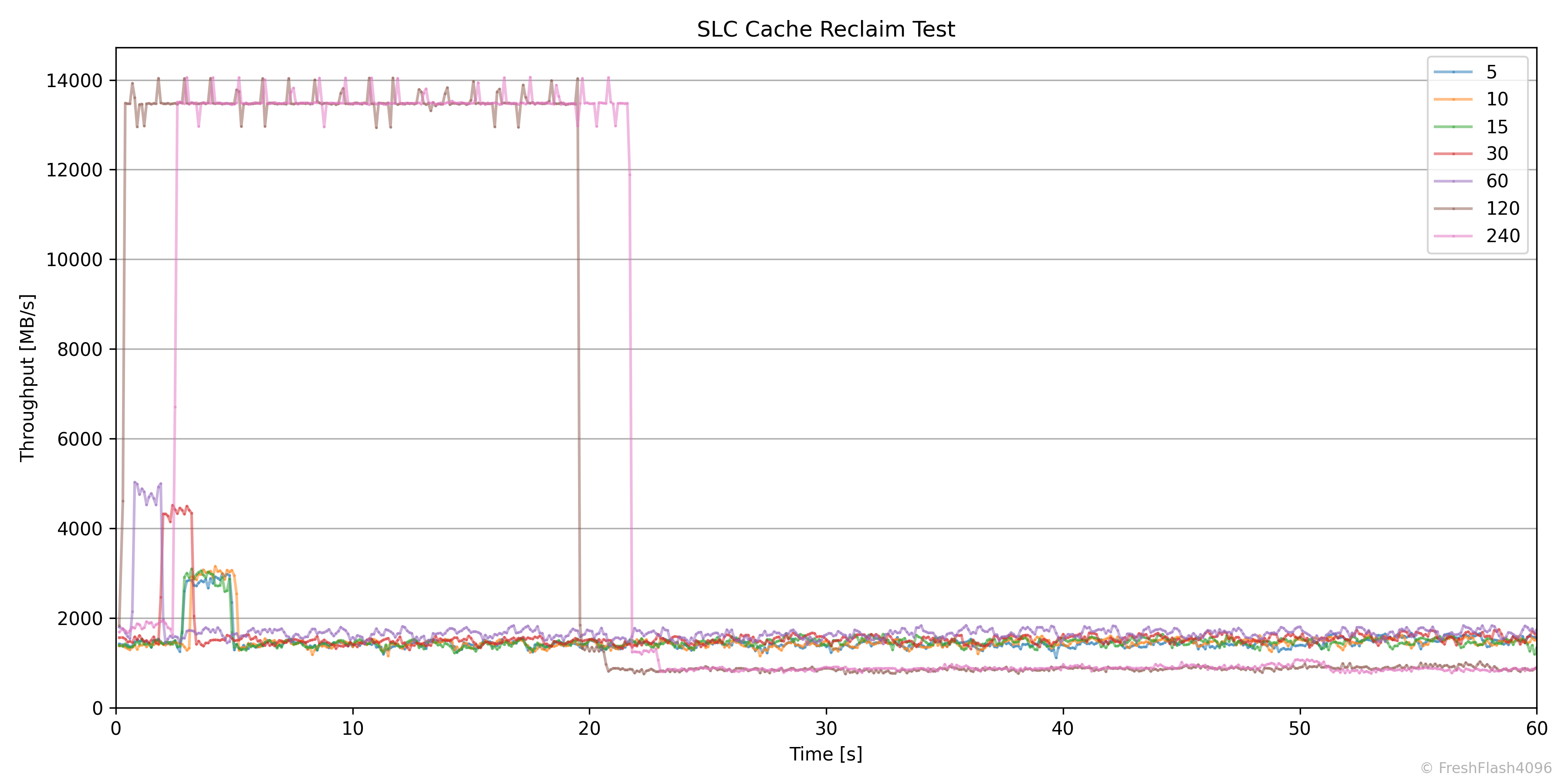
처음엔 이러한 시간에 따른 총 쓰기량이나 속도의 변화가 담긴 그래프를 사용하려고 했는데, 생각보다 그래프가 직관적이지 않아 위의 총 쓰기량만 비교하는 것으로 결정했습니다. 이 친구들은 제가 혼자 보고 있다가 필요할 때 제시하겠습니다.
eSSD Benchmarking
// Normal
01. Linux Boot
02. Purge
03. SEQ Pre-Conditioning (128k QD256)
04. SEQ Performance Measure (R/W/RI)
05. RND Pre-Conditioning (4k QD256)
06. RND Performance Measure (R/W/Mainstream/WI/AI)
07. Purge
08. OCP BootBench
// IUs > 4k
01. Purge
02. SEQ Pre-Conditioning (IU QD256)
03. SEQ Performance Measure (R/W)
04. RND Pre-Conditioning (IU QD256)
05. RND Performance Measure (R/W)
eSSD의 테스트 과정은 위와 같습니다. cSSD와 다르게 Purge 직후를 제외한 모든 단계 사이에는 휴식 시간이 부여되지 않습니다. Pre-Conditioning은 User Capacity의 2배를 쓰고나서도 Steady State에 진입할 때까지 이를 계속 진행합니다.
Steady State는 SEQ의 경우엔 대역폭의 기울기가 ±10%인 상태를 30초간 유지하는 것을 기준으로 하며, RND의 경우에는 IOPS의 기울기가 ±10%인 상태를 30초간 유지하는 것을 기준으로 합니다. 이를 달성할 수 없을 땐 드라이브 용량의 23배까지 쓰기를 진행합니다.
모든 워크로드는 User Capacity의 전체 영역에 대해서 진행하며, 각각 30초의 적응 시간을 가진 후에 5분 동안 성능측정을 진행합니다. 다시 말해, 128k Read 성능을 측정한다면 QD1 ~ QD256까지 총 9개의 작업이 있으며, 모든 작업이 30초의 적응 시간과 5분의 측정시간이 부여됩니다.
Pre-Conditioning을 제외하더라도 하나의 SSD가 이 벤치마크를 수행하는 데 걸리는 시간은 6시간 이상으로, Pre-Conditioning을 포함한다면 더욱 길어집니다. cSSD는 기본적으로 플래그십 제품이나 OCP BootBench를 통과하는 등, 나름 성능이 괜찮다고 판단된 제품에서만 벤치마크를 진행합니다.
2-in-1 Graph
eSSD 벤치마크에선 cSSD에서 중점적으로 다루는 Bandwidth나 IOPS 뿐만이 아닌, 지연시간도 다룹니다. 역시 FIO를 통해서 벤치마크를 진행하며, 지연시간은 FIO에서 보고하는 clat(Completion latency)를 사용합니다.
소제목에서 언급한 대로 그래프로 돌아가면, Bandwidth를 나타내는 그래프는 보기 쉬운데, 지연시간은 지수함수와 같이 증가해 알아보기가 힘듭니다.
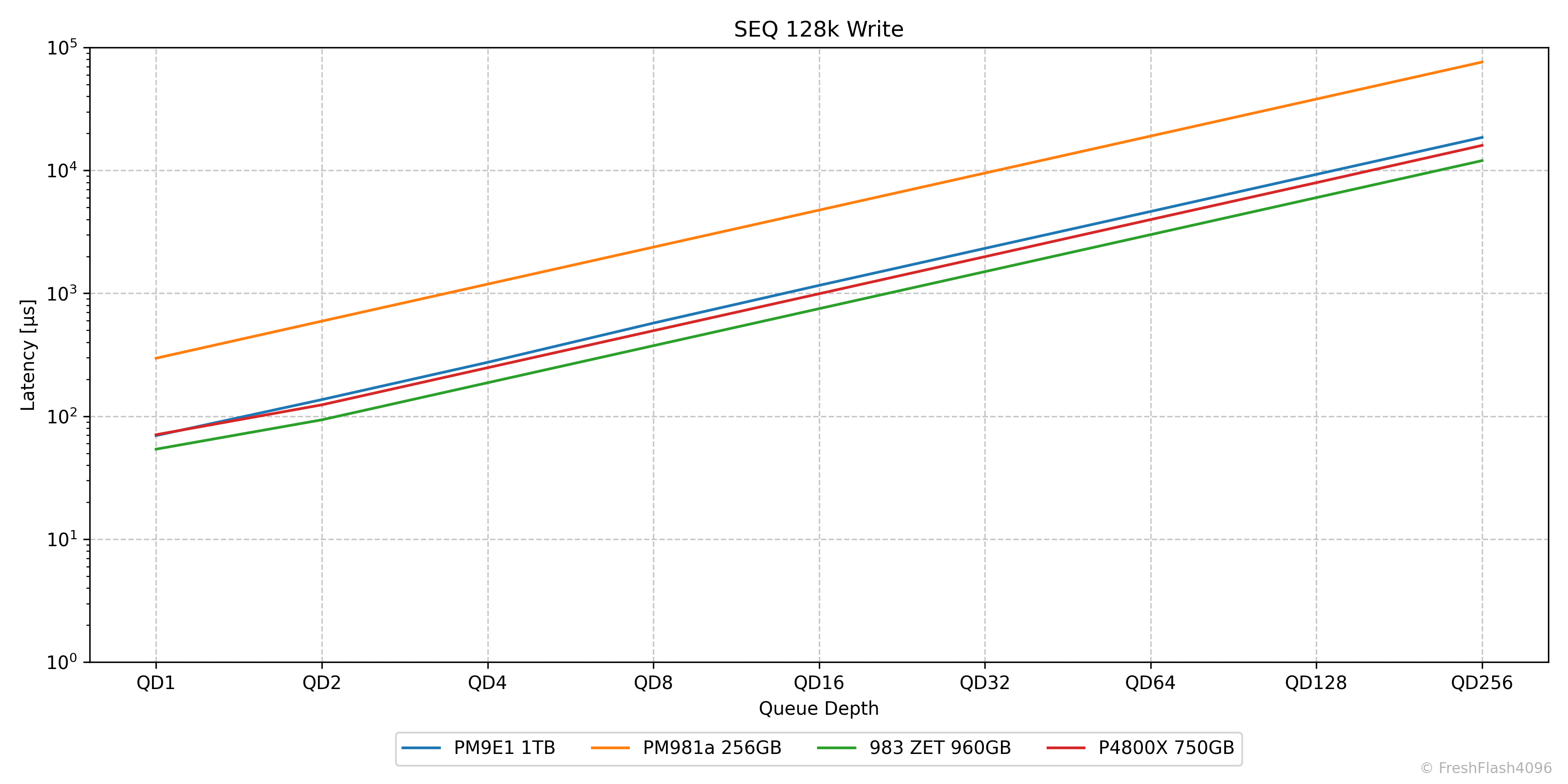
그럴 땐 Log scale이죠. 이제 훨씬 보기가 편합니다. 그럼 이렇게 쭉 제시해볼까요?
eSSD 벤치마크는 간단하게 잡아서 4-Corners Performance를 측정하고, 일부 워크로드에 대해 성능과 지연시간을 측정하고, 특정 SSD에 대해서는 4-Corners Performance를 한 번 더 측정합니다. 지금 말한 것만 하더라도 Bandwidth/IOPS 그래프와 지연시간 그래프를 모두 그리면 24개가 됩니다. 하지만 저는 여기에 더해 Consistency 그래프와 Tail Latency 그래프도 제시할 것입니다. 머리가 아프네요.
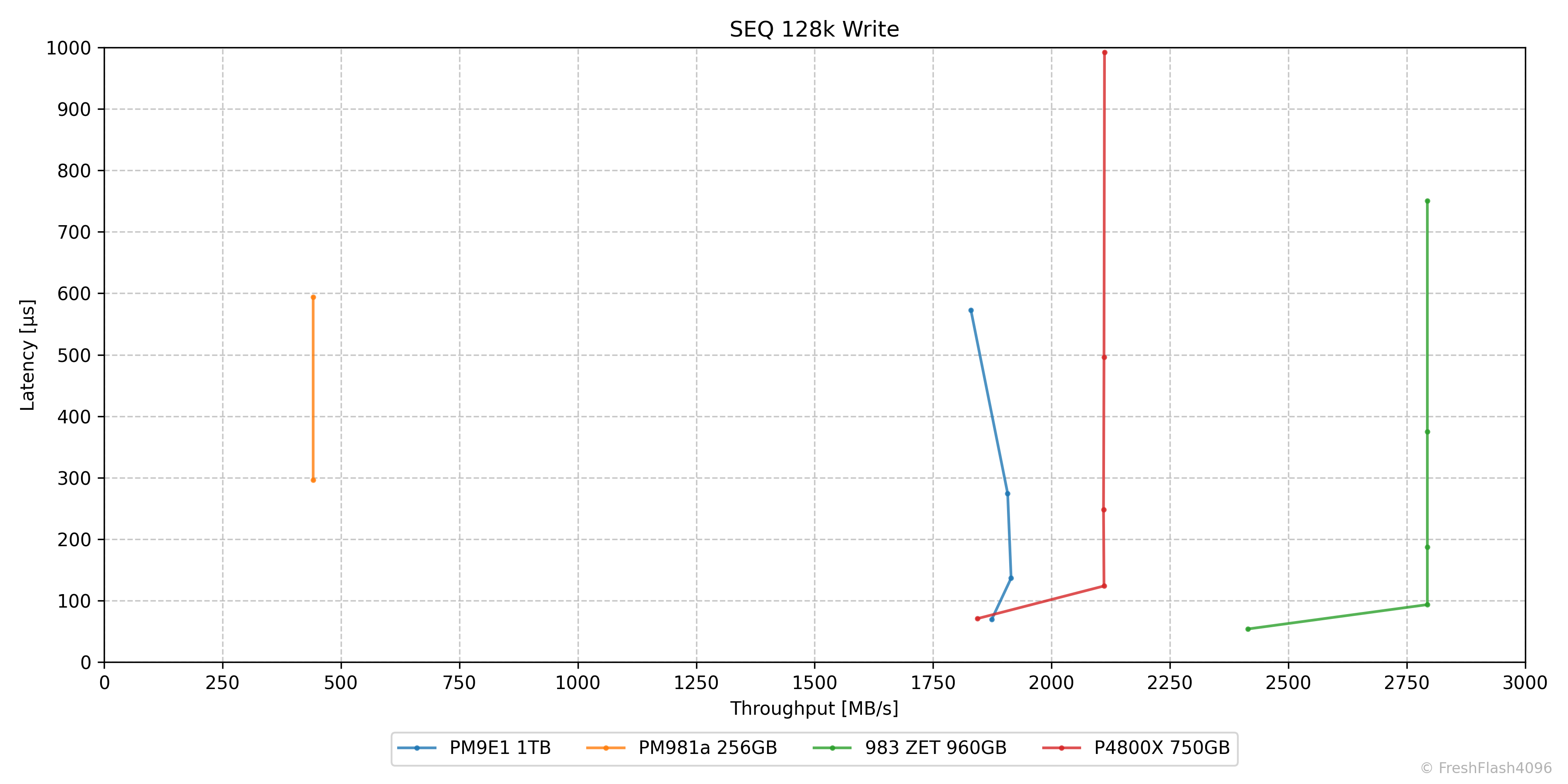
이를 압축한 것이 이 그래프입니다. X축은 Bandwidth나 IOPS를, Y축은 Latency를 나타냅니다. QD에 대한 정보는 점으로 표현합니다. 점의 개수가 QD1 ~ QD256에 맞지 않는 이유는 지연시간이 1ms 이상인 포인트에 대해선 모두 제거하고 그래프를 그리기 때문입니다. 참고로, 선의 좌측하단에 위치한 시작점이 대부분 QD1입니다.
대부분의 SSD에서 1ms가 넘는 지연시간이 나오는 상황은 Bandwidth나 IOPS가 더 증가할 수 없는, 이른바 한계에 봉착한 상황이기에 큰 문제가 되지 않으리라 판단했습니다. 그럴 일은 없을 것으로 생각하지만, 혹시라도 예외가 발견되면 기존 그래프의 형태도 함께 제시합니다.
이 그래프가 나오게 된 이유와 읽는 법에 대해 알게 되었으니, 이제 아래에서 제시하는 그래프들을 읽는 데 큰 문제가 없을 것으로 생각합니다. 그래도 4-Corners Performance에서 제시되는 그래프들은 함께 해석해 보기로 하죠.
4-Corners Performance
SEQ Pre-Conditioning
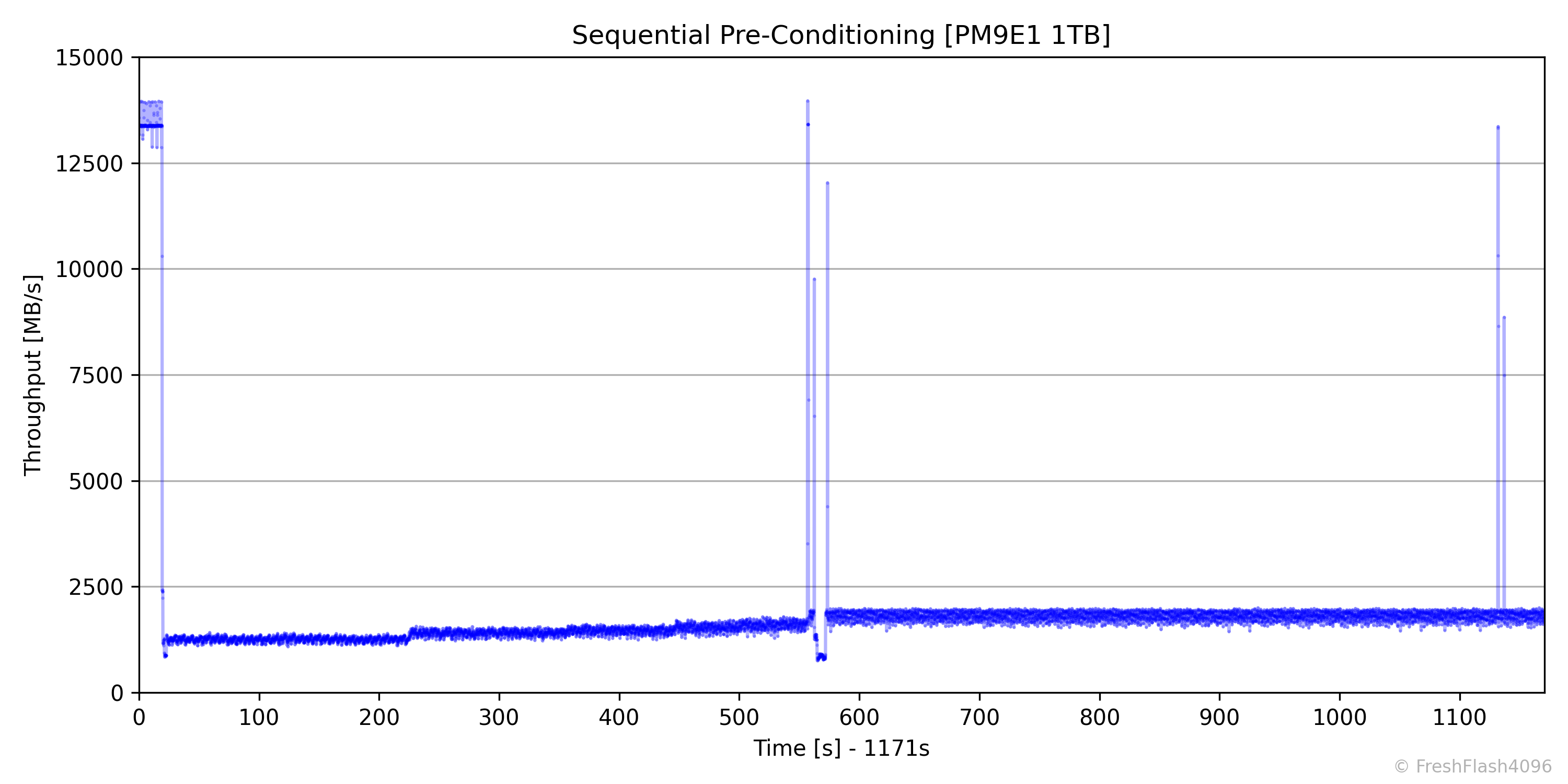
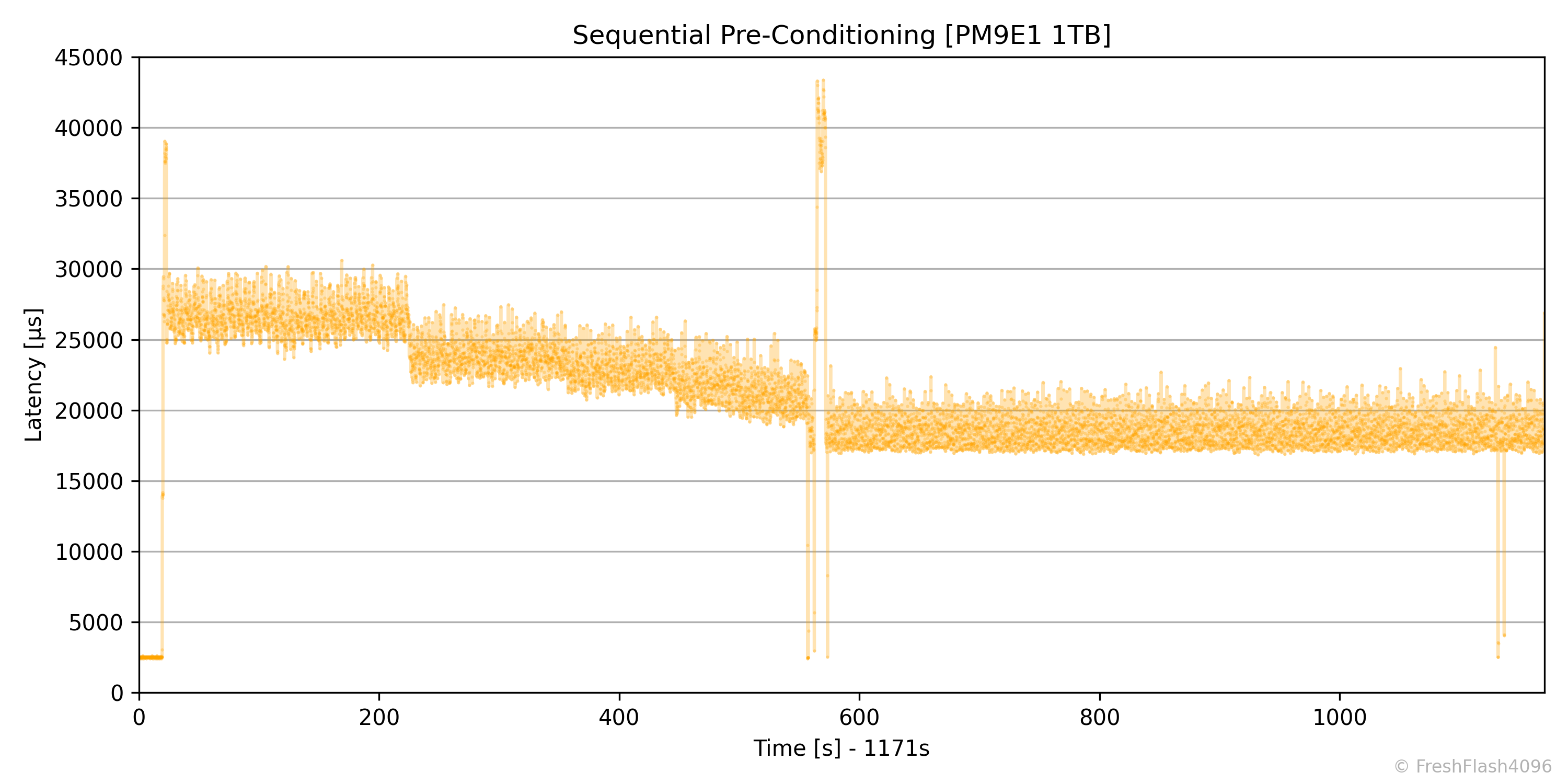
FOB 상태에서 휴식 시간을 부여하지 않고 계속해서 SEQ 128k QD256 부하를 가합니다. 앞서 말한 대로 기본적으로 User Capacity의 2배에 해당하는 만큼 쓰기를 진행하고, 이후에 Bandwidth의 기울기가 ±10%인 상태를 30초간 유지한다면 Steady State로 판단하여 바로 다음의 순차 성능 측정으로 휴식 없이 넘어갑니다.
SEQ Pre-Conditioning 단계에서는 100ms 단위로 데이터를 수집하며, Bandwidth와 Latency를 수집해 시계열 그래프로 출력합니다.
SEQ 128k Read

흔히 순차 읽기라고 부르는 이 워크로드에서는 모든 QD에서 PM9E1이 가장 우세합니다. PM9E1은 QD16부터 대역폭의 한계로 지연시간만 늘어나는 형태를 취하고 있습니다.
SEQ 128k Write
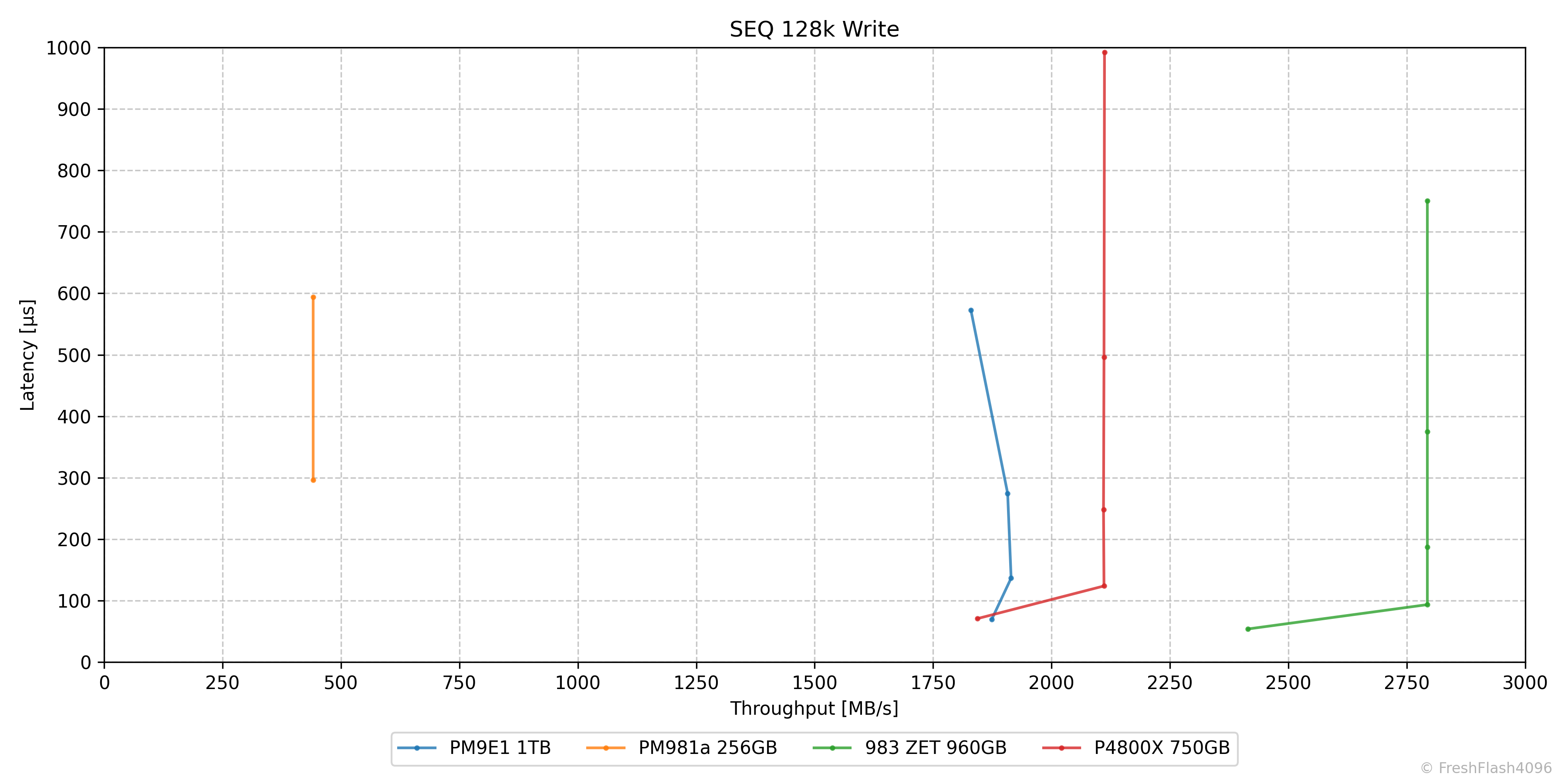
순차 쓰기에서는 983 ZET가 가장 우수합니다. PM981a도 눈에 띄네요. 포인트가 2개인 것으로 보아, QD1 - QD2를 끝으로 QD4부터는 지연시간이 1ms를 초과하여 그래프에 반영되지 않은 모습입니다.
P4800X와 PM9E1은 QD1에서는 PM9E1의 성능이 좋았지만, QD2 이후로는 P4800X가 더 우수한 모습을 보였습니다. PM9E1은 QD4와 QD8에서 성능이 오히려 약간 후퇴된 것을 확인할 수 있었습니다.
RND Pre-Conditioning
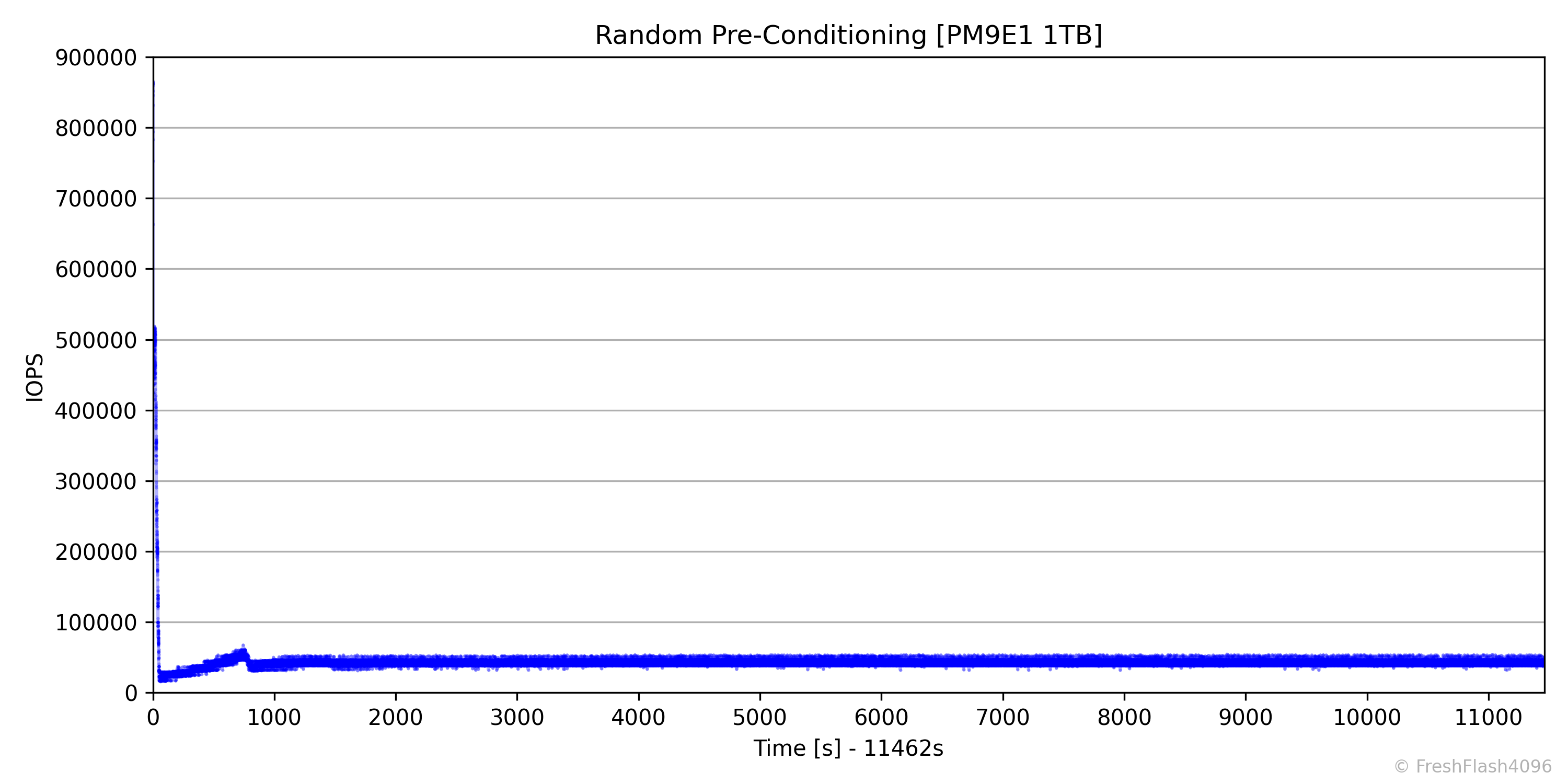
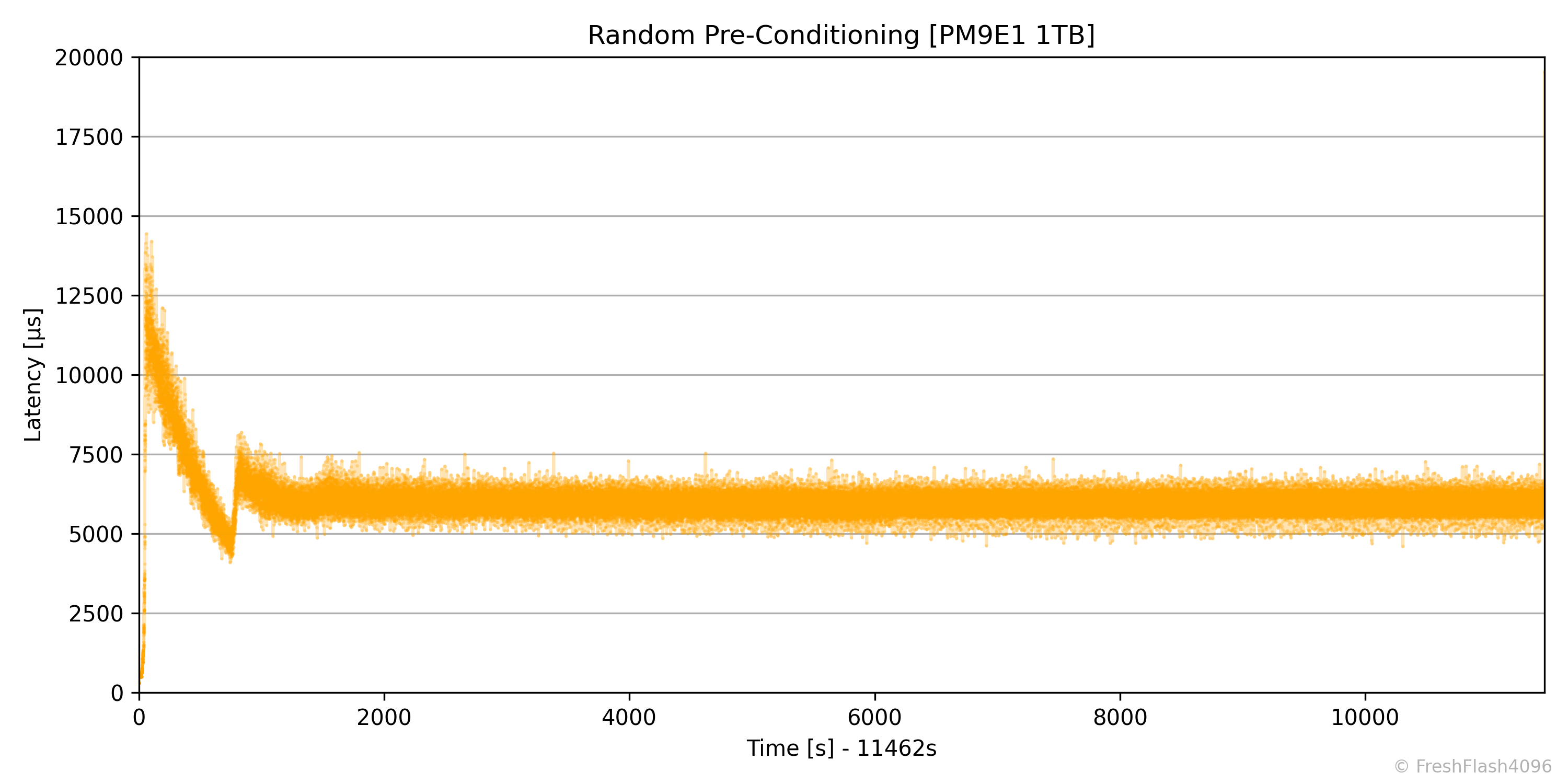
RND Pre-Conditioning은 SEQ과 다르게 FOB 상태에서 시작하지 않습니다. 이전의 SEQ 성능 측정이 완료되면 휴식 시간 없이 바로 RND 4k QD256 부하를 가합니다. 다시 말해, DUT는 이미 128k로 가득 차 있는 상태에서 RND 4k 쓰기를 가하는 것입니다. 이 상태에서 User Capacity의 2배에 해당하는 만큼 쓰기를 진행하고, 이후에 IOPS의 기울기가 ±10%인 상태를 30초간 유지한다면 Steady State로 판단하여 성능 측정 단계로 넘어갑니다.
SEQ Pre-Conditioning 단계와 마찬가지로 RND Pre-Conditioning 또한 100ms 단위로 데이터를 수집하며, IOPS와 Latency를 수집해 시계열 그래프로 출력합니다.
RND 4k Read
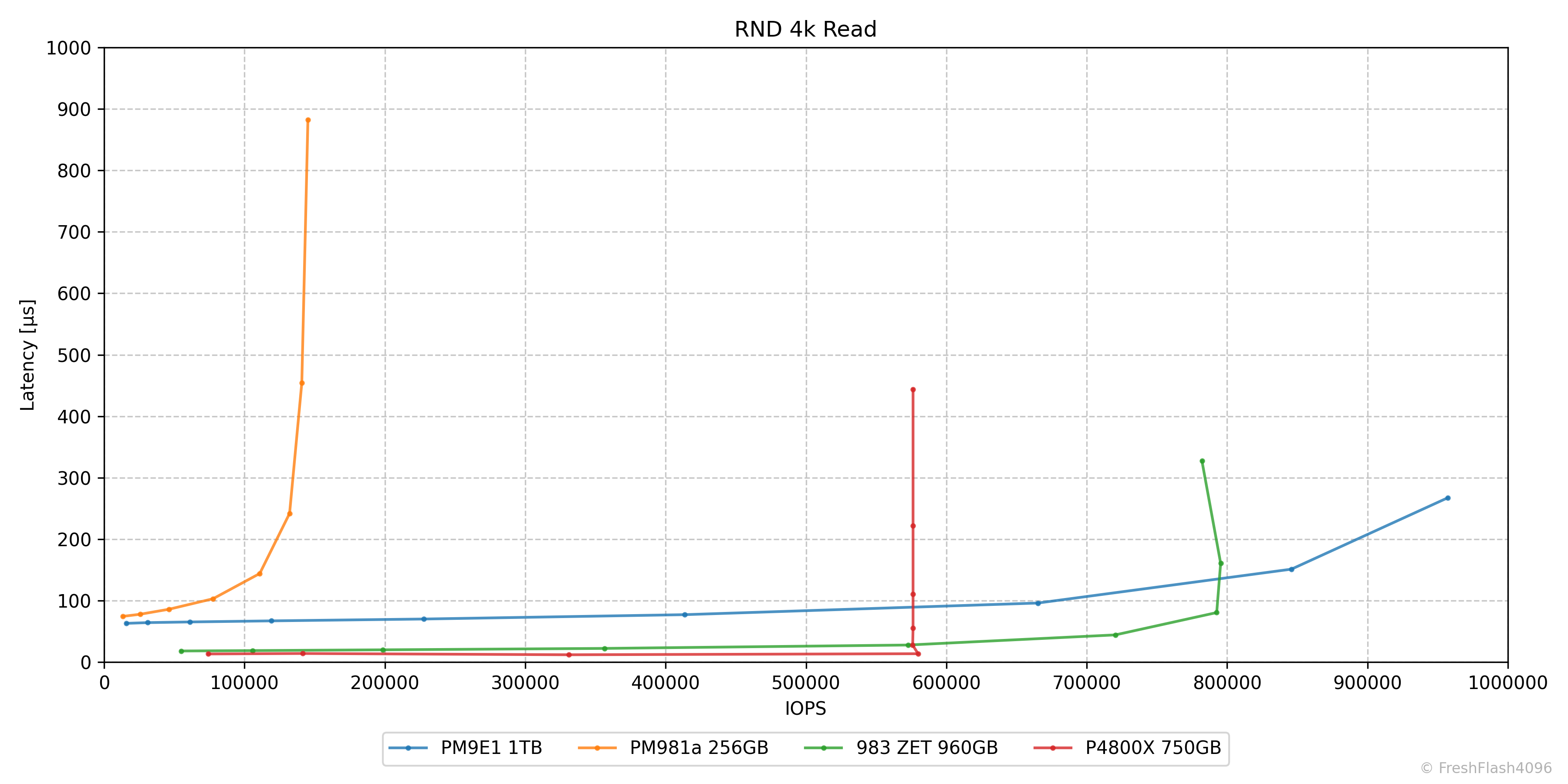
랜덤 읽기에서 PM981a는 QD32의 130k IOPS 부근에서 성능 향상이 정체되어 지연시간이 늘어나지만, PM9E1은 QD256까지 성능이 확장되어 최대 950k IOPS이상의 성능을 보여줍니다.
P4800X와 983 ZET는 QD1에서도 우수한 성능을 보여주며, 각각의 한계에 도달할 때까지 굉장히 낮은, 우수한 지연시간을 유지합니다.
RND 4k Write
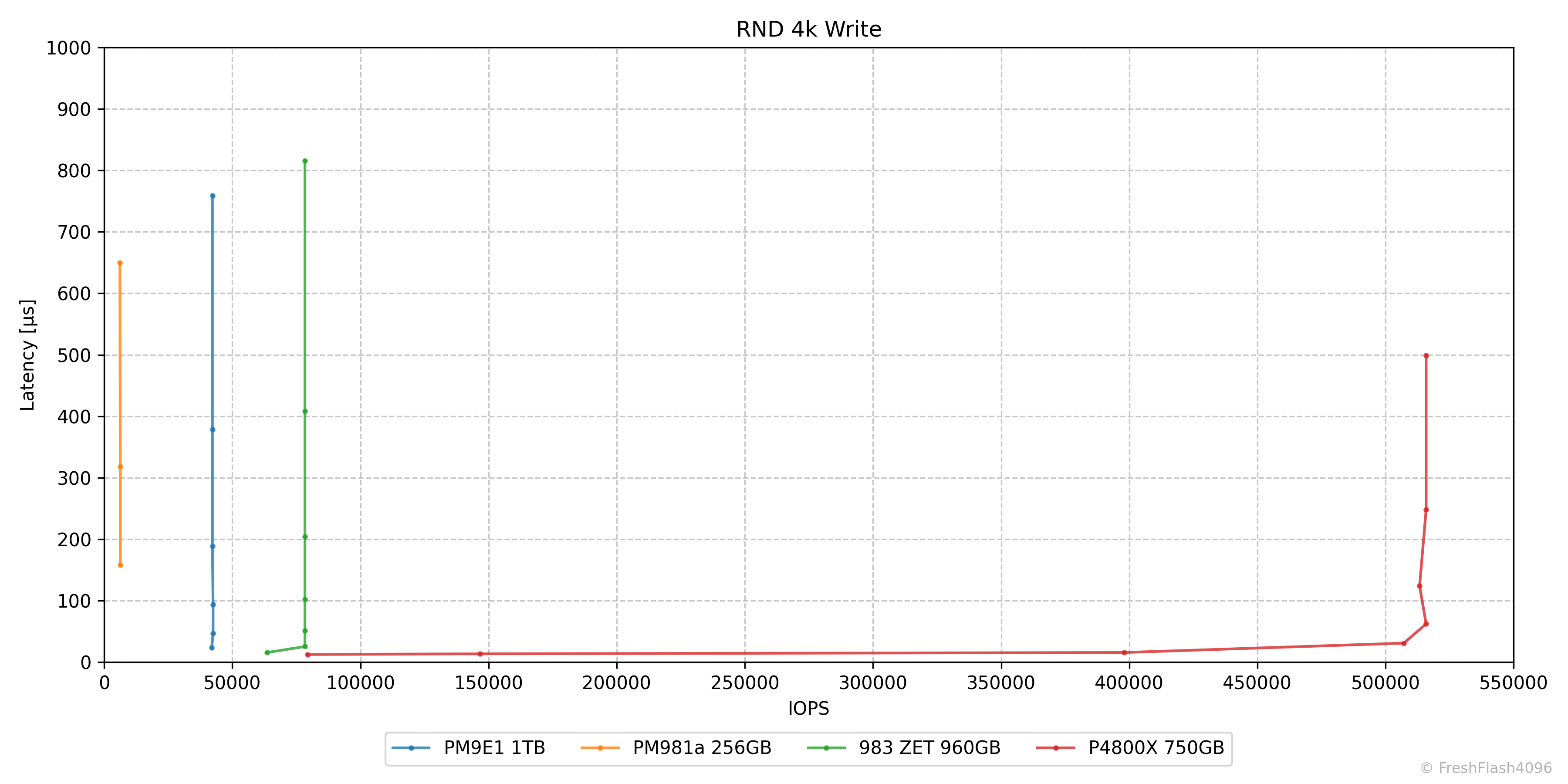
랜덤 쓰기는 Optane SSD의 장점을 잘 보여주고 있습니다. 당장 P4800X의 QD1 성능은 비교군 모두를 압도합니다. 최대 IOPS는 말할 것도 없죠. 오히려 P4800X 때문에 PM981a의 성능을 확인하기가 힘듭니다.
NAND 기반의 SSD들은 QD가 증가해도 IOPS가 크게 달라지지 않는 모습을 보여줍니다.
이 정도면 충분한 예시의 해석을 보여드린 것 같으니, 다음으로 넘어가도록 하겠습니다.
4-Corners Consistency
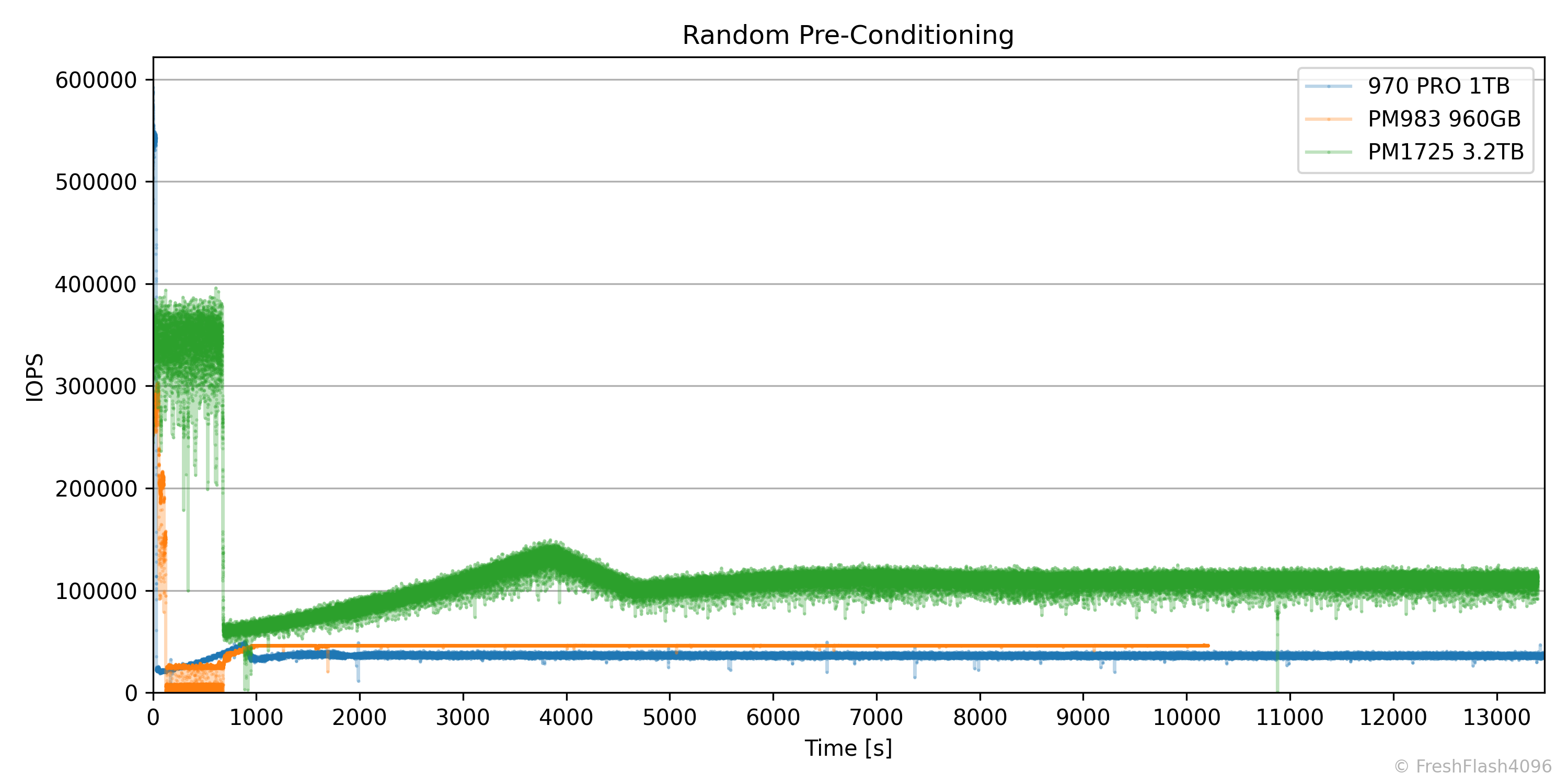
이 그래프는 3가지 SSD에 대한 RND Pre-Conditioning을 진행하는 IOPS-Time그래프입니다. Steady State를 기준으로 어떤 SSD가 가장 성능이 좋을까요? 아마 저를 포함한 대부분의 사람은 다음과 같이 말할 겁니다.
PM1725 3.2TB > PM983 960GB > 970 PRO 1TB
그렇죠. 대부분은 성능을 평가할 때 단순히 최대로 제공할 수 있는 IOPS를 가장 먼저 생각할 것입니다. 하지만 성능 평가의 기준이 IOPS의 변동성, 다시 말해 일관성이 된다면 어떻게 될까요? 애초에 동일한 IOPS로 제한된 상황이 아니기에 평가하기 적절하지 않지만, 단순하게 생각하면 답은 아래와 같이 바뀔 것입니다.
PM983 960GB > 970 PRO 1TB > PM1725 3.2TB
저는 이 일관성의 측정을 위해 4-Corners Performance를 측정할 때, 100ms 단위로 SEQ에서는 Bandwidth 데이터를, RND에서는 IOPS 데이터를 수집합니다. 수집된 데이터는 아래의 계산을 거쳐 Consistency(%)의 값을 결정합니다.
IOPS Consistency (%) = (99.9% IOPS) / (Average IOPS) * 100
Bandwidth Consistency (%) = (99.9% Bandwidth) / (Average Bandwidth) * 100
이제 우린 QD에 따른 4-Corners Performance의 안정적인 정도를 한눈에 확인할 수 있습니다. 아래에서 확인해 보시죠.
DUT ~ 4-Corners Consistency
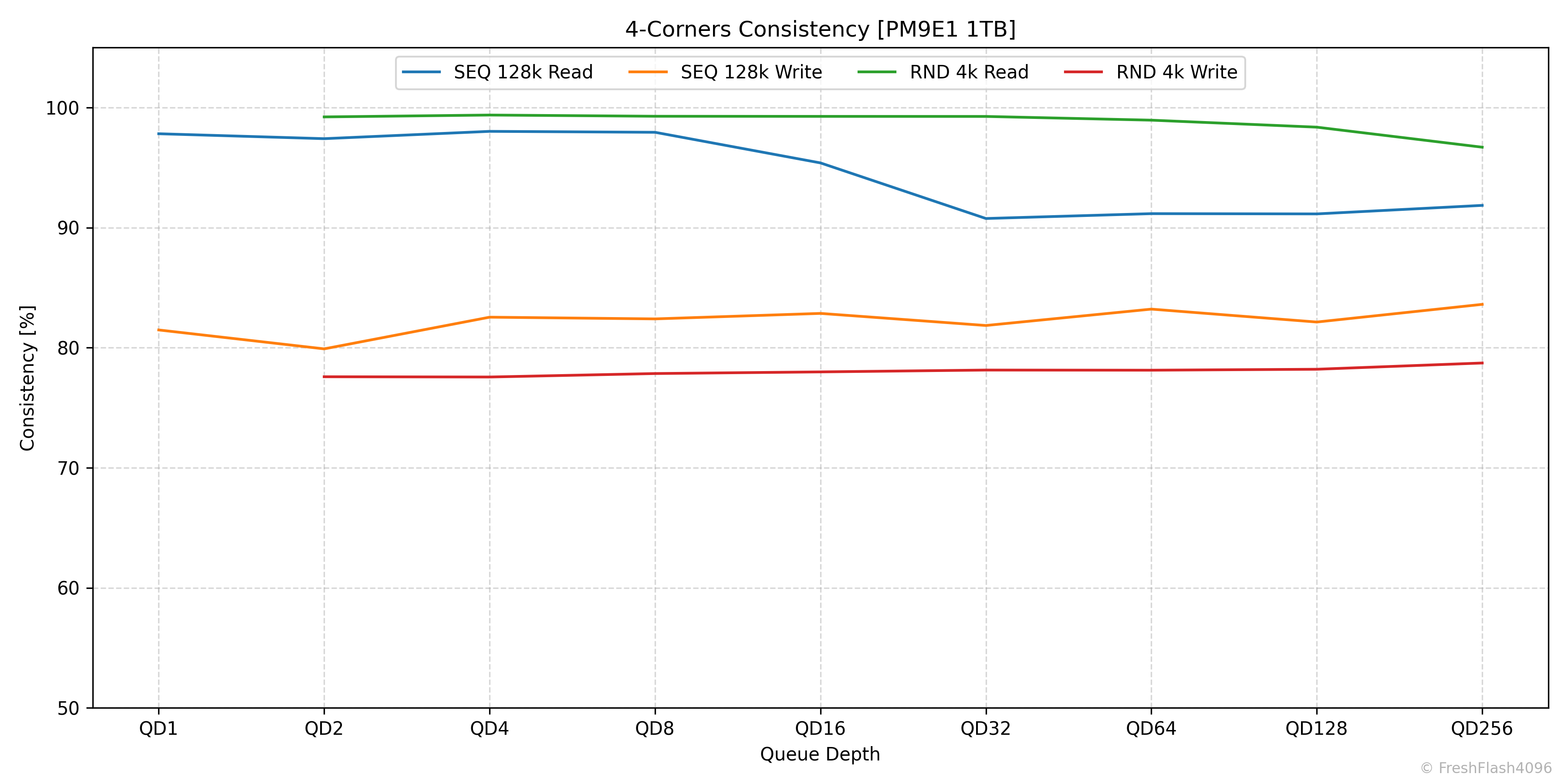
우선, DUT의 4-corners performance에 관한 Consistency를 나타낸 그래프입니다. 이후, 후속작 등을 이유로 비교가 필요한 경우에 한해 아래의 특정 워크로드에 대한 그래프를 제시합니다. (2025.12.01. 추가)
SEQ 128k Consistency
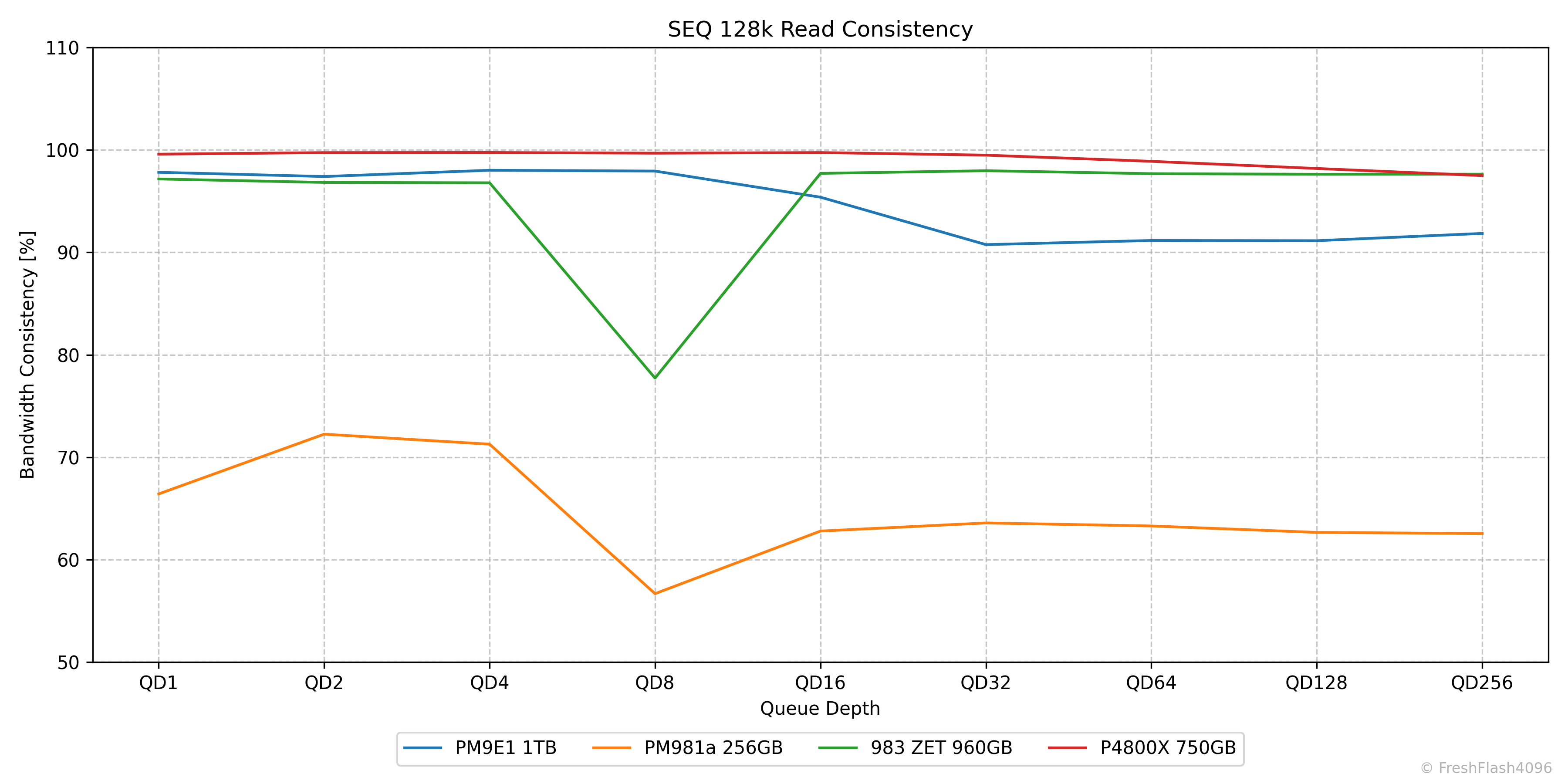
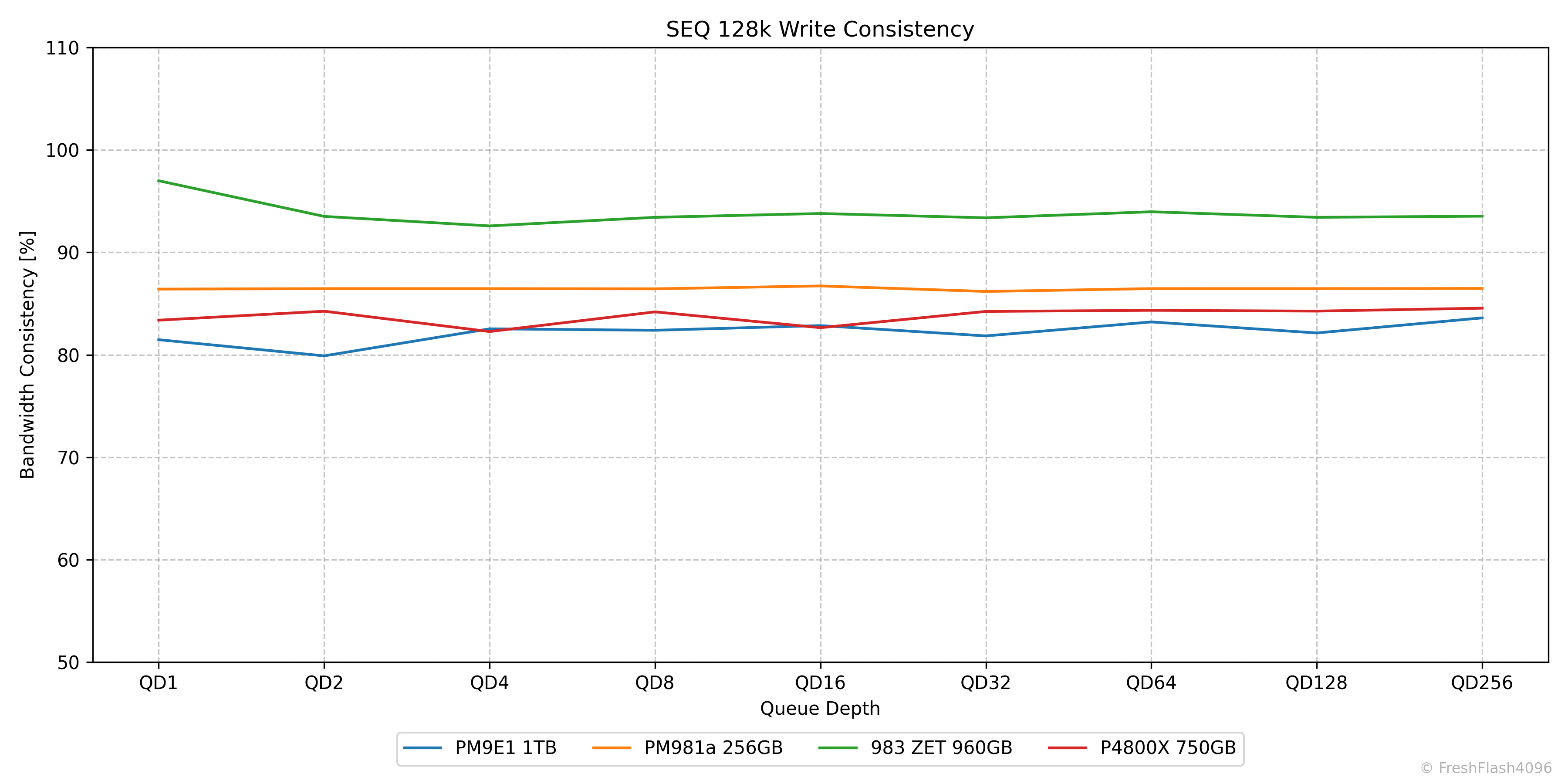
앞서 말씀드린 대로 그래프는 QD1 ~ QD256에서의 Consistency를 나타내며, 이론상 최대치는 100%입니다. Y축을 110%로 고정한 이유는 일부 워크로드나 SSD들에선 99% 이상의 수치를 보여 위쪽에 몰려있기 때문입니다.
RND 4k Consistency
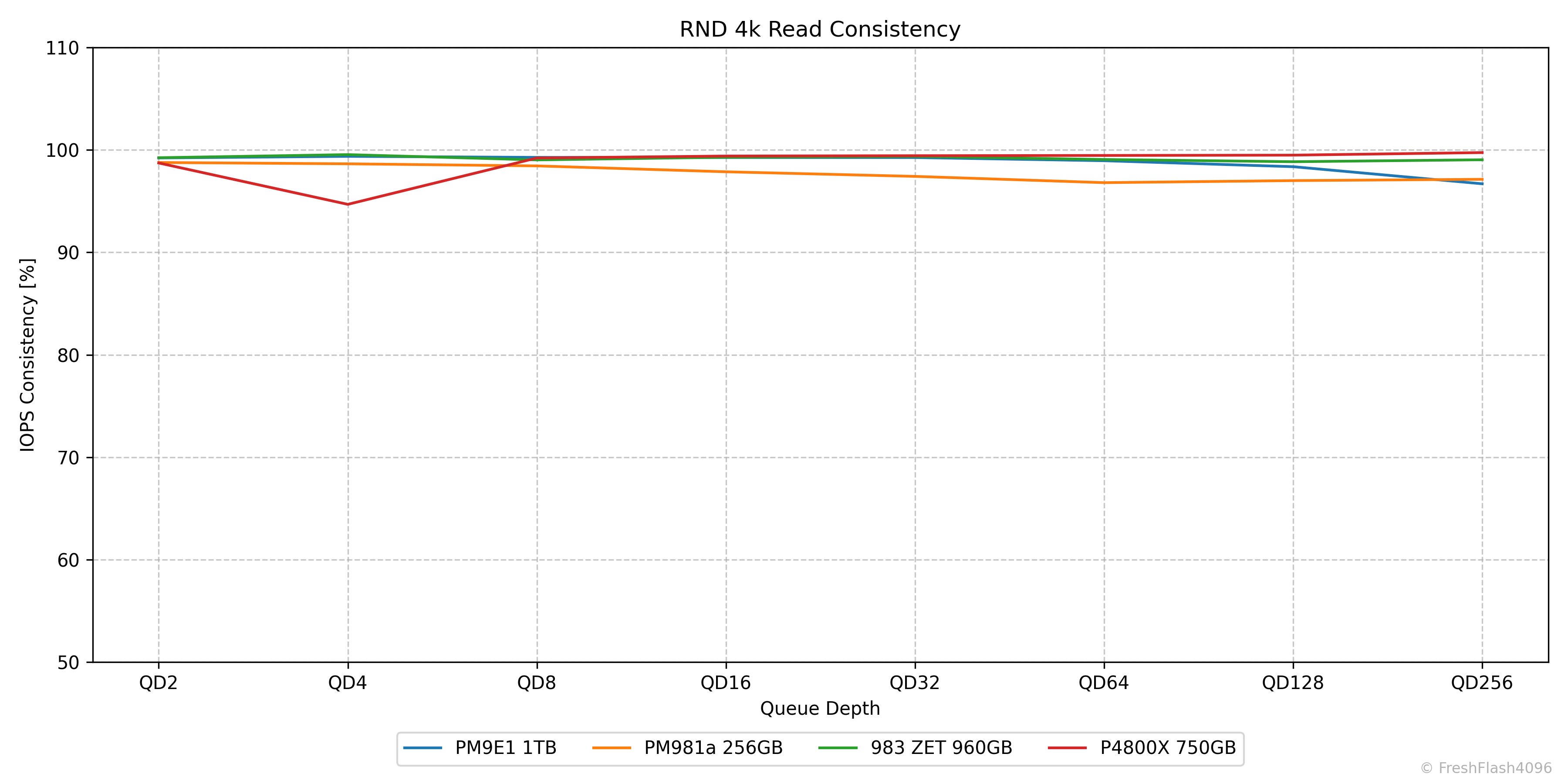
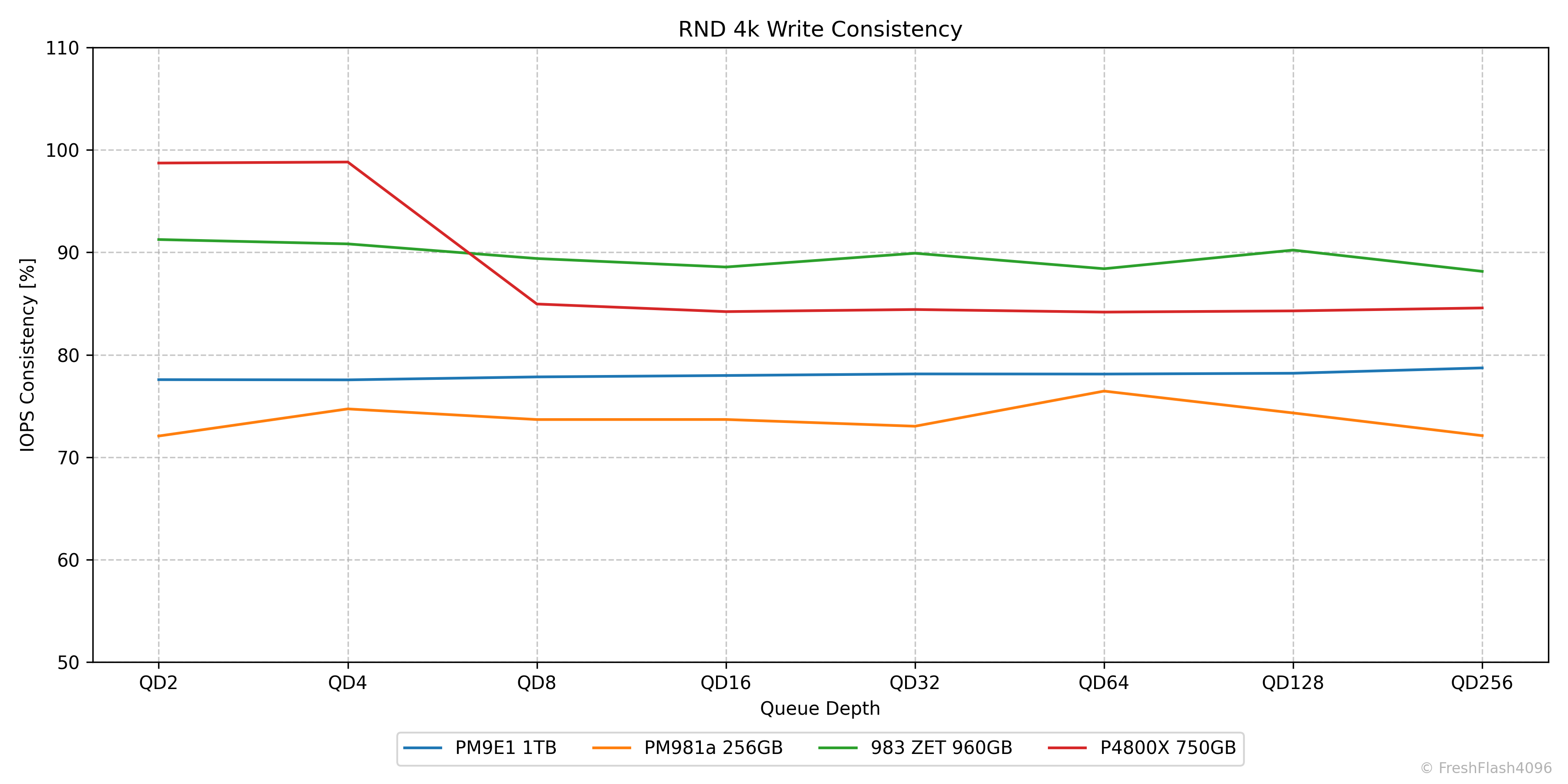
이런 식으로 말이죠. RND 4k Read 워크로드를 확인하면 대부분이 95% 이상의 Consistency를 자랑하고 있습니다. 이전 리뷰들에서는 개별값을 표로 제시하였는데, 그래프가 더 보기 쉬울 것으로 판단하였습니다.
그래프에 값을 표시하는 것도 생각해 보았지만, 몰려있으면 글자도 상당히 파악하기 어려워져 그래프만 제시하기로 했습니다. 정확한 수치에 관심을 가지는 분들이 거의 없을 것 같기도 하고 말이죠. 다만, 데이터시트에 IOPS Consistency 등의 값이 명시되었다면, 정확한 값을 제시하며 비교합니다.
SEQ과 다르게 RND에선 QD1의 Consistency를 명시하지 않았는데, 이는 Tail Latency를 확인하며 더 자세하게 다룰 예정이기에 생략했습니다.
4-Corners Performance & Consistency [IU]
바로 앞에서 진행했던 4-Corners Performance와 Consistency를 다시 분석합니다. 하지만, 이는 특별히 4k IU가 아닌 SSD에 대해서 추가로 진행되는 부분입니다.
What is IU?
IU는 Indirection Unit의 줄임말입니다. 깊고 자세한 것은 다음에 Article로 다루어 보도록 하고, 최대한 간단하게 설명하겠습니다. 우선, 일반적으로 SSD에서 DRAM과 NAND의 비율이 1:1000인 이유를 알아야 합니다.
cSSD 벤치마크의 항목 중 Active Range Test에서도 언급하였지만, SSD에서 DRAM은 NAND의 물리적 주소와 OS가 인식하는 LBA를 변환하는 Mapping Table(L2P Table)을 캐싱합니다. LBA의 크기는 4kiB이며, mapping address는 일반적으로 32bit입니다. 즉, 4Byte에 해당하죠. 다시 말해서, 아래와 같은 식이 성립합니다.
DRAM : NAND = 4Byte : 4kiB= 1:1000
구체적으로는 따질 것이 많지만, 여기서 크게 중요한 요소는 아니기에 생략하겠습니다. 이러한 비율로 cSSD의 용량이라면 충분히 커버가 가능하지만, 최근에 나오는 100TB가 넘는 eSSD라면 100GB 이상의 DRAM이 필요하게 됩니다.
가격도 그렇지만, 물리적으로 PCB에 DRAM을 실장 할 공간이 없다는 것도 문제입니다. 이를 해결하려는 방법의 하나는 DRAM의 용량을 줄이는 것이며, 이는 곧 1:1000의 비율을 깬다는 것을 의미합니다.
4kiB가 아닌 8kiB를 하나로 Mapping을 시행하면 1:2000, 16kiB라면 1:4000이 됩니다. 다시 말해서, 4kiB IU에선 1:1000, 16kiB IU에선 1:4000라고 할 수 있습니다. IU의 의미가 이해되시나요?
이제 실장 할 DRAM의 용량이 줄어 공간의 문제가 해결됩니다. 비용도 줄일 수 있죠. 하지만 대부분의 기술은 trade-off의 관계에 있습니다. 예를 들어, 16kiB IU를 가진 SSD에서 4kiB 쓰기를 시행하면 다음과 같은 작업을 수행합니다.
16kiB 읽기 -> 4kiB 수정 -> 수정 사항이 있는 16kiB 쓰기
우린 4kiB 쓰기를 수행했지만, SSD는 16kiB 쓰기를 수행한 거죠. 이는 수명과 성능에 상당한 영향을 줍니다. WAF(Write Amplification Factor)라는 용어를 아시는 분들은 쉽게 이해가 가실 것으로 생각됩니다.
4-Corners
애초에 4k IU가 아닌 SSD들에 4k 쓰기를 진행하는 것은 너무나도 가혹한 일이며, 전혀 상정되지 않은 사항입니다. 그렇기 때문에 스펙 시트의 검증과 의도된 사용을 위해 IU에 맞춰 4-Corners Performance를 다시 측정합니다.
예시로 들만한 것은 아직 리뷰 준비가 되지 않아 그래프는 생략합니다. 앞서 봤던 4-Corners Performance나 Consistency와 동일한 그래프의 형태입니다.
Specific Workload Performance
앞의 4-Corners Performance에 포함되지 못하는 결과들을 워크로드 별로 분리했습니다. 단, 워크로드 이름은 편의상 붙인 것뿐이며, 실제 환경에서는 다양한 Block Size와 RW 비율이 나타난다는 것을 명심해야 합니다. Block Size들의 정확한 비율과 RW 비율을 결정하기 힘들어 대략 분류한, 가상의 워크로드입니다.
워크로드는 Solidigm의 "Understanding Workload and Solution Requirements for PCIe Gen 4 SSDs"를 참고해 구분했습니다.
Boot Workload (OCP BootBench)
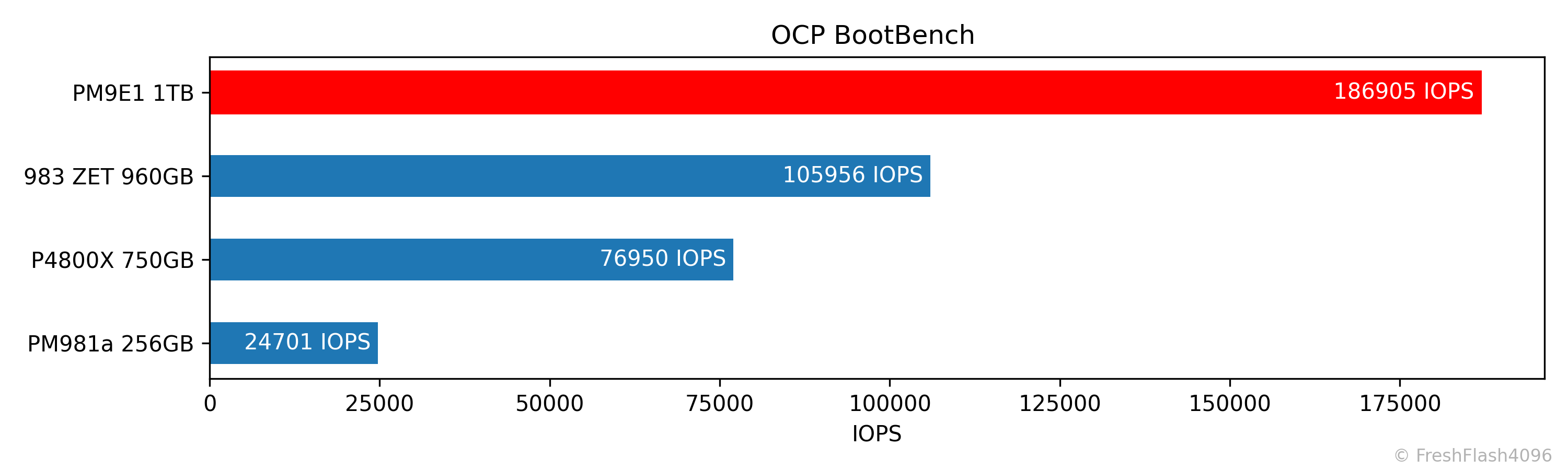
OCP BootBench는 Linux에서 실행되는 벤치마크 중 유일하게 다른 곳에서 가져온 것입니다. 제가 만든 것이 아니라는 뜻입니다. 이 벤치마크는 이름 그대로 Boot 드라이브로서 기대할 만한 성능을 측정합니다.
단, 이때의 Boot 드라이브는 우리가 기대하는 Windows의 C드라이브 같은 것이 아닌, Google이나 Meta와 같은 Hyperscale에서의 Boot 드라이브입니다. 실제로 "OCP HyperScale NVMe Boot SSD Specification"은 성능, 내구성, 기능 등 여러 조건을 담고 있습니다. 비교적 테스트하기 쉬운 성능 부분에서도 Steady State에서의 Bandwidth와 IOPS는 물론이고, 특정 워크로드에 대한 QoS 요구사항도 있습니다.
모든 테스트를 하는 것은 시간적으로도 무리가 있고, 필요성이 떨어집니다. 특정한 워크로드가 있는 것은 좋지만, 모든 것을 테스트할 시간이라면 그냥 어지간한 Block Size에 대해 10% 단위의 R/W성능을 전부 측정하는 것이 더 끌리네요.

하지만, 친절하게도 BootBench라는 벤치마크 도구가 있습니다. 저는 이를 이용해서 최종적으로 출력되는 IOPS를 기준으로 내림차순 정렬을 합니다. 명시된 대로 60k IOPS가 합격 기준입니다.
참고로, eSSD 벤치마크 중에서 유일하게 libaio를 사용하기에, polling을 이용하지 않는 테스트입니다. (2025.11.20. 추가)
Read Intensive Workload (SEQ 128k R95:W05)
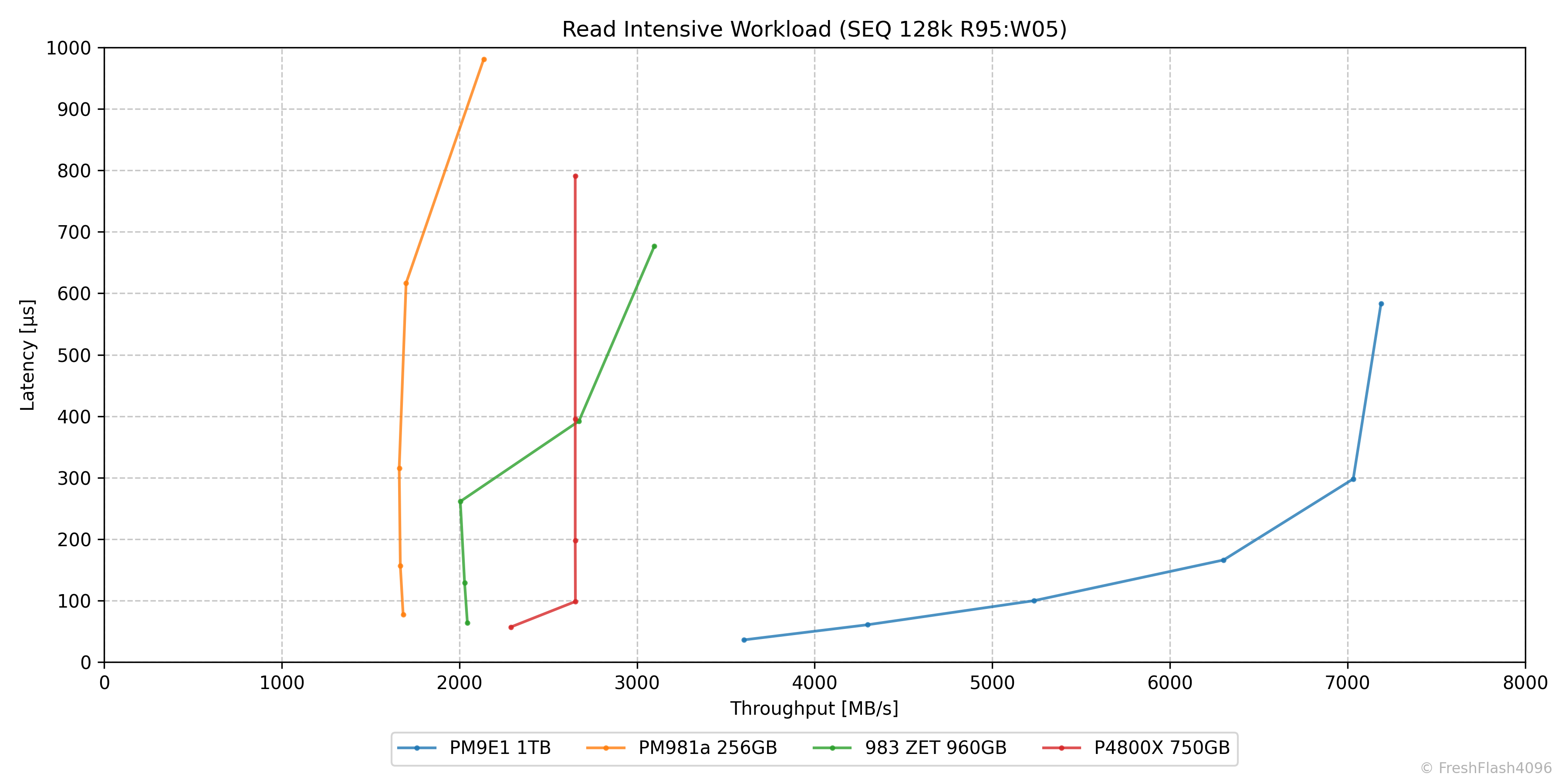
읽기 집약 워크로드는 SEQ 128k Mix 95/5로 세팅했습니다. CDN이나 VOD와 같은 서비스를 가정합니다.
Mainstream Workload (RND 4k R70:W30)
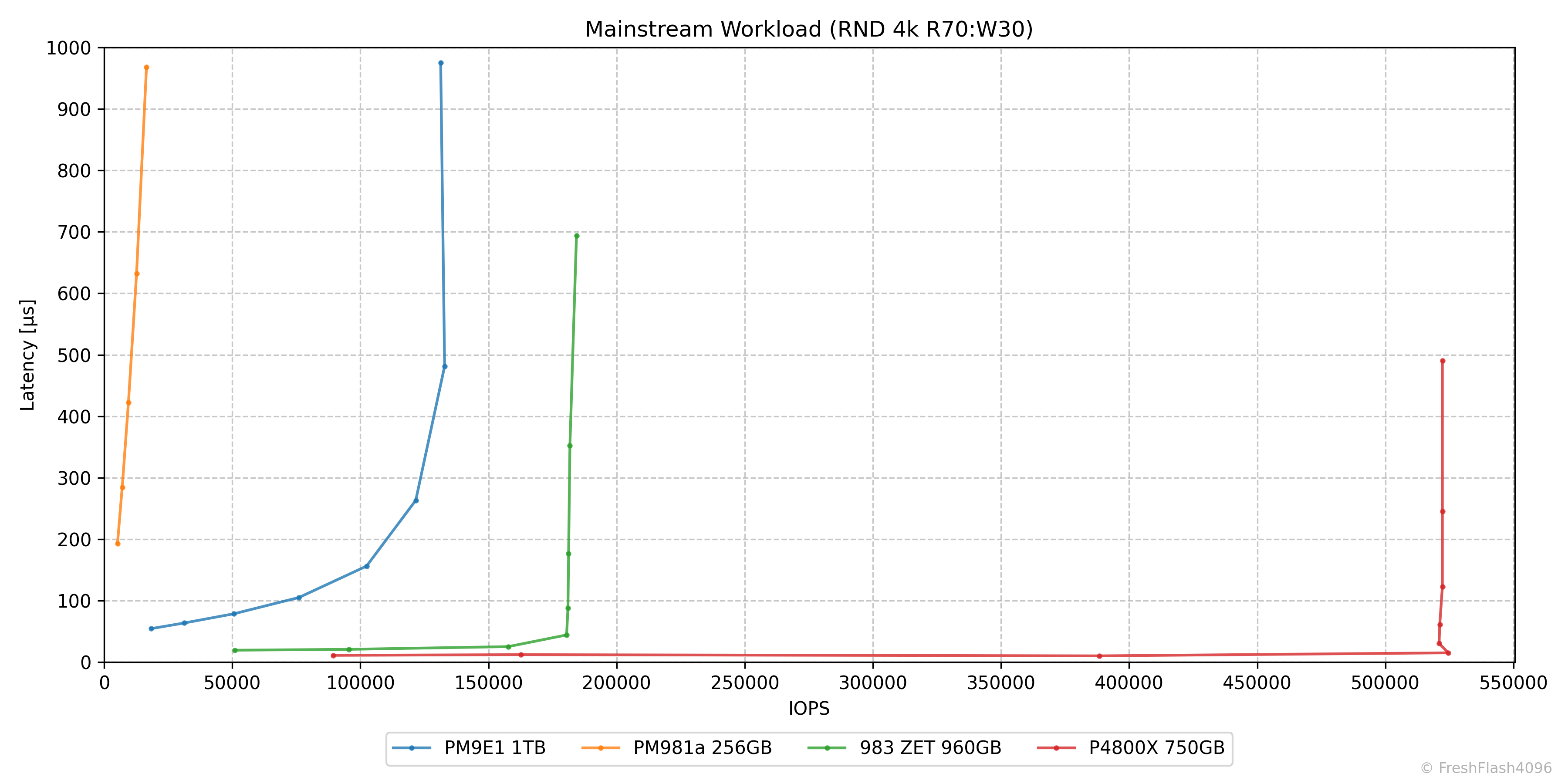
메인스트림 워크로드는 RND 4k Mix 70/30으로 세팅했습니다. HCI에서 단일 VM이 백업 및 재해 복구, VDI, DSS 등을 진행하는 상황을 가정합니다.
Write Intensive Workload (RND 4k R50:W50)
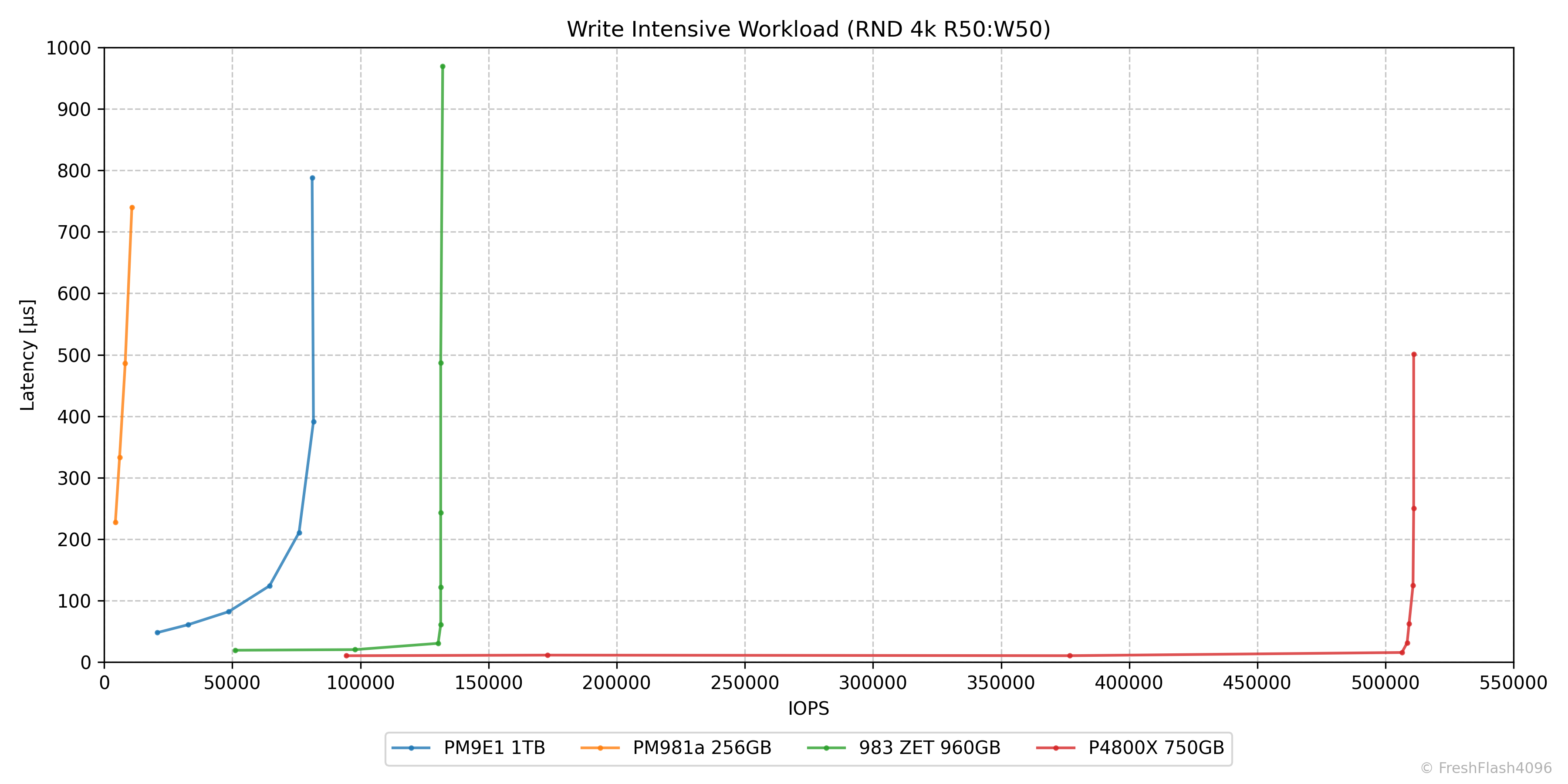
쓰기 집약 워크로드는 RND 4k Mix 50/50으로 세팅했습니다. 데이터 파이프라인에서 라벨링, 압축, 중복 제거 등을 가정합니다.
AI Workload (RND 512B Read)
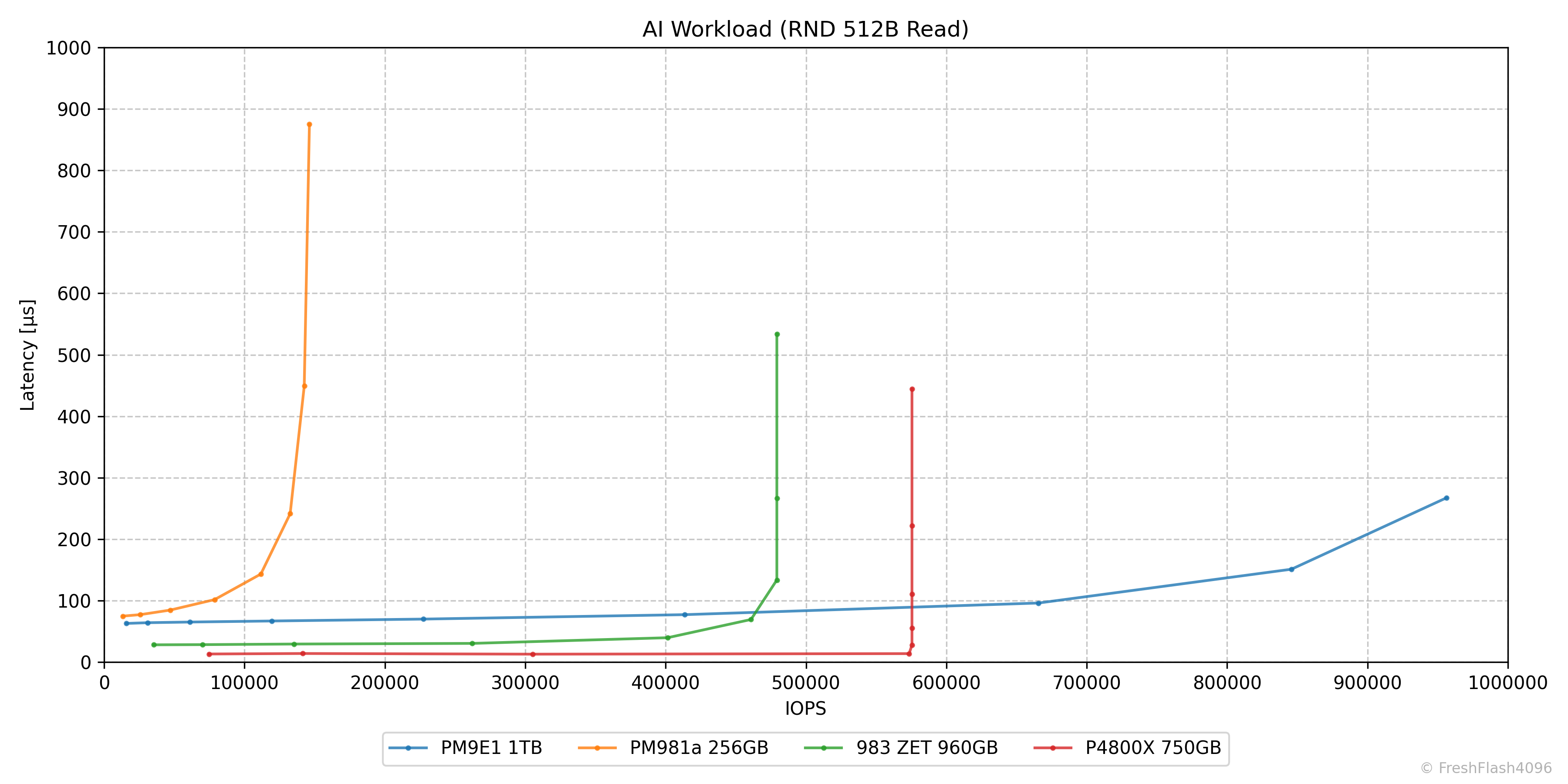
AI 워크로드는 RND 512B Read로 세팅했습니다. NVIDIA의 SCADA(SCaled Accelerated Data Access)관련 벤치마크 결과와 여러 SSD 제조사가 AI와 관련해 집중하고 있는 SSD의 성능이 512B 환경에서의 높은 IOPS를 목표로 하는 것을 염두에 둡니다.
주의할 점은 아니지만, 특이 사항이 하나 있습니다. FIO의 난수 생성기는 기본적으로 32bit Tausworthe Generator로 설정됩니다. 문제는 32bit라는 부분에서 발생합니다. 간단한 계산을 진행해 보죠.
| Offset | Block Size | Offset * BS = Capacity |
| 32bit = 2^32 | 512 Byte (2^9) | 2^41 Byte = 2 TiB |
| 32bit = 2^32 | 4096 Byte (2^12) | 2^44 Byte = 16 TiB |
| 64bit = 2^64 | 512 Byte (2^9) | 2^73 Byte = 8 ZiB |
| 64bit = 2^64 | 4096 Byte (2^12) | 2^76 Byte = 64 ZiB |
표에서 볼 수 있는 것처럼, 32bit에서는 512B BS를 기준으로 최대 2TiB를 커버할 수 있습니다. cSSD만 고려하더라도 부족하죠. 따라서, 512B BS를 사용하는 해당 워크로드에 한정하여 64bit Tausworthe Generator를 사용합니다.
물론, 16TiB 보다 더 큰 용량의 SSD에서는 4k Block Size를 사용하는 워크로드에서도 64bit Tausworthe Generator를 도입할 필요성이 있습니다. 제가 가지고 있는 SSD의 최고 용량은 15.36TB라서 아직은 걱정이 없지만, 추후 도입하게 된다면 명시할 예정입니다.
Random 4k QD1 Tail Latency
마지막은 Tail Latency, Latency에서 가장 느린 구간을 의미합니다. 그렇기 때문에 QoS(Quality of Service)에 큰 영향을 미치죠. 실제로 eSSD의 데이터시트에서는 QoS를 명시하고 있습니다.
여기에선 100ms나 10ms 단위가 아닌, 모든 개별 I/O에 대한 지연시간을 카운트하여 그래프를 그립니다. 그렇기 때문에 데이터가 상당히 방대해, 이 항목은 QD1에 대해서만 진행합니다. 실제로 여러 QD를 대상으로 이 정보를 수집했더니, DUT보다 로그 용량이 더 커지는 불상사가 발생했습니다. 다시 떠올려도 웃기네요.
본문의 가장 위에 게시된 이미지를 참고하면 알 수 있겠지만, 로그 데이터들의 용량이 좀 큰데, 대부분은 이것입니다. 또한, 로그 데이터들은 원격지에 있어 그래프를 하나 그리는데 5분 이상 소모됩니다. 길게는 10분, 15분까지도 걸리는 것을 확인했습니다. 그래프 그리는 코드를 리팩토링할 필요성이 있어보입니다...
결과물은 직접 보시는 게 좋을 것 같습니다. 설명은 그 후로 미룰게요.
Result Graph @ QD1
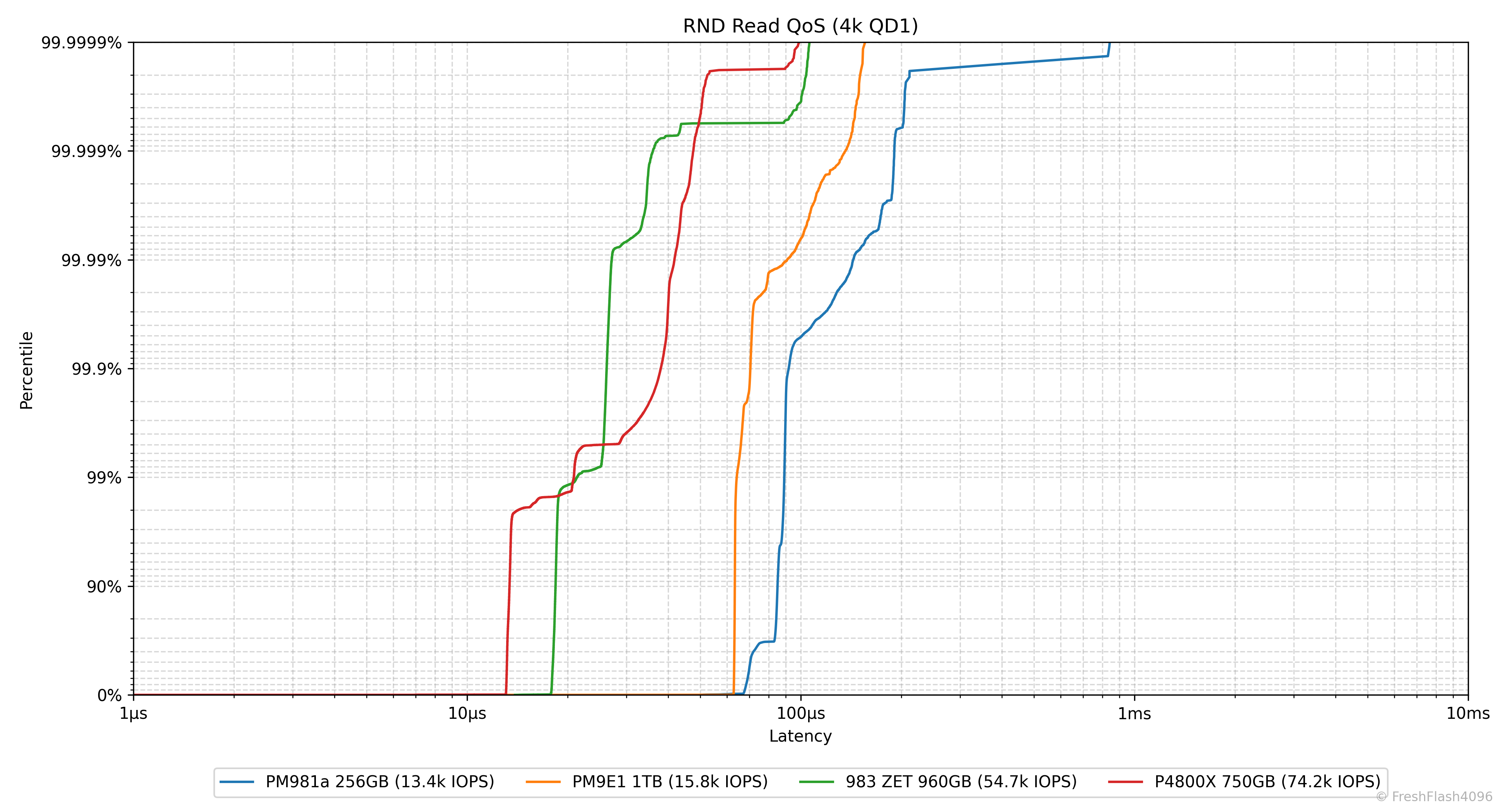
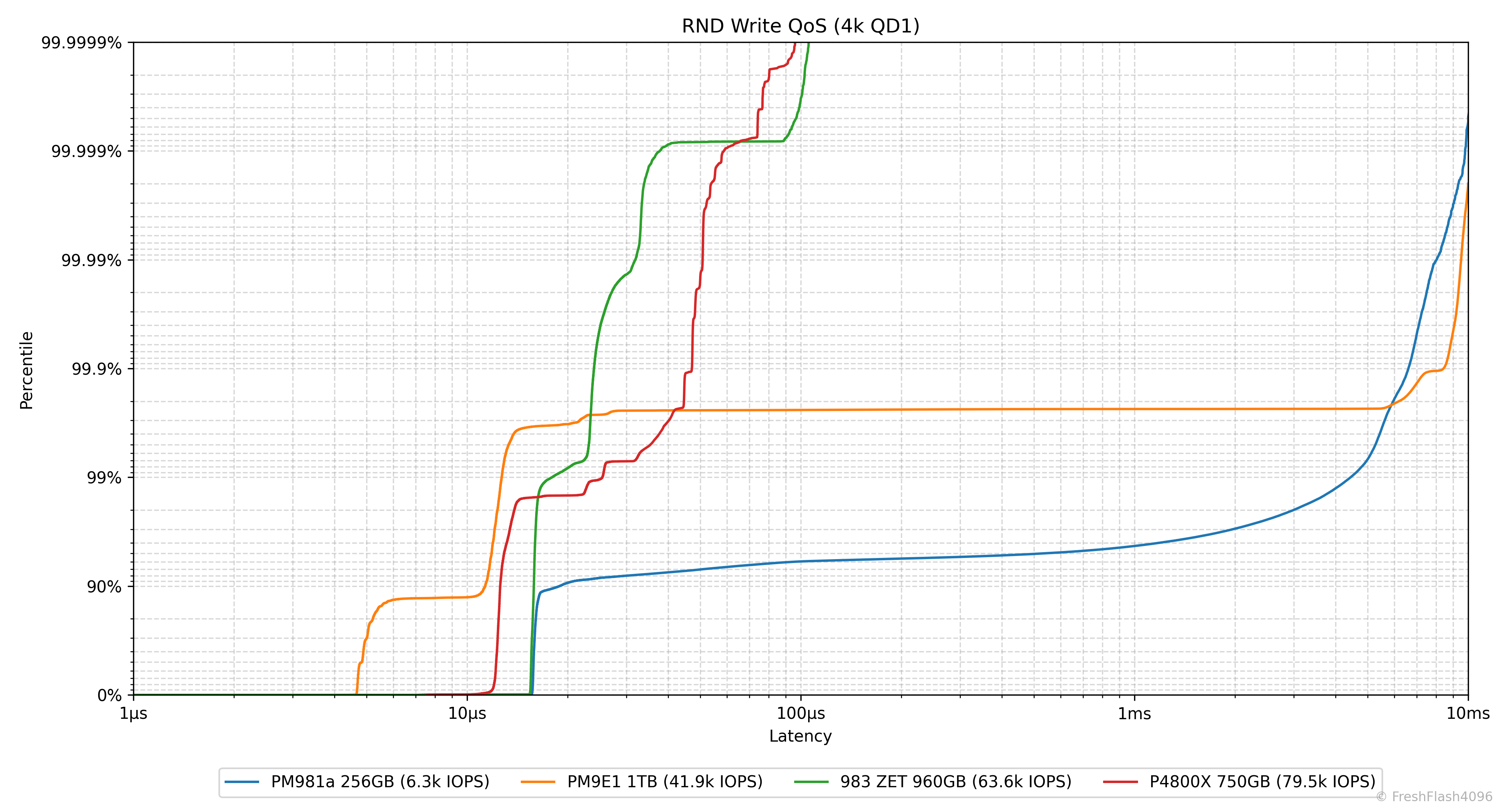
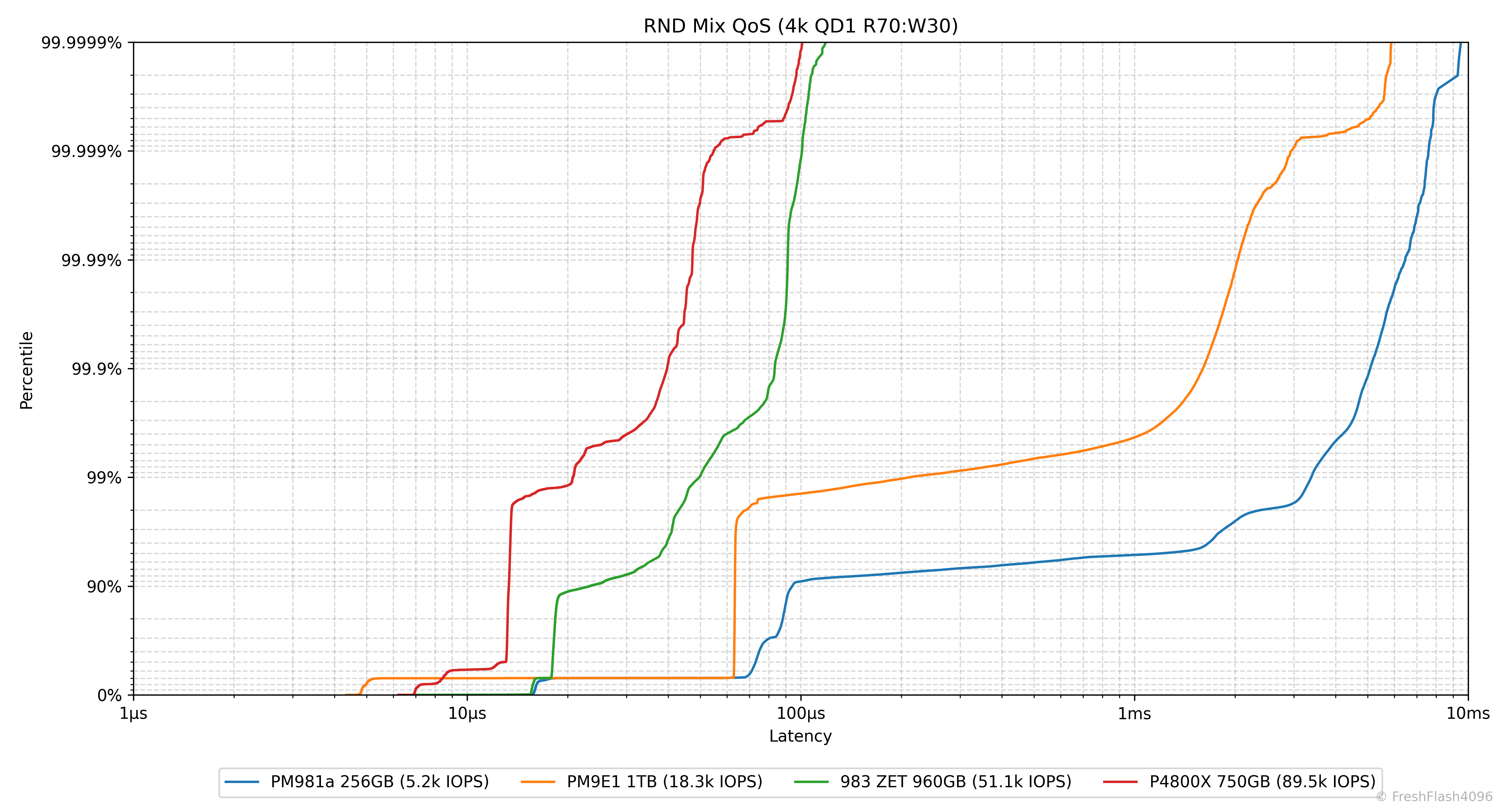
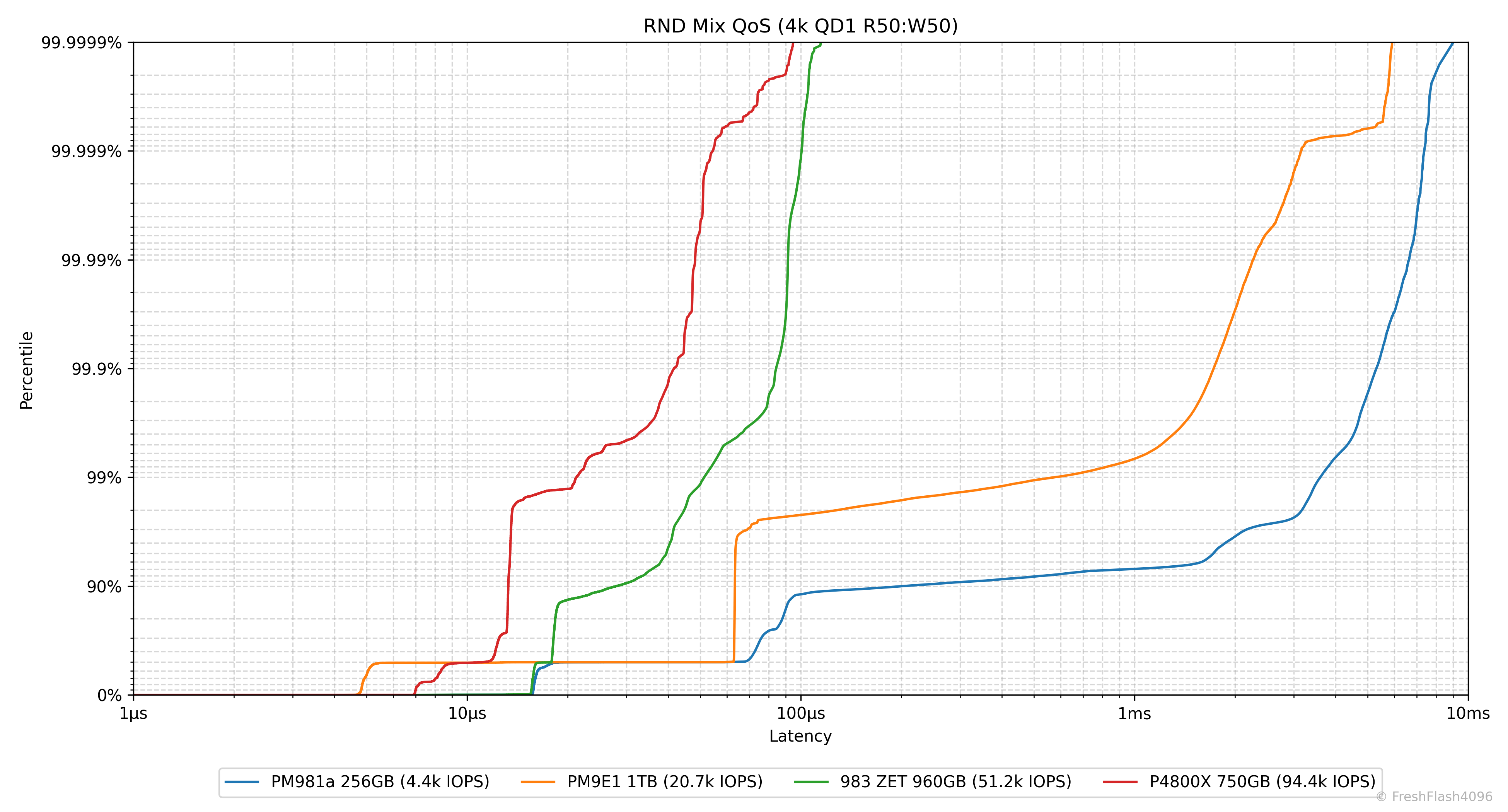
다 보셨나요? 그럼 한 번 뜯어봅시다.
우선, X축은 Latency를 나타냅니다. 1µs부터 시작해 10ms까지 있는 것을 확인하실 수 있는데, 짐작하신 대로 Log scale입니다. Y축은 Percentile, 백분위수를 나타냅니다. 위로 갈수록 늘어지는 지연시간이 위치해 있는데, 이것도 Log scale입니다.
0 ~ 90%, 90 ~ 99%, 99 ~ 99.9%, ... 99.999 ~ 99.9999% 까지, six-nine Latency까지 데이터를 제공합니다. 상단을 0%로, 하단을 99.9999%로 해야 하나 망설였는데, Y=X에 가까운 그래프가 마음에 들기도 하고, 조금 더 직관적으로 파악할 수 있지 않을까? 라는 기대에서 착안했습니다.
eSSD의 데이터시트를 검증하고자 하면, 특정 Percentile 지점이 어떤 Latency 값을 가지는지 확인하면 됩니다. 이외에도 이 그래프에서는 수직선에 가까울수록 강한 일관성을 나타냅니다.
예를 들어, PM981a나 PM9E1은 위쪽으로 갈수록 지연시간이 늘어나지만, P4800X와 983 ZET는 99.9999%까지 확인해도 100µs 부근에 위치하고 있습니다. QoS관리가 굉장히 잘되고 예측 가능하다는 뜻이죠.
우리가 앞에서 보았던 IOPS Consistency 등의 지표와는 명백하게 다릅니다. BW/IOPS Consistency를 계산할 때는 99.9%의 백분위수를 이용했다는 것을 명심해 주세요. QD1이라는 환경에 한하여 담긴 정보는 비교도 되지 않을 정도로 이쪽이 훨씬 풍부합니다.
그 밖에도 그래프가 좌측에 위치할수록 전체적인 지연시간이 낮다는 것을 알립니다. 다만, IOPS가 통일되지는 않았기에 참고용으로 범례에 4k@QD1의 IOPS를 명시하고 있습니다.
Closing
사실, 개인적으로 사용하는 내부용 그래프는 조금 더 있습니다. 그 중 하나가 바로 위의 QoS 그래프입니다. QD별로 50%, 90%, ... 99.9999%에 대응하는 지연시간을 나타내죠. 하지만, 아마 리뷰에서는 제시할 일이 없지 싶네요.
일반적으로 다른 리뷰과 비교한다면, 보다 더 많은 양의 내용과 그래프가 담긴 것이 제 리뷰의 특징이 아닌가 싶습니다. 그런데도 시행하고 싶은 벤치마크가 더 많은데 시간, 자본, 지식이 부족하다는 것이 느껴져 너무나 아쉽습니다.
혹시라도 모든 것이 충족되는 분들을 위해 제가 고민했던 것들과 수행하지 못한 것들을 몇 가지 소개하고자 합니다.
- 특정하게 주어진 IOPS에 따른 지연시간을 측정 및 비교하기.
- Tail Latency 측정에서 한계를 느끼고 고안되었던 벤치마크입니다.
- 다만, 주어질 IOPS 값에 대한 아이디어가 부족해 미루게 되었습니다.
- 실제 워크로드(VDI, CDN 등)에 맞게 BS, SEQ/RND, R/W 비율을 조정해 합성 벤치마크 진행하기.
- 이 부분도 제가 정확하게 파악하고 있는 워크로드의 지표가 없기에 미루게 되었습니다.
- JESD219라는 선택지도 고민해 보았는데, 아무래도 발표된 지가 좀 오래되었고, 현재 상황과는 꽤 차이가 있다고 생각해 리뷰에는 넣지 않았습니다.
- GDSIO, GPUDirect Storage Benchmarking.
- 3DMark 벤치마크에서도 언급했지만, SSD 리뷰를 하나 진행하자고 GPU를 구매하는 것은 아무래도 상당히 부담되는 일입니다.
- 제 테스트 플랫폼이 mITX이기도 하여, dGPU를 설치하면 DUT가 될 SSD를 설치하는 것도 또 다른 문제입니다.
- Data Retention
- SSD의 보증 TBW에 해당하는 만큼의 쓰기를 가한 뒤, 전원을 끄고 일정 시간이 지난 후 무결성 검사와 읽기 성능의 측정을 진행합니다.
- 위 상황에서 가하는 쓰기는 이상적인 WAF를 상정해 128k 순차로 가득 채워도 괜찮지만, 클라이언트 워크로드를 분석하고 그를 따르는 것도 좋을 것 같습니다.
- 하지만, 이 항목은 테스트할 때마다 SSD 하나를 버리는 것과 같으며, 시간도 상당히 오래 걸립니다. 그 외에도 여러 이유로 기각되었습니다.
- Real World Workload
- 엔터프라이즈에 초점을 둔 2번과는 다르게, 많은 클라이언트의 실제 워크로드를 뽑고 분석하여 트레이스 기반의 벤치마크를 하나 제작하려고 했습니다.
- 몇십 명 정도의 데이터가 있으면 좋겠는데, 현실적으로 불가능하다고 판단하여 포기했습니다.
- 온도 측정
- 온도 측정은 비교적 쉽다고 말씀하시는 분들도 계실 것 같습니다. 당장 S.M.A.R.T.로 읽어올 수도 있으며, 더 자세하게 하고 싶다면 열화상 카메라를 구매하면 되겠죠.
- 하지만, 실제로는 "환경의 통일"이라는 부분에서 상당히 어려움을 겪습니다.
- 외부 온습도, S.M.A.R.T.의 온도 계산 방식, 공기의 흐름, 방열판이 가하는 압력...
- 꿈도 희망도 없는 것 같지만, 사실 다른 방법이 있습니다.
- 전력 측정
- 꿈과 희망이 넘치는 전력 측정입니다. 전력 소모는 발생하는 열을 의미하니까요.
- 최대한 정확한 측정을 위해서는 꼼수를 부리지 말고, 아주 잘 제작된 플랫폼인 Quarch Technology사의 제품을 이용하는 게 좋습니다. FIO와 연동해 자동화도 가능하거든요.
- 가격을 슬쩍 알아봤더니, 조금 무리가 되는 부분이었습니다.
- 로또 당첨되면 구해올게요.
이것이 당장 떠오르는 전부입니다. 이번 주 로또에 당첨되면 전력 측정 장비를 바로 구해오겠습니다.
뜬금없지만, 현재 NAND 공급의 상당수를 대한민국 기업이 담당하는 것에 대해서 저는 어느 정도 뿌듯함이 있습니다. (SK hynix가 Solidigm을 매각한다고 해도) 그런데, 커뮤니티를 둘러보면 정작 NAND를 이용한 제품인 SSD의 리뷰가 좀 아쉽다고 해야 할까요.
제가 하는 방법이 답이며 다른 리뷰들은 잘못되었다고 주장할 생각은 없습니다. 인지하고 있는 한계점도 명확하게 존재하고, 저 자신이 잘 안다고도 말할 수 없으니 말이죠. 또한, 대부분은 광고를 받아와야 할 테니 광고주의 의향도 존재할 것이고, 이는 필드 테스트나 개인 광고를 받는 리뷰어, 유튜버들도 해당할 것입니다. 그 부분을 감안하더라도, 상세함이 부족하고, 고려하지 않은 통제 사항, 기존에 있는 여러 유명한 도구만을 이용해 도출되는 결과로 리뷰를 진행하는 것은 마음이 아픕니다.
물론, 다른 사람들이 관심도 크게 안 가지는데 시간이랑 돈을 스스로 축내는 제가 이상한 쪽이 아닐까, 가끔 생각은 합니다.
Steady State를 측정하라는 말은 아닙니다. 이건 엄연히 엔터프라이즈 워크로드이니까요. cSSD에 Steady State를 요구하는 쪽이 이상한 것이죠. 그저, FOB상태에서 진행했는가, 벤치마크 도구를 여럿 사용하는데 이 사이에는 충분한 휴식 시간을 부여했는가, Purge는 수행하였는가, 벤치마크의 순서는 어떻게 되는가 등의 설명이 전혀 없다는 것이 아쉬웠습니다. 하드웨어 플랫폼만 명시해 둔 게 대부분이었으니 말이죠. 그래프를 그릴 때 축의 의미를 명시하지 않는 것도 참 안타까웠습니다.
시작은 제 리뷰가 국내 저장장치 리뷰어에게 자극이 될 수도 있지 않을까, 라는 기고만장한 생각이 계기였습니다. 이제는 그냥 자기만족과 호기심일 뿐이지만요. 그래도 누군가는 제 리뷰를 재미나게 읽을 것으로 생각합니다.
지금까지 길고 길었던 제 벤치마크 방법론이었습니다. 업로드 주기는 길 것 같지만, 앞으로도 많은 리뷰 기대해 주세요.
Reference
제가 고민하며 참고한 자료들의 극히 일부를 순서없이 정렬한 것 입니다. 이외에도 FMS나 USENIX의 발표자료나 여러 논문, 많은 SSD의 데이터시트들을 참고했습니다. 지나가다가 본 문서들은 생략되어 있기에, 그들을 찾게된다면 이후에도 추가될 수 있습니다.
- OCP Datacenter NVMe SSD Specification
- ezFIO User Guide
- OCP Hyperscale NVMe Boot SSD Specification
- JEDEC STANDARD Solid-State Drive (SSD) Requirements and Endurance Test Method (JESD218)
- JEDEC STANDARD Solid-State Drive (SSD) Endurance Workloads (JESD219)
- OCP NVMe Cloud SSD Specification
- Intel Performance Benchmarking for PCIe* and NVMe* Enterprise Solid-State Drives
- Solidigm PC Storage Performance in the Real World
- Micron SSD Performance States
- Intel Partition Alignment of Intel SSDs for Achieving Maximum Performance and Endurance
- Understanding SSD Performance: Using the SSS PTS to Evaluate and Compose SSD Performance
- Understanding SSD Performance Using the SNIA SSS PTS Performance Test Specification
- SNIA Solid State Storage Performance Test Secificatoin
- fio - Flexible I/O tester rev. 3.38
- Understanding datacentre workload quality of service
- JEDEC MasterTrace_128GB-SSD
- JEDEC TestTrace_64GB-128GB-SSD
- Intel Optane Solid State Drives for Client Evaluation Guide
- Intel Optane Solid State Drive DC P4800X (Linux) Performance Evaluation Guide
- NVM Express Base Specification
- Intel Optane Solid State Drive DC P4800X Series (Windows) Performance Evaluation Guide
- Intel Optane Solid State Drive DC P4800X (VMware) Performance Evaluation Guide
- Red Hat Enterprise Linux 8 Document
- Lies, Damn Lies And SSD Benchmark Test Result
- Jisoo Yang, "When Poll Is Better than Interrupt", FAST '12
- Zebin Ren, "Performance Characterization of Modern Storage Stacks: POSIX I/O, libaio, SPDK, and io_uring", CHEOPS '23
- Roger Corell, "Understanding Workload and Solution Requirements for PCIe Gen 4 SSDs", White Paper
- John Kariuki, "Improved Storage Performance Using the New Linux Kernel I/O Interface", SDC 2019
- Gyusun Lee, "Asynchronous I/O Stack: A Low-latency Kernel I/O Stack for Ultra-Low Latency SSDs", ATC '19
- Sungjoon Koh, "Faster than Flash: An In-Depth Study of System Challenges for Emerging Ultra-Low Latency SSDs", 2019 IISWC
- Diego Didona, "Understanding Modern Storage APIs: A systematic study of libaio, SPDK, and io_uring", SYSTOR '22
- Amber Huffman, "NVM Express: Optimized Interface for PCI Express* SSDs", IDF13
- "Intel® Solid-State Drive DC S3700 Series – Quality of Service", Technology Brief
- Damien Le Moal, "I/O Latency Optimization with Polling", Vault Linux Storage and Filesystems Conference 2017
- Vikram Sharma Mailthody, "Advancing Memory and Storage Architectures for Next-Gen AI Workloads", FMS 2025

Comments