
헬로!! 금빛 하이닉스 [P31 2TB]
P31은 SK hynix라는 기업을 일반 소비자들에게 알린 하나의 상징적인 제품입니다.
P31이 출시된 2020년 ~ 2021년을 살펴보면, PCIe 3.0 SSD가 많은 제조사에서 진작 출시된 상태였으며, 대표적으로 Samsung 970 EVO Plus는 2019년에 출시된 것을 확인할 수 있습니다. 제가 컴덕질을 시작했을 때 이미 970 EVO Plus가 보급되고 있던 것을 생각하면, 개인적으로는 오래된 느낌이 드는 SSD입니다.
그럼에도 불구하고 여전히 높은 관심을 받고 있는 제품인데, 이는 저전력 NVMe SSD로 널리 알려졌기 때문입니다. 이 말이 2026년에도 유효한가의 검증은 전문적인 장비를 사용하지 않으면 어렵기에 본 리뷰에선 생략하겠지만, 성능적인 측면에선 항상 하던대로 다뤄 보겠습니다.
바로 시작하죠.
목차
Appearance

Gold P31이라는 이름에 걸맞게 금색이 강조되어 있습니다.

후면에는 간단한 정보와 함께 제가 부착한 국내 유통 스티커가 보입니다. 보증이 충분히 남아있으니 분해는 넘어가겠습니다. 저는 전문 리뷰어가 아니라 일반 소비자니까요.
실례가 되지 않는다면 샘플을 빌려주세요 제조사님들.
Datasheet
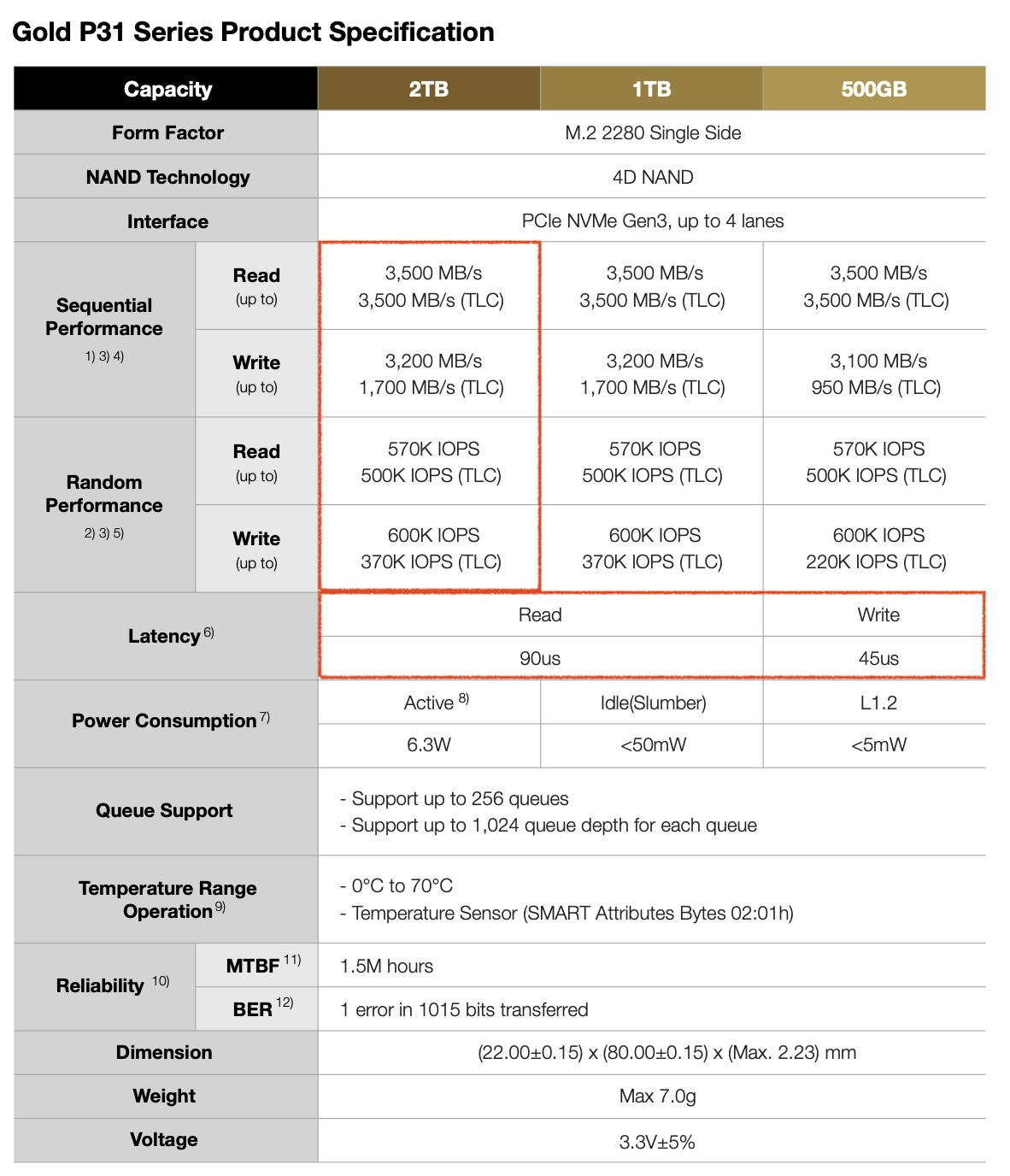
약간 특이하게 TLC의 성능도 기입되어 있습니다. 다만, 일반적인 사용에서 TLC에 직접 쓰는 속도는 확인할 일이 없으리라 생각됩니다. 아래 Fill Drive 파트를 확인하면 이해가 될 것 같네요.
MTBF나 BER 등의 수치는 일반적인 cSSD를 따릅니다. 그러고보니 필기 시험에서 MTBF 관련 문제가 출시되지 않았던 것 같네요.
Notable Points
Platinum P31

사실, 1TB 까지의 용량은 Gold P31로 먼저 나오고, 2TB 제품은 Platinum P31로 나올 예정이었습니다.
하지만, 최종적으로 Platinum 네이밍은 PCIe 4.0 기반의 제품인 P41에 달아주었고, P31 2TB는 기존 제품들과 동일하게 Gold P31로 출시되었죠.
그 과정에서 소소하게 P31의 PCB 색상도 초록에서 검정이 되었습니다.
SW Report
좌측 이미지처럼 새제품이었습니다. 제 손에 걸리면 닳지만요.
smartmontools와 NVMe-CLI의 id-ctrl 결과는 GitHub에 첨부하도록 하겠습니다.
DUT Summary
벤치마크를 진행할 SSD에 관한 요약입니다.
SK hynix Gold P31 2TB [SHGP31-2000GM] | |||
| Link | PCIe 3.0 x4 | NVMe Version | NVMe 1.3 |
| Firmware | 31060C20 | LBA Size | 512B / 4096B |
| Controller | SK hynix Cepheus 2 | Warning Temp | 83 °C |
| Storage Media | SK hynix 128L TLC | Critical Temp | 84 °C |
| Power State | Maximum Power | Entry Latency | Exit Latency |
| PS0 | 6.3000 W | 5 μs | 5 μs |
| PS1 | 2.4000 W | 30 μs | 30 μs |
| PS2 | 1.9000 W | 100 μs | 100 μs |
| PS3 | 0.0500 W | 1000 μs | 1000 μs |
| PS4 | 0.0040 W | 1000 μs | 1000 μs |
분해는 하지 않았지만, P31의 구성은 잘 알려져 있습니다. 제가 알고 있는 내용을 기입하였는데, 컨트롤러를 강조하고 싶네요.
Cepheus 2는 4채널 컨트롤러입니다. 일반적으로 플래그십 cSSD에 들어가는 컨트롤러가 8채널이란 것을 생각하면, 저전력인 이유도 납득이 될 것입니다. 경쟁사에 비해 출시가 늦었기에 가능했다고도 할 수 있겠죠. 참고로, P41과 P51에 사용된 컨트롤러는 8채널입니다.
HMB와 FTL 등이 발전하며, 최신의 4채널 컨트롤러들은 더 이상 DRAM을 달지 않습니다. 가격과 전력적인 측면에서 굳이 손해를 보며 보급형에서 DRAM을 고집할 필요가 없는 것이죠. 아쉽게도 이러한 DRAMless SSD는 일부 저급 제품으로 인해 여전히 저평가되고 있는데, 아쉬운 일입니다.
반대로, DRAM이 실장된 4채널 컨트롤러를 사용한 P31은 여전히 고평가를 받고 있습니다. 개인적으로는 기분이 참 묘합니다. 다른 조건이 동일할 때, DRAM이 실장되었다는 점은 성능적인 이점을 가져오지만, SSD는 계속해서 발전하고 있습니다. 성능은 물론이고, 전력 효율적인 부분도 재고할 필요가 있다고 생각합니다.
Comparison Device
비교군은 아래와 같습니다.
| Name | Why? |
| P51 2TB [61060A50] | SK hynix의 최신 플래그십 cSSD |
| 970 PRO 1TB [1B2QEXP7] | 경쟁사의 PCIe 3.0 플래그십 cSSD |
| P3 Plus 2TB [P9CR40D] | 보급형 PCIe 4.0 cSSD (QLC + DRAMless) |
P41은 데이터가 없기에 P51을 들고왔습니다.
Test Platform
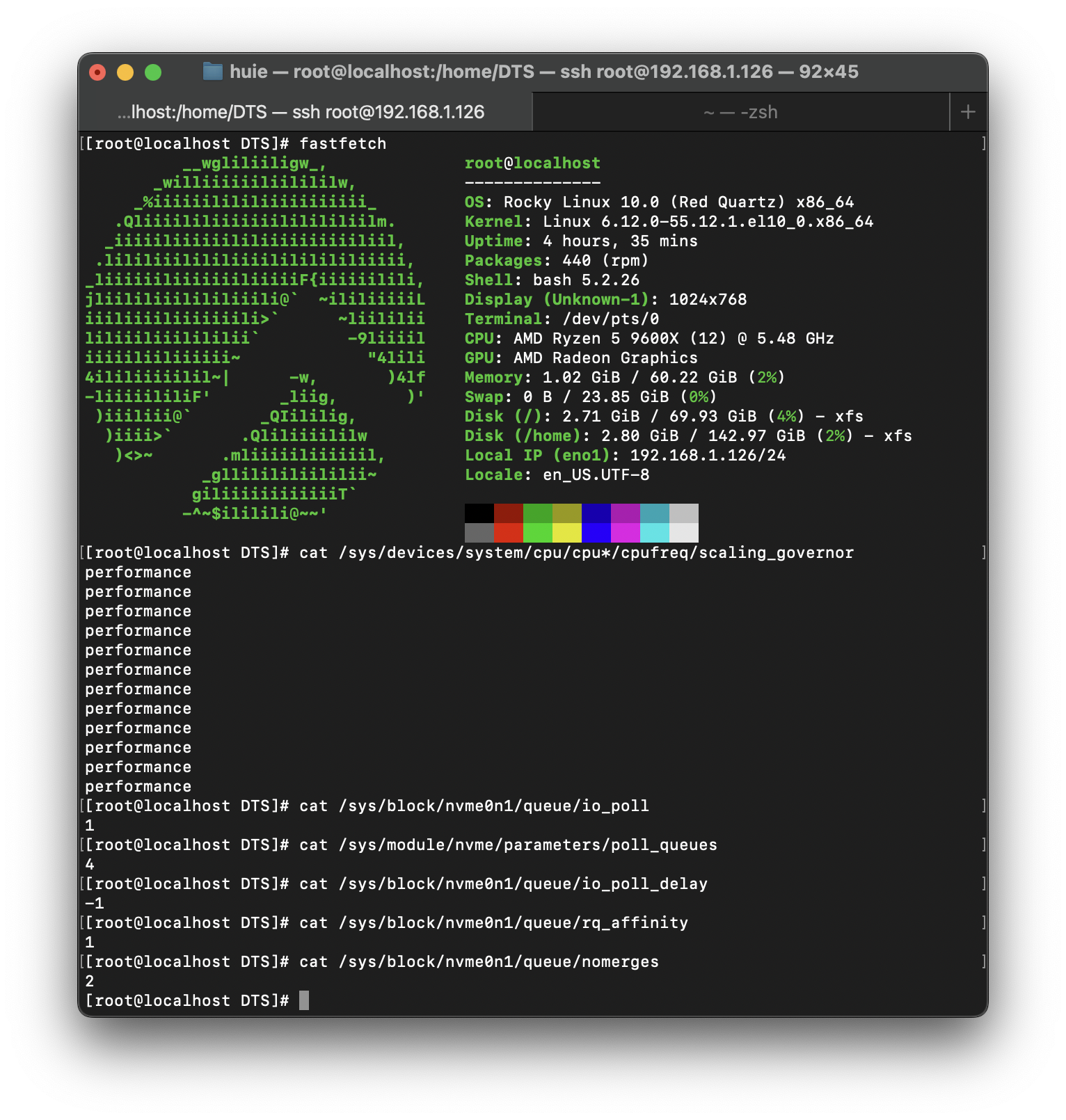
테스트 환경은 위와 같습니다. Windows 25H2(26200.6899)에 종속되는 도구들을 제외하고는 모두 FIO 3.41을 통해 Rocky Linux 10(6.12.0-55.12.1.el10_0)에서 실행되며, io_uring과 Polling을 적극적으로 활용합니다. 또한, 양쪽 다 기본 Inbox Driver를 사용합니다.
HW 사양에 대해서는 상단 우측의 fastfetch를 통해서 확인할 수 있지만, 다시 언급하자면, AMD의 9600X를 사용하고 있습니다. DUT는 5.0 x16 연결이 가능한 PEG 슬롯에 장착됩니다.
자세한 벤치마크 방법론에 대해서는 이전에 작성한 Refresh Benchmark를 참고해 주시길 바랍니다.
cSSD Benchmarking
start /wait Rundll32.exe advapi32.dll/ProcessIdleTasks Windows에서는 위의 명령어를 실행하고 15분 뒤를 IDLE 상태로 정의해 벤치마크를 진행합니다. 각 벤치마크 사이에는 5분의 휴식 시간이 부여되며, Purge는 Linux에서 nvme format 명령어를 통해 수행했습니다.
CrystalDiskMark 9.0.1
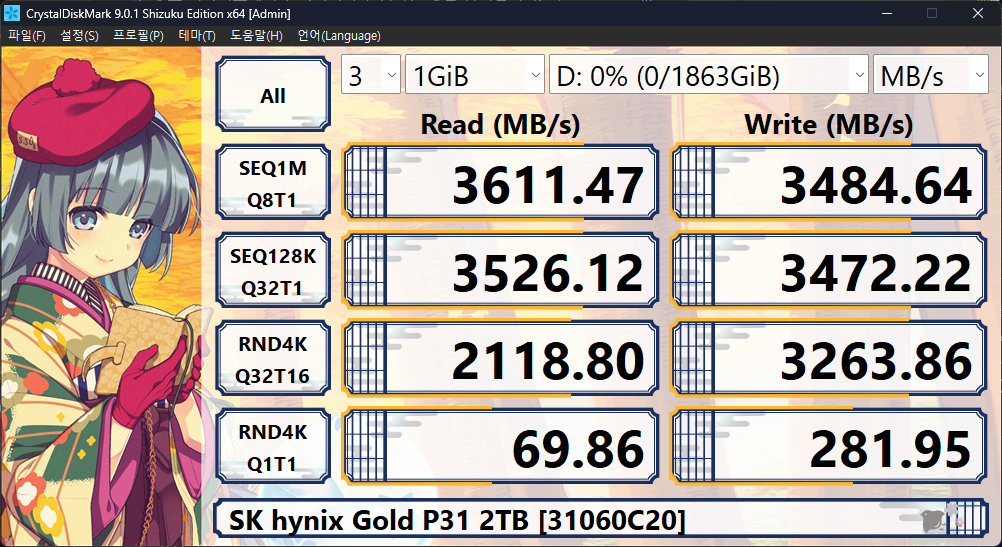
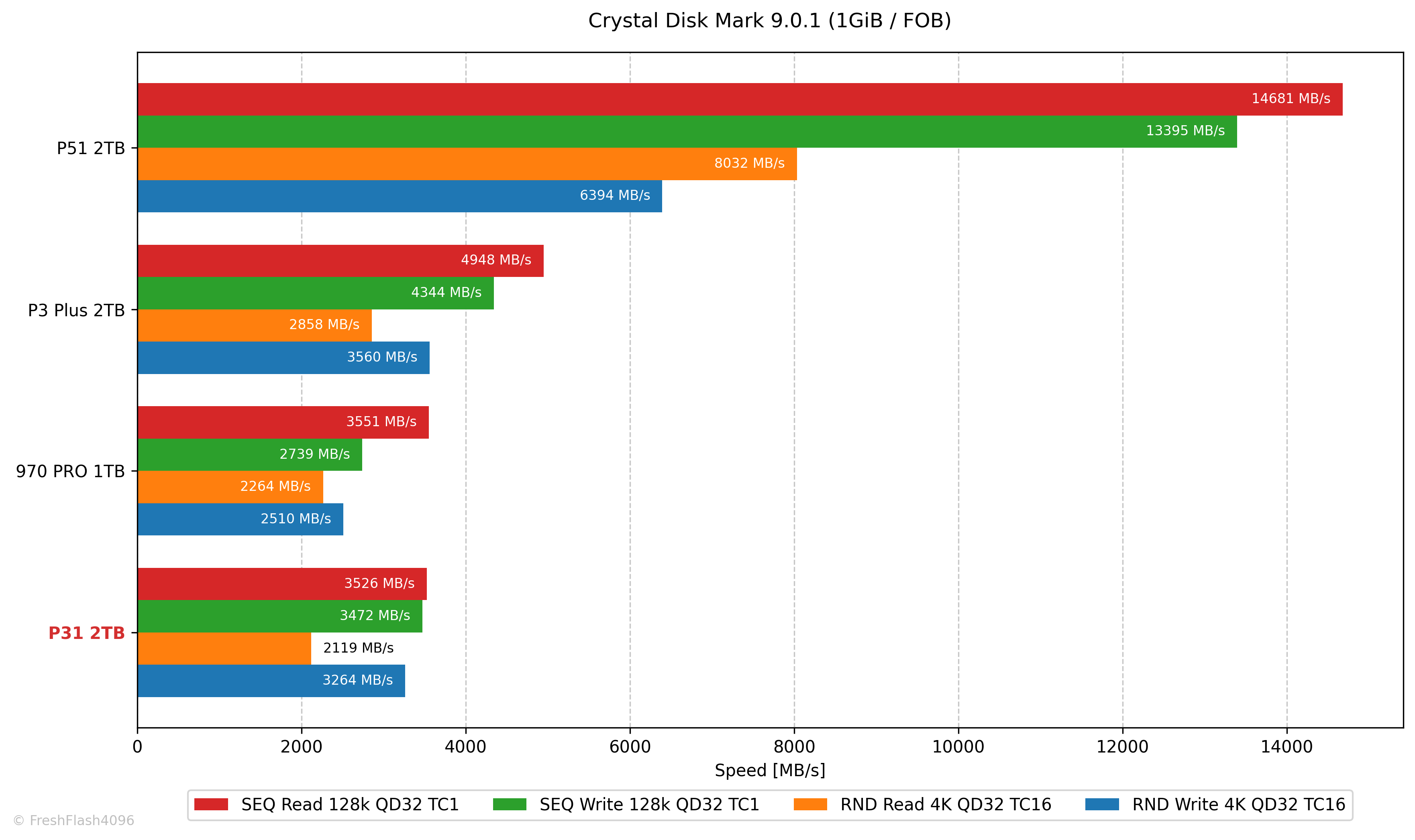
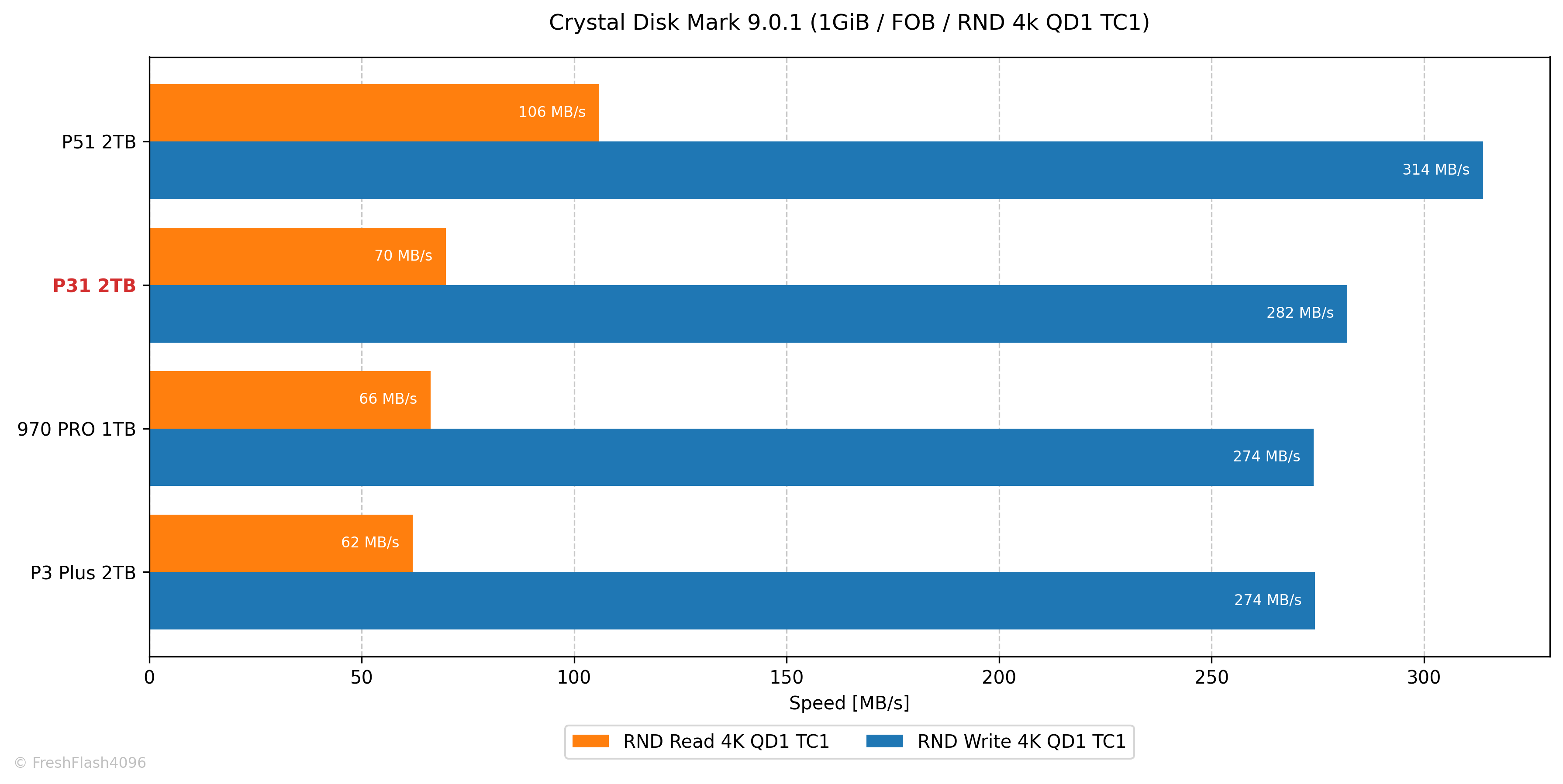
스펙의 SEQ RW는 각각 3500 MB/s와 3200 MB/s로 충분히 상회하는 모습입니다. 다만, RND RW는 570k IOPS와 600k IOPS, 환산하면 2335 MB/s와 2458 MB/s인데, 읽기 쪽이 살짝 부족한 모습입니다.
TLC의 수치라고 명시된 500k IOPS = 2048 MB/s는 만족하는 모습이네요.
3DMark Storage Benchmark
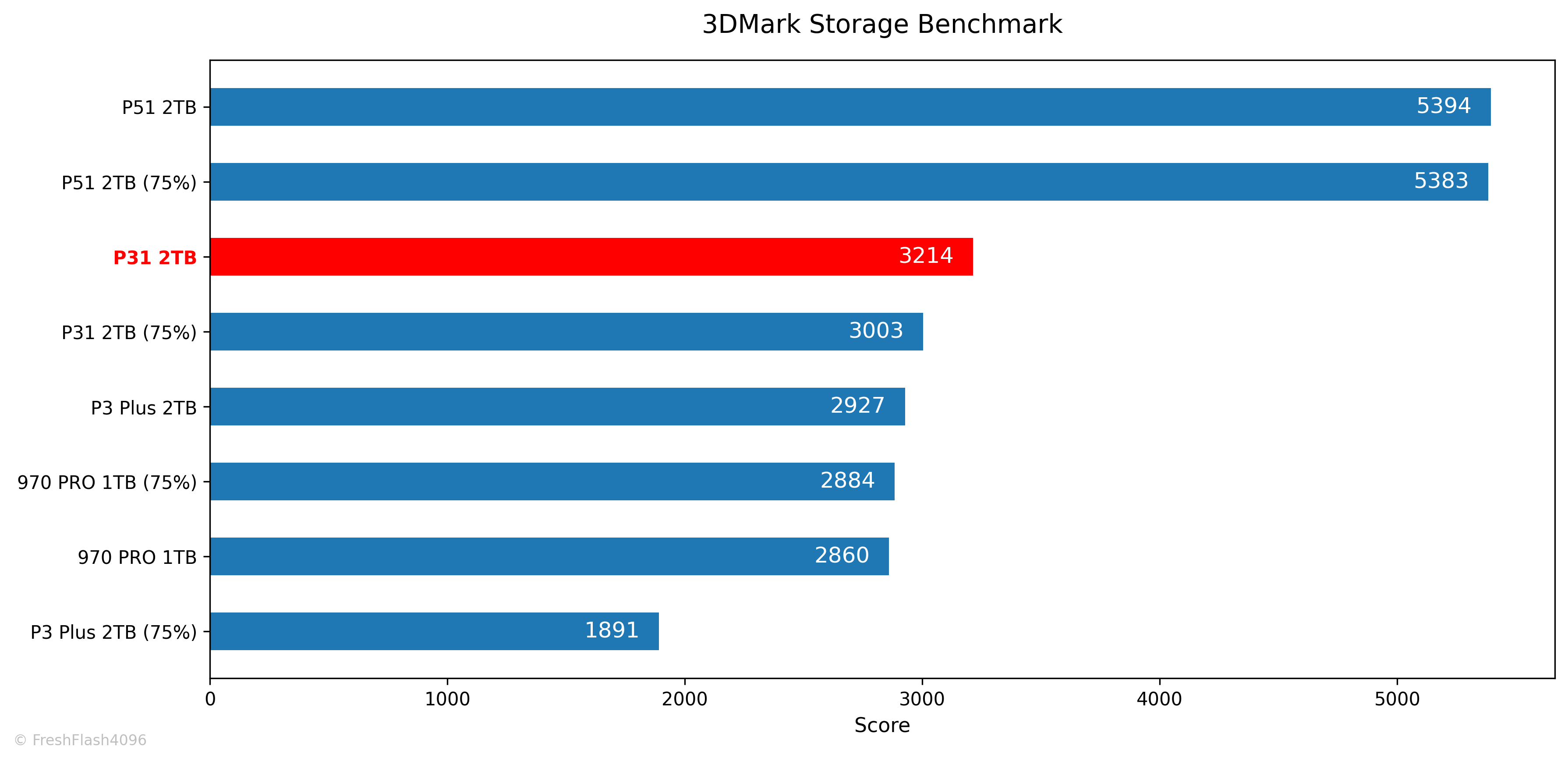
P51과 다르게 75%가 채워진 상태에서는 점수가 6.5% 가량 하락했습니다.
SPECworkstation 4.0
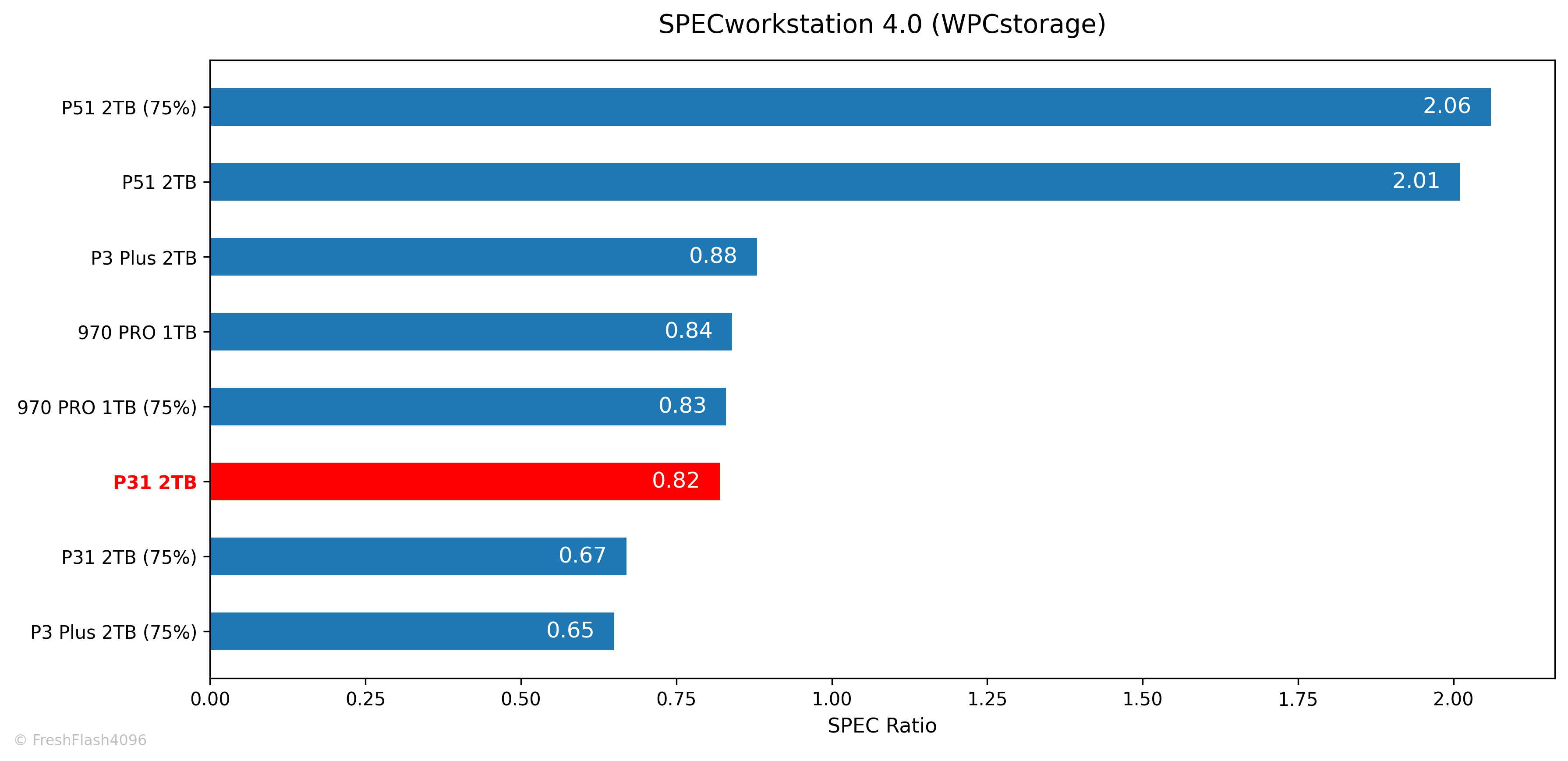
부하가 조금 강해지는 SPECworkstation에서는, 3DMark와 다르게 P3 Plus가 약간 상회하는 모습을 보여주었습니다. 75%가 채워진 후에는 얄짤없지만요.
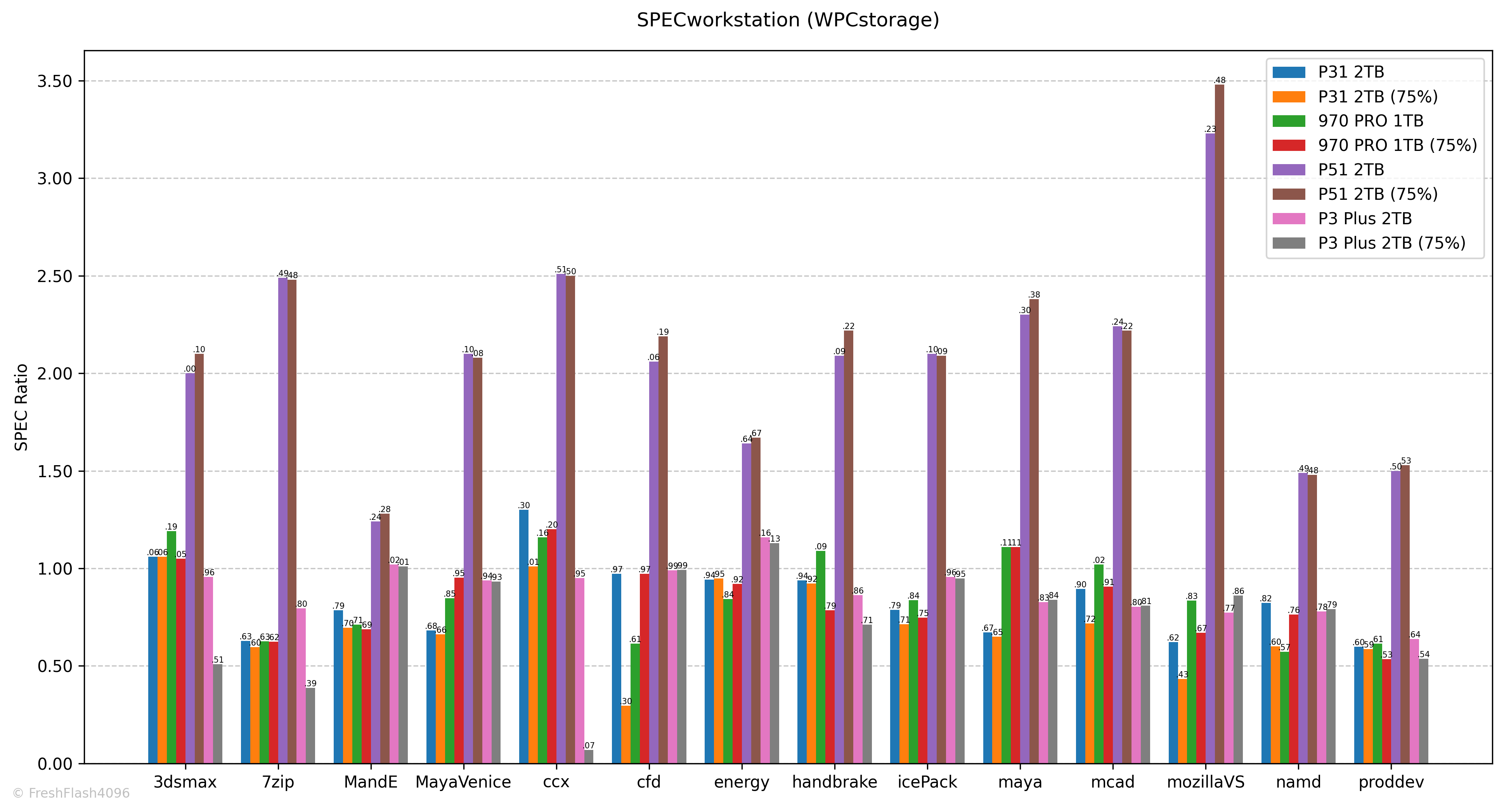
3dsmax나 ccx, energy등과 같은 워크로드에선 SPEC Ratio가 1.00에 가까워, 생각보다 어느정도 괜찮은 모습을 보였습니다. cfd 워크로드는 용량이 채워짐에 따라 수치가 크게 하락하는 것도 눈에 띕니다.
Fill Drive
나래온 더티테스트와 비슷한 벤치마크입니다. FOB상태로 시작하여, SEQ 128k QD256으로 드라이브 전체를 2회 채우며, 0.1s 단위로 값을 측정합니다. 1회차와 2회차 사이의 휴식은 충분히 부여됩니다.
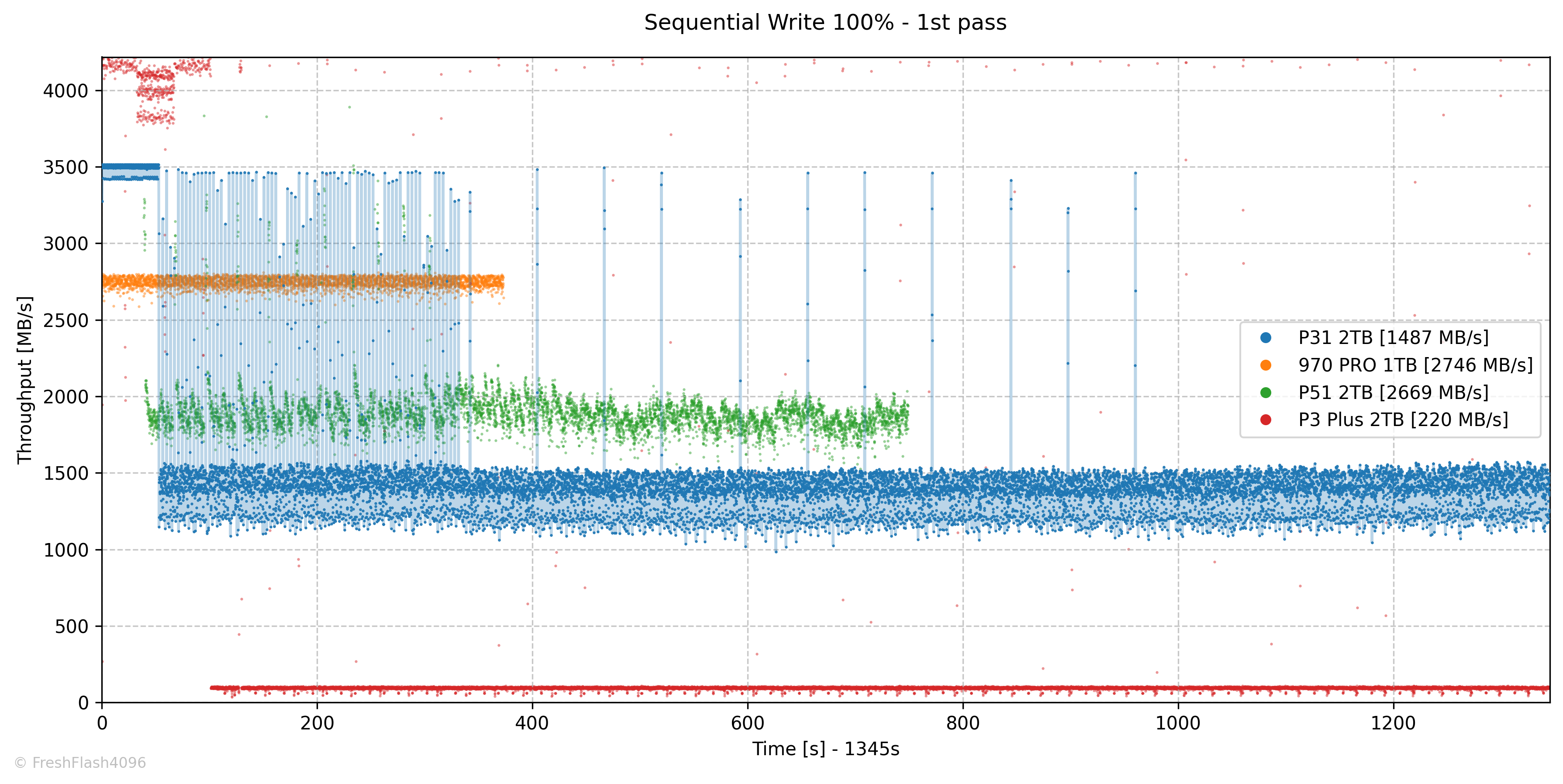
최대 SLC 캐시의 크기는 184GB로 추정되며, 평균적으로 3492 MB/s의 속도를 보여주었습니다. 이후에는 캐시와 Flush의 속도가 혼합된 단계를 거쳐, Flush만 진행되는 구간에 도달하게 됩니다. 이때의 평균 속도는 1384 MB/s입니다.
TLC에 직접 기입되는 속도가 아니라는 것에 유의하시기 바랍니다.
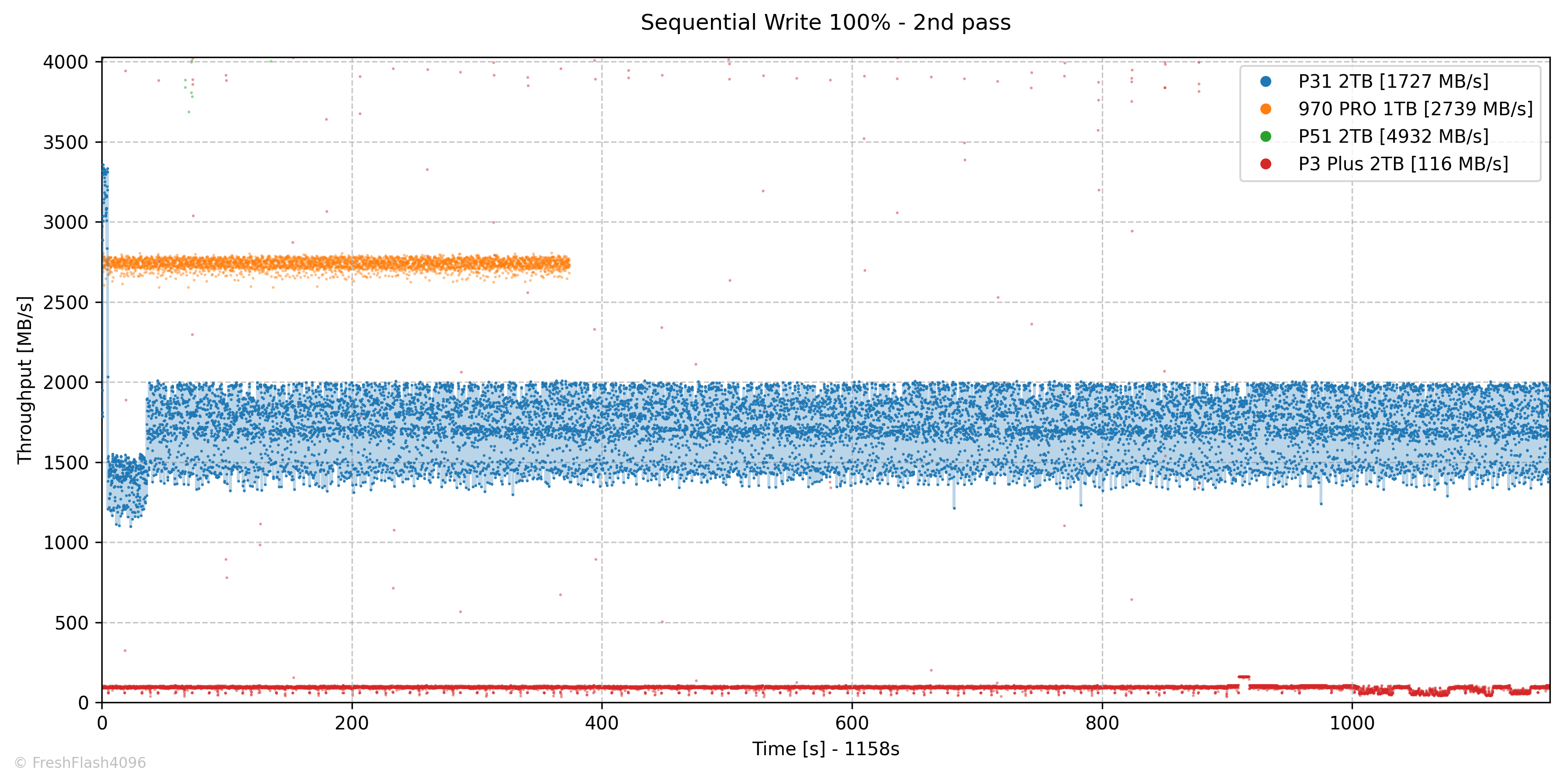
최소 SLC 캐시의 크기는 약 14GB로 추정되며, 평균적으로 3200 MB/s의 속도를 보여주었습니다. 1차 Fill Drive와 다르게 명백하게 속도가 다른 구간들이 보이는데, 첫 번째가 SLC 캐시였다면, 두 번째 단계는 Flush입니다.
SLC 캐시의 내용물을 TLC로 이동하며 동시에 데이터를 받는 단계인데, 이 단계는 1차 Fill Drive에서 SLC 캐시 이후의 속도로 제시된 것과 비슷한 1397 MB/s를 보여주었습니다.
마지막 단계는 TLC NAND에 직접 데이터를 쓰는 단계인데, 평균 1730 MB/s가 측정되었습니다. 스펙시트에서 TLC 속도라고 표기된 1700 MB/s 보다 약간 높은 모습입니다.
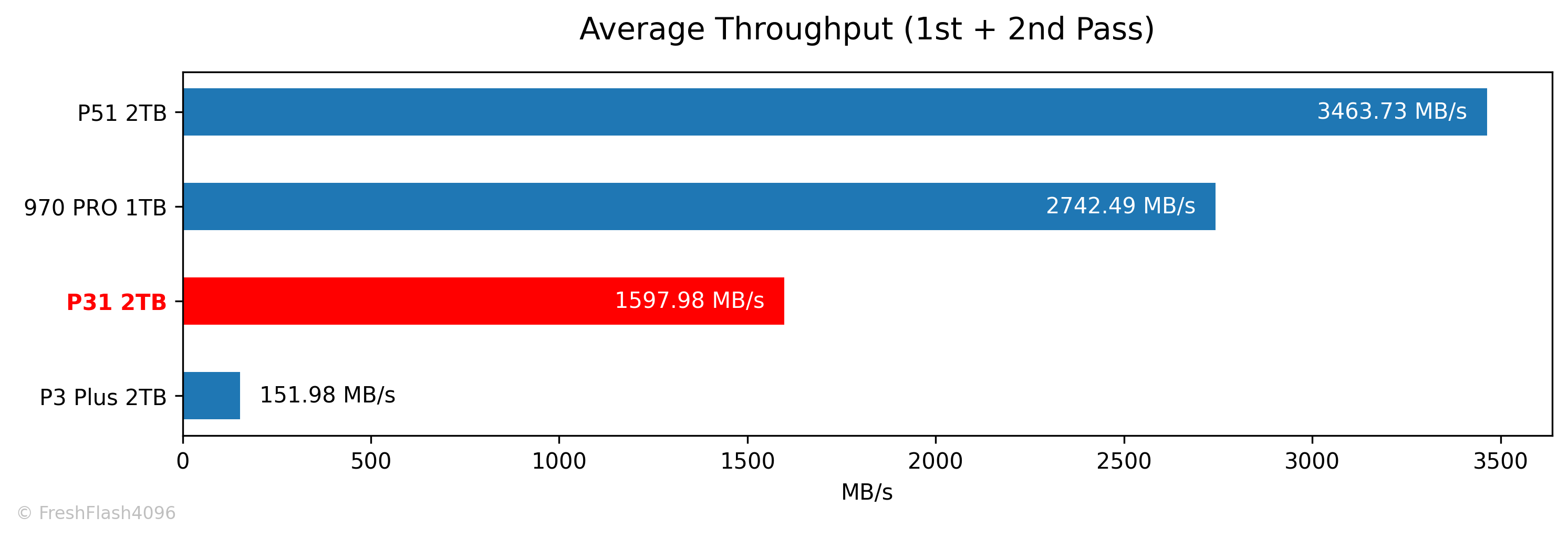
첫 번째와 두 번째의 Fill Drive에 대한 전체 평균값은 약 1600 MB/s 입니다.
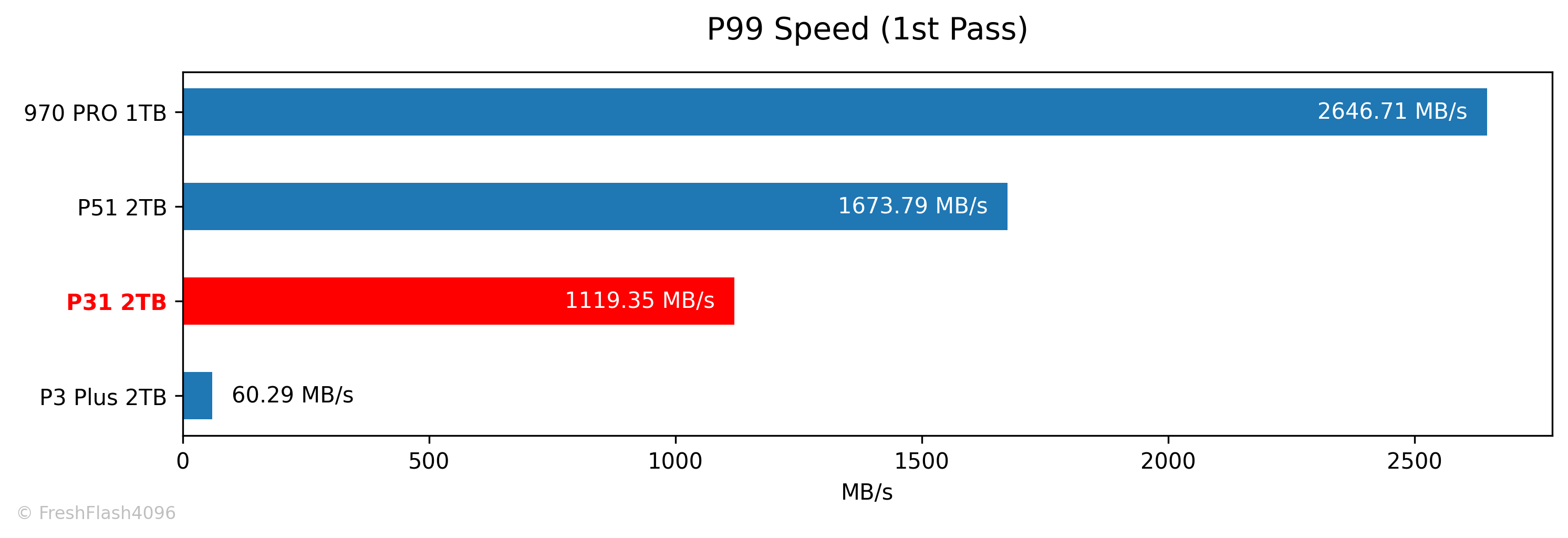
첫 번째 Fill Drive에 대한 하위 1% 속도는 약 1120 MB/s로, 1GB/s를 넘기는 모습입니다.
Sync Performance
자체적인 Pre-Conditioning 이후, 해당 영역에 한해서 측정됩니다. 쓰기량은 총 500MiB이며, 최대 소모 시간은 2분으로 제한합니다. sync=1 옵션을 활용했습니다.
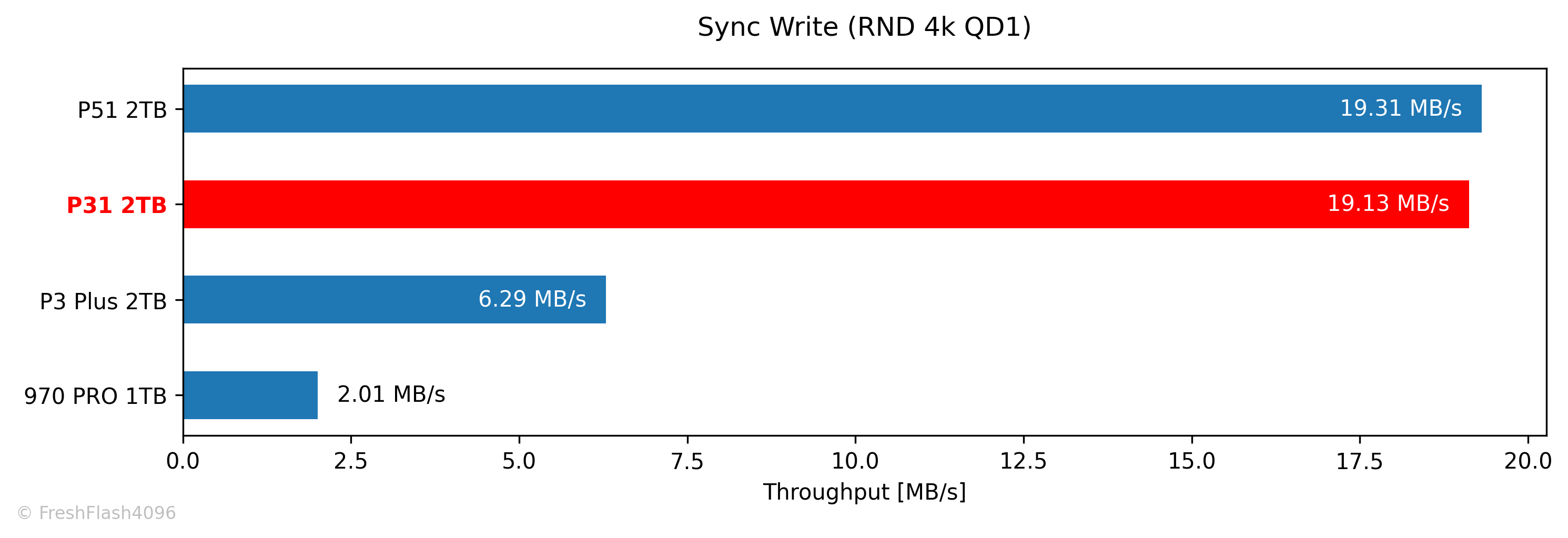
19.13 MB/s라는 속도를 보여주었습니다.
Low QD Performance by RW Ratio
이전과 마찬가지로 Pre-Conditioning 이후에 측정하며, Burst 성능을 측정하기 위해서 각 단계에서 가해지는 I/O의 양은 GB 단위가 되지 않습니다. 다시 말해, 매우 가벼운 부하입니다. 전체 용량의 75%는 이미 채워져 있지만요.
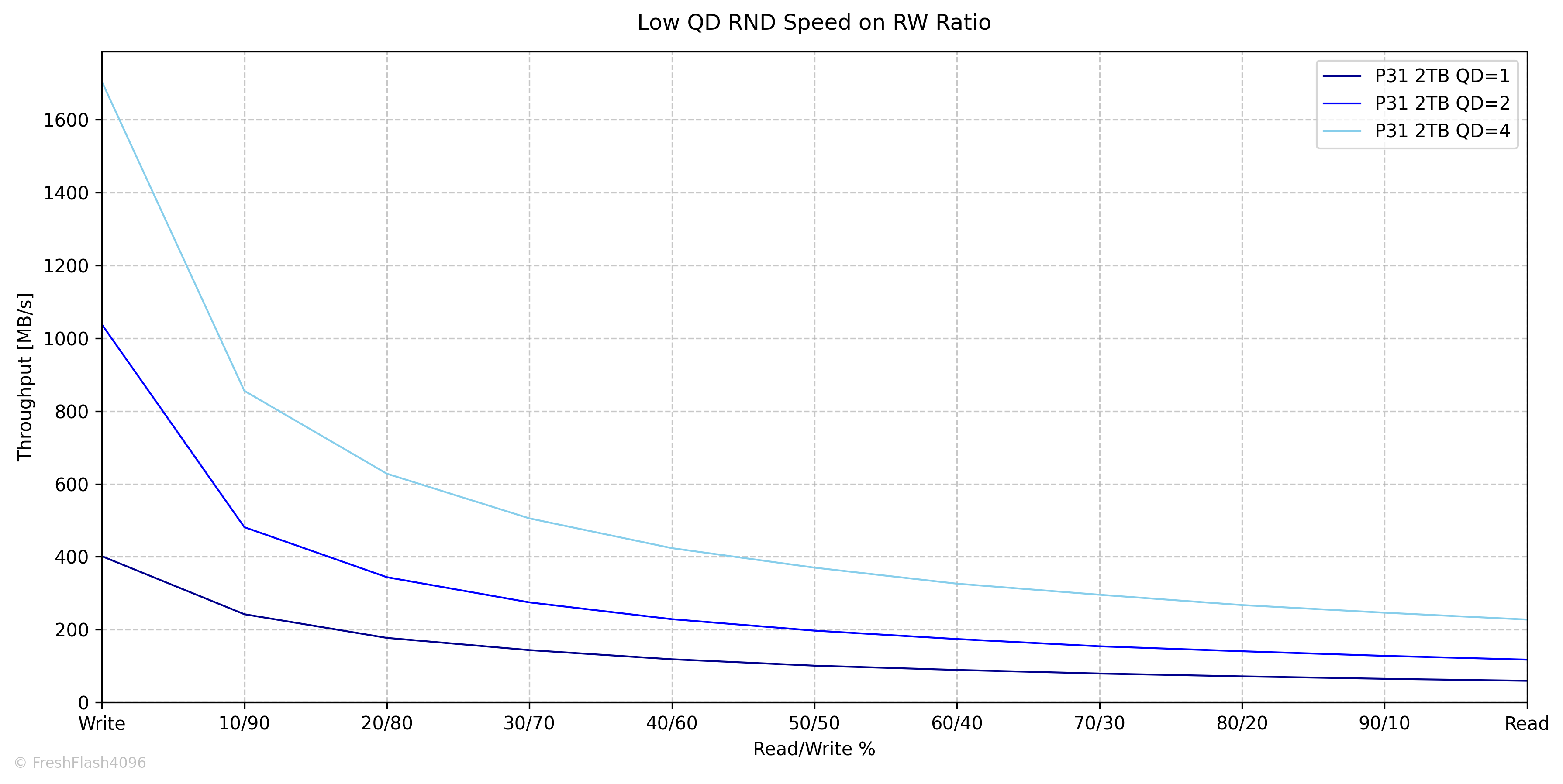
Weighted Graph
QD1 80%, QD2 15%, QD4 5%로 가중치를 부여해 보기 쉽게 나타냅니다.
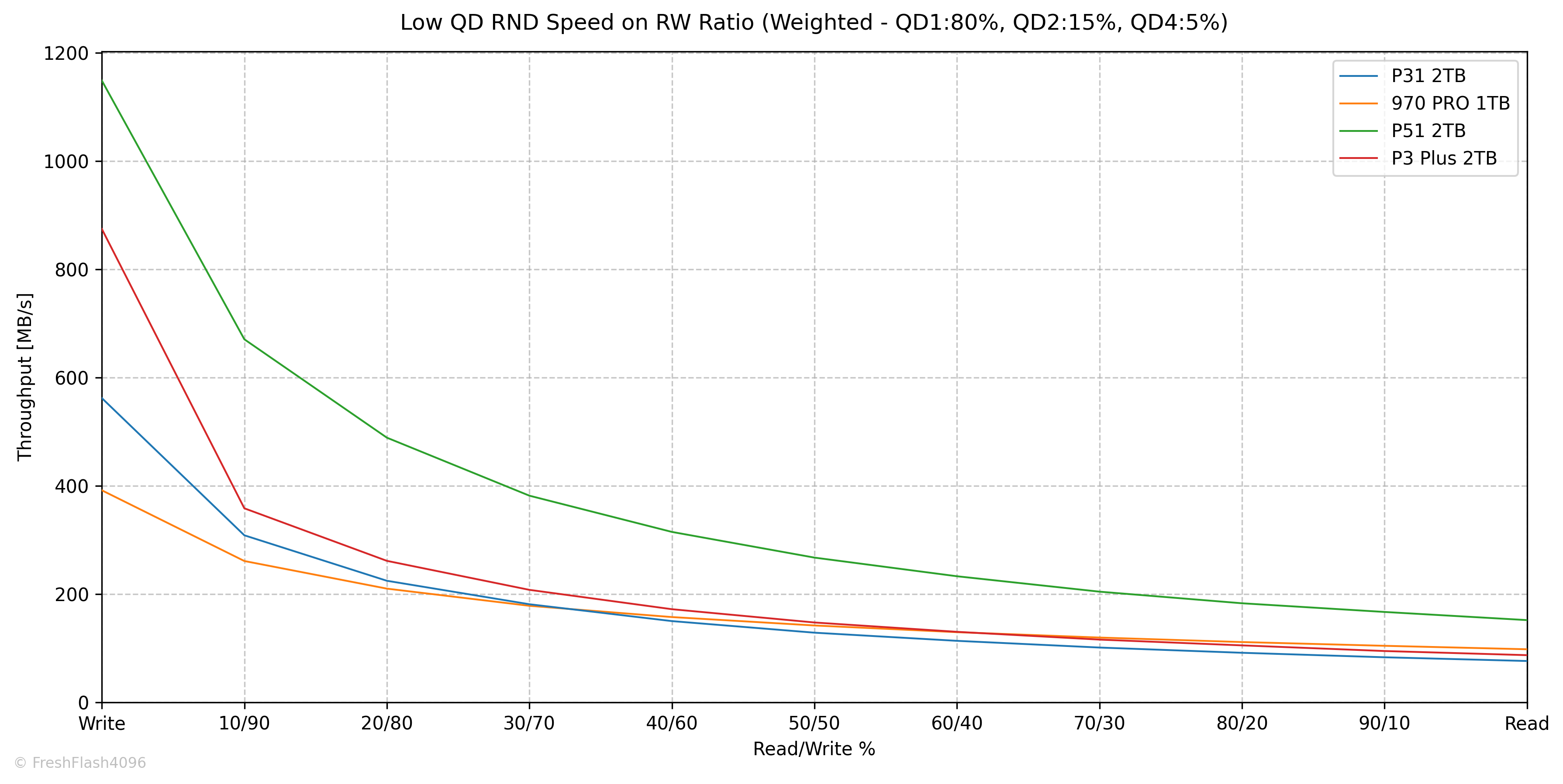
생각보다 우수한 모습은 아닙니다. 특히, 40% 이상의 읽기에서는 가장 뒤쳐지는 모습이었고요.
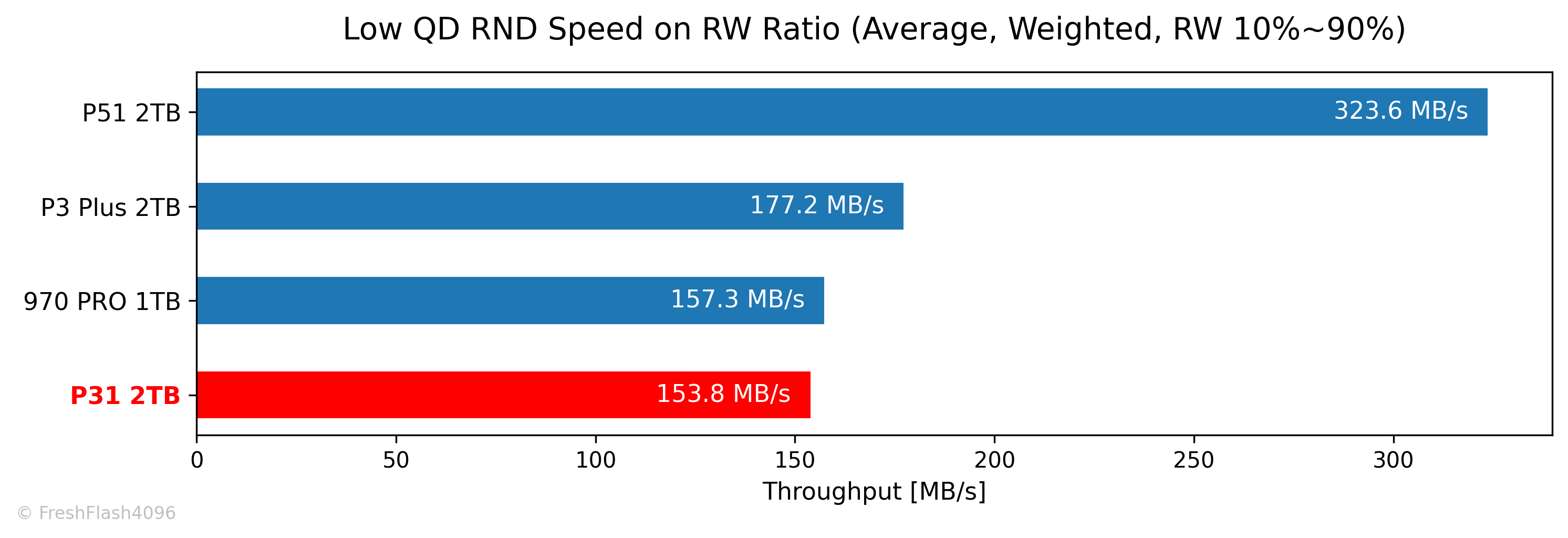
완전한 읽쓰기를 제외하고 산출한 평균값은 비교군 중 가장 낮았습니다.
SLC Cache Reclaim
SLC 캐시의 회복에 대해서 알아보기 위해 설계되었습니다. Purge를 수행하고, User Capacity의 50%를 SEQ 128k QD256로 채운 뒤, 잠깐의 휴식을 취합니다. 이후, SEQ 128k QD256 쓰기를 1분간 진행합니다.
이 휴식 시간을 늘리며 테스트를 7회 진행합니다. 그래프들은 휴식 이후 1분간의 I/O에 대한 결과입니다.
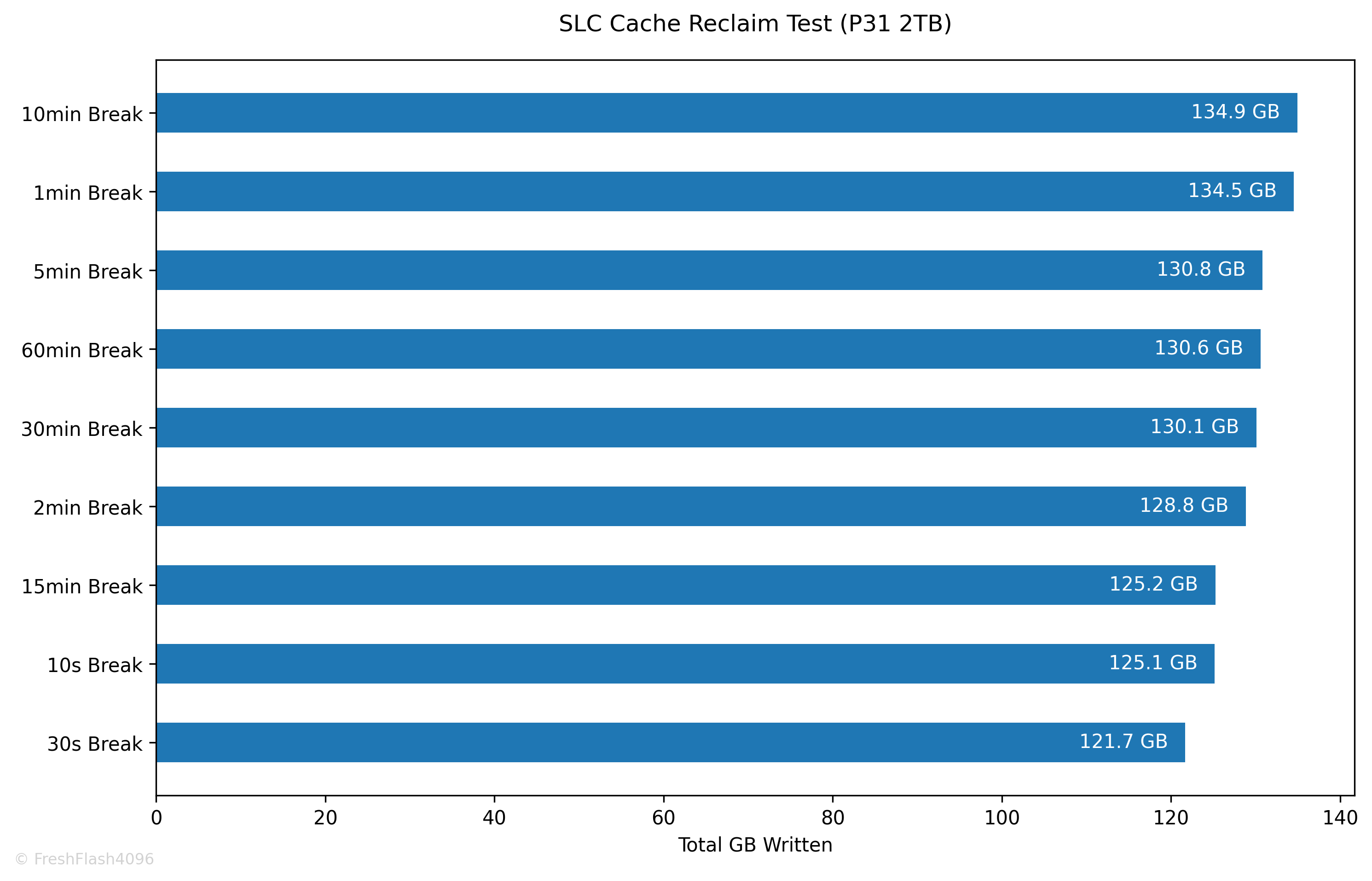
극적인 회복량을 보여주진 않았으며, 비교적 빠르게 SLC 캐시를 복구하는 모습입니다.
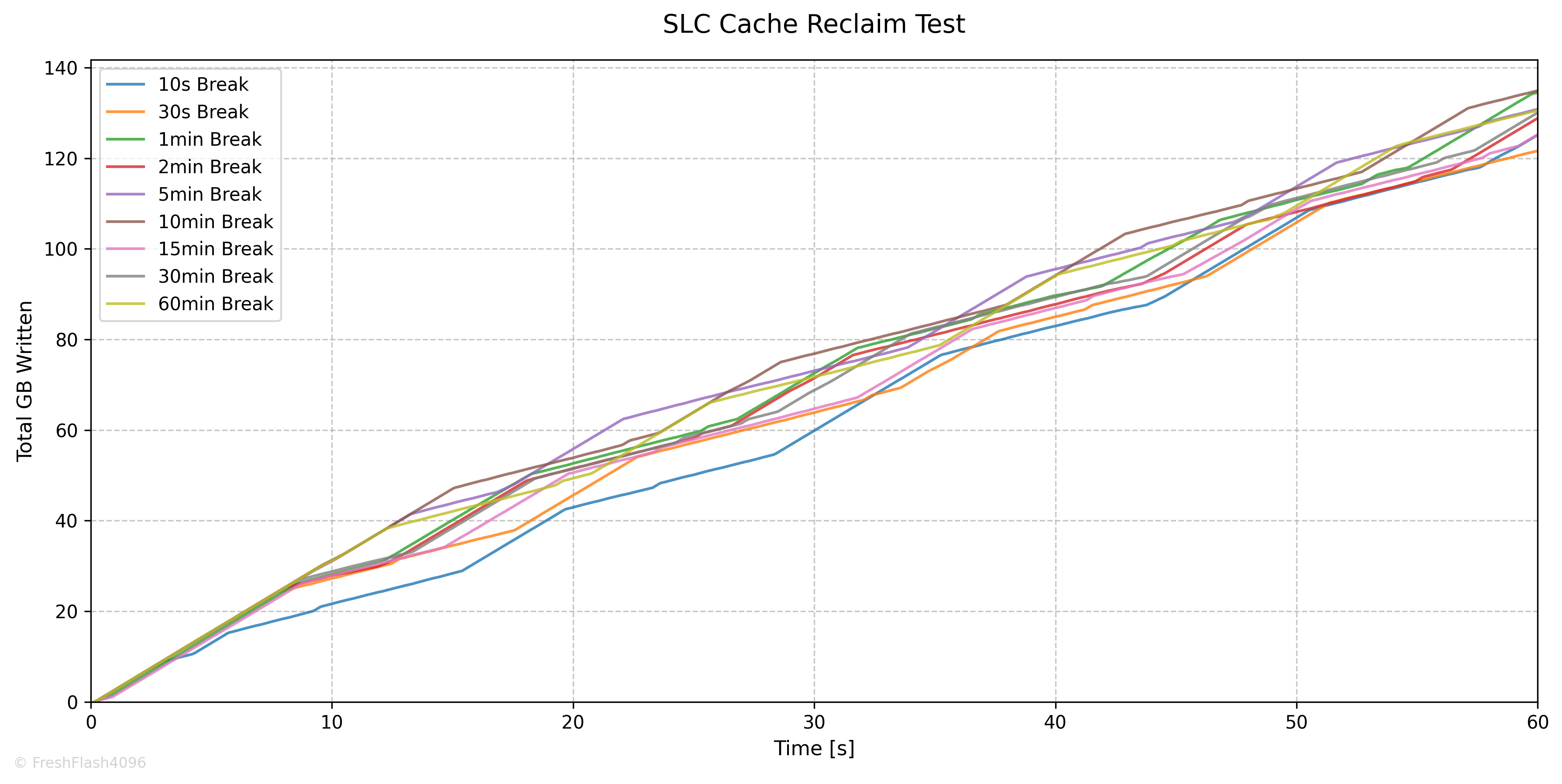
이 그래프가 더 직관적으로 보일 수도 있겠네요.
10초의 휴식시간에서는 초기 SLC 캐시 크기가 작은 모습이지만, 실시간으로 복구되는 캐시를 적극적으로 활용하는 모습입니다.
eSSD Benchmarking
Purge 직후를 제외한 모든 단계 사이에는 휴식 시간이 부여되지 않습니다. Pre-Conditioning은 User Capacity의 2배를 쓰고나서도 Steady State에 진입할 때까지 이를 계속 진행합니다.
Steady State는 SEQ의 경우엔 대역폭의 기울기가 ±10%인 상태를 30초간 유지하는 것을 기준으로 하며, RND의 경우에는 IOPS의 기울기가 ±10%인 상태를 30초간 유지하는 것을 기준으로 합니다. 이를 달성할 수 없을 땐 User Capacity의 23배까지 쓰기를 진행합니다.
모든 워크로드는 User Capacity의 전체 영역에 대해서 진행하며, 각각 30초의 적응 시간을 가진 후에 5분 동안 성능측정을 진행합니다. 다시 말해, 128k Read 성능을 측정한다면 QD1 ~ QD256까지 총 9개의 작업이 있으며, 모든 작업이 30초의 적응 시간과 5분의 측정시간이 부여됩니다.
역시 자세한 벤치마크 방법론에 대해서는 이전에 작성한 Refresh Benchmark를 참고해주시길 바랍니다.
4-Corners Performance
SEQ Pre-Conditioning
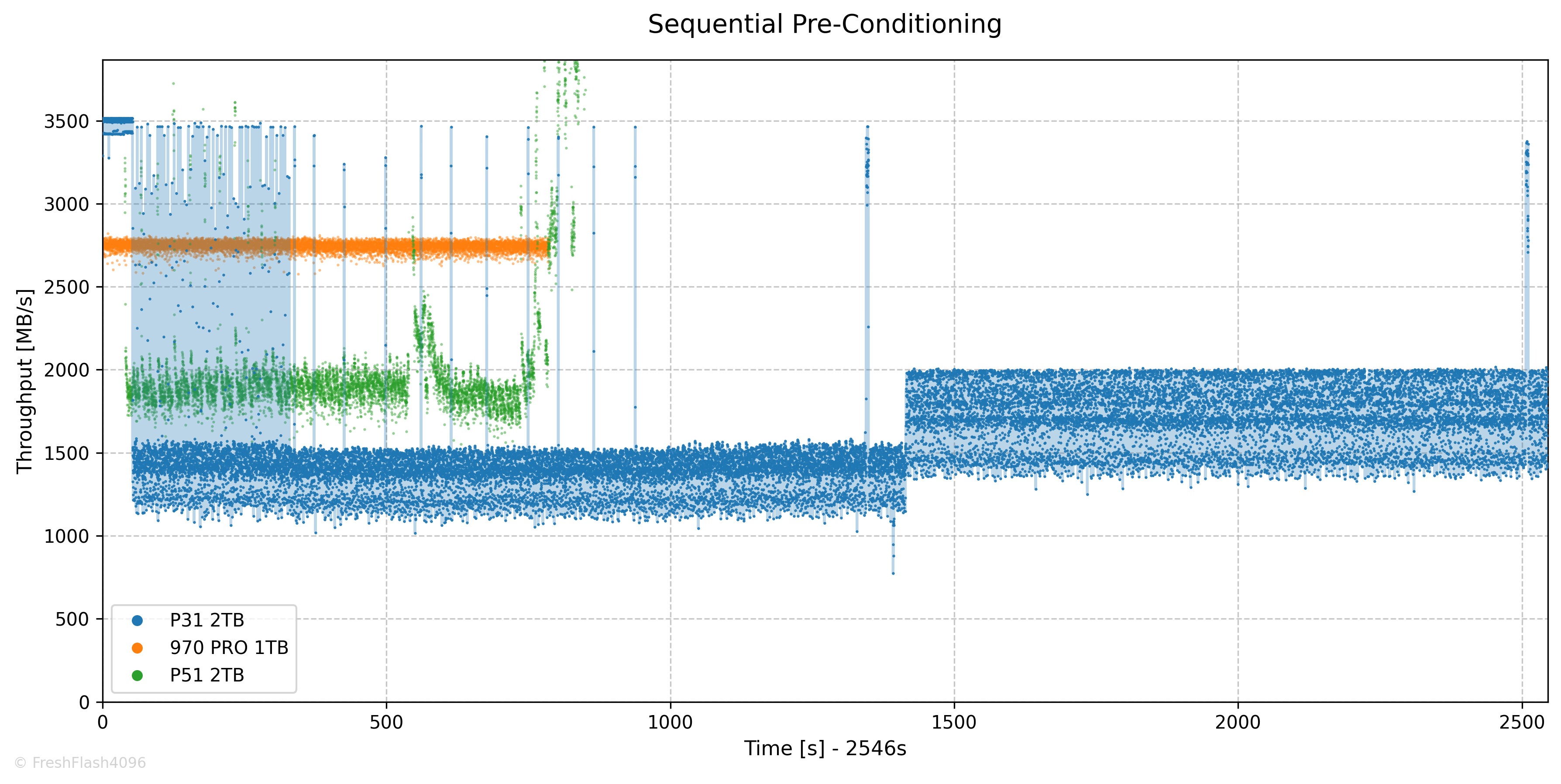
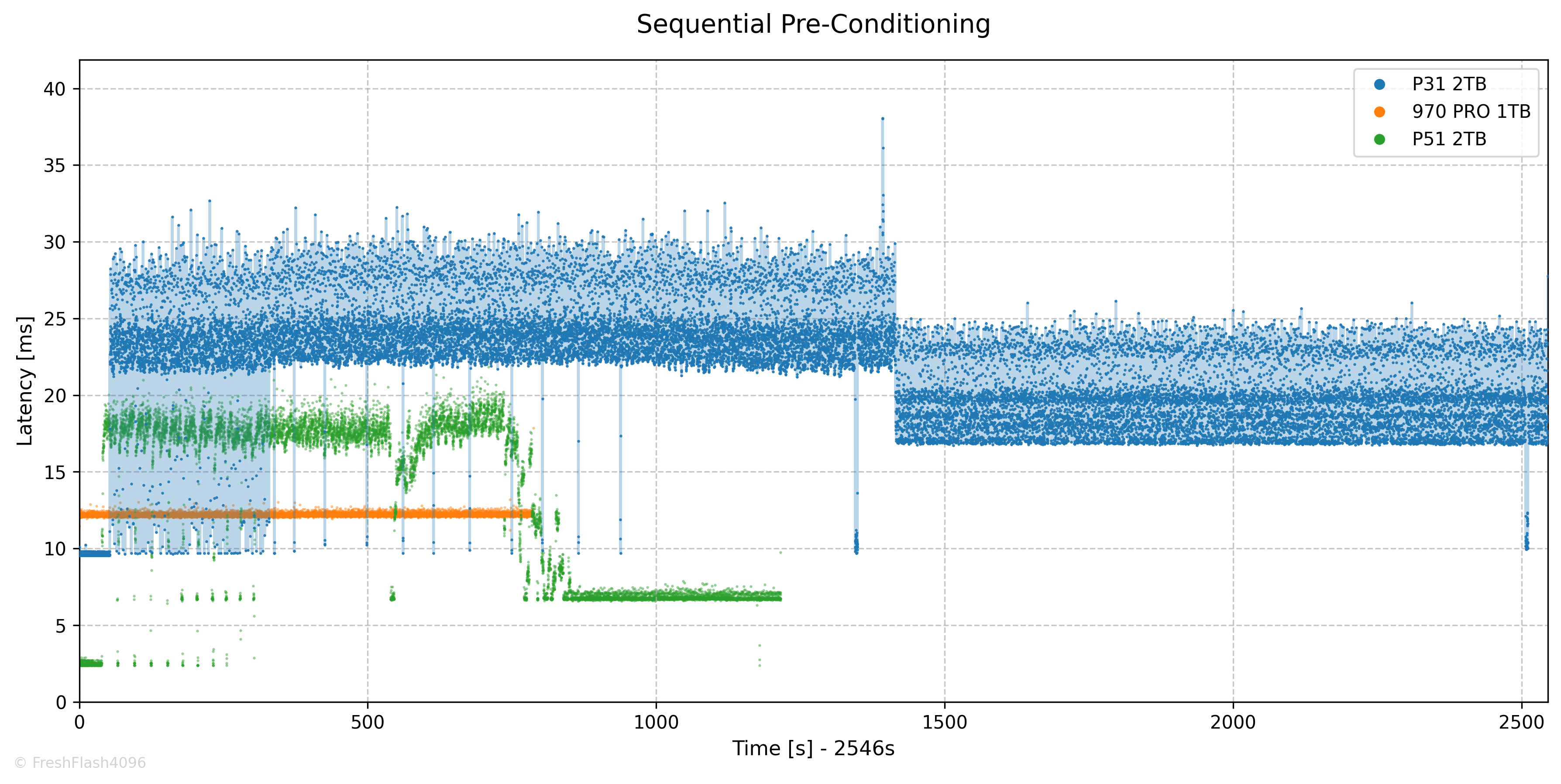
SEQ Pre-Conditioning에는 약 42분의 시간이 소모되었으며, 1703 MB/s의 속도로 Steady State에 진입했습니다. 이는 P31의 TLC 속도라고 명시된 1700 MB/s와 일치하는 값입니다.
SEQ 128k Performance
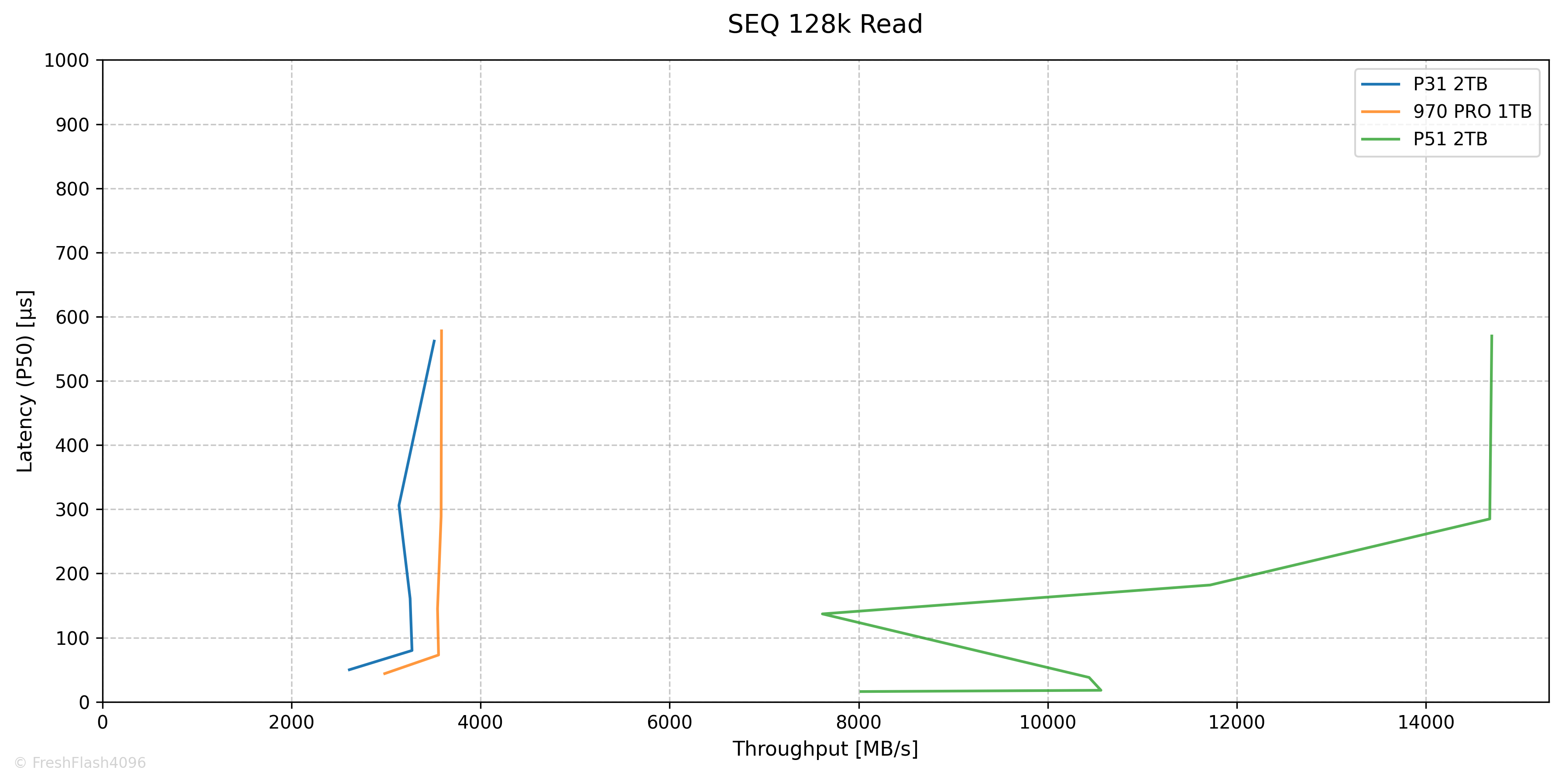
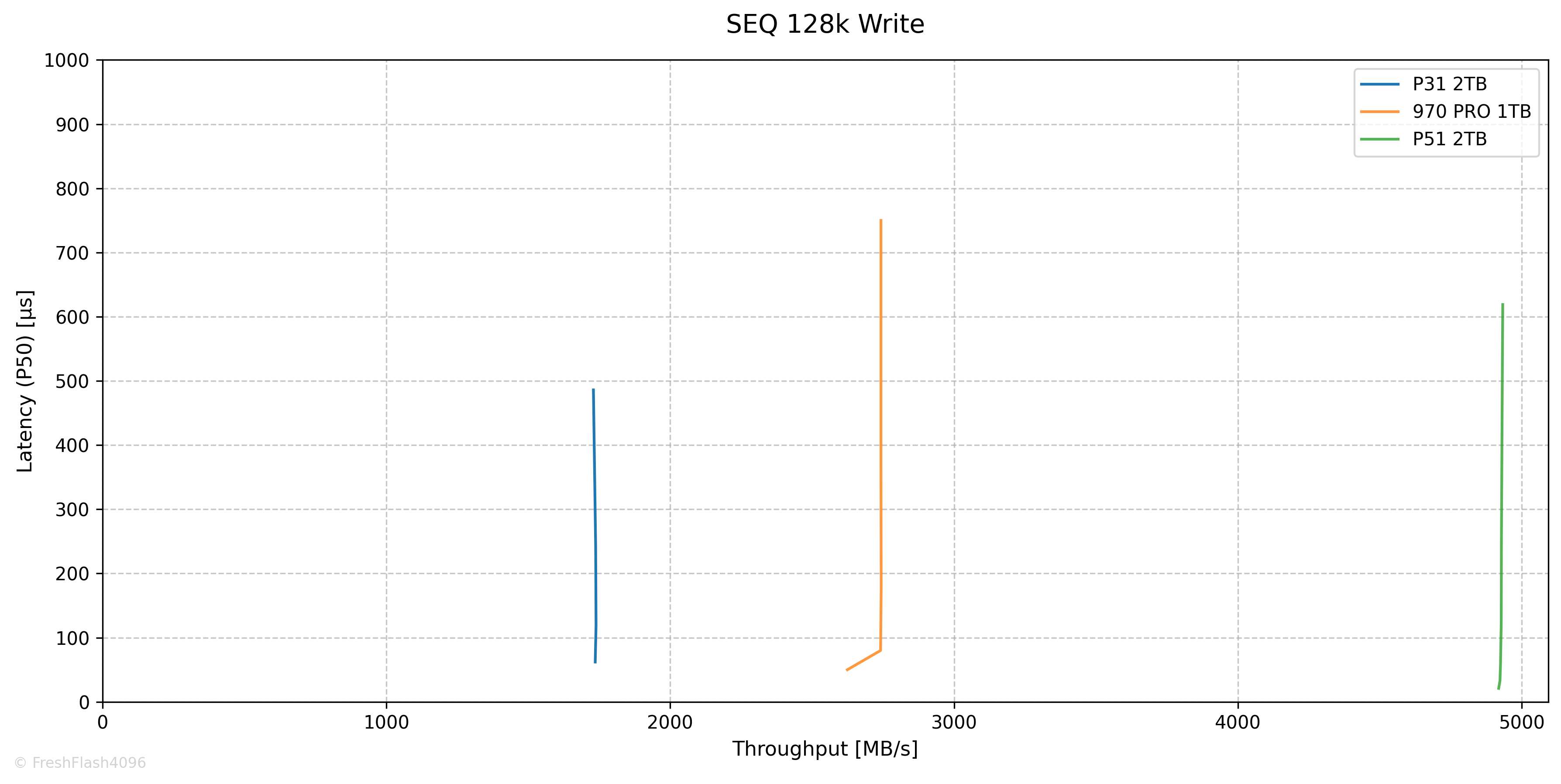
SEQ Read는 QD32에서 3618MB/s@1139µs로 최대 값을 보였습니다. 다만, QD2에서 이미 3275MB/s@80µs의 값을 보였는데, QD가 깊어짐에 따라 극적인 성능 향상은 보이지 않았습니다.
참고로, QD1에선 2612MB/s@50µs 였습니다.
SEQ Write는 QD1에서 1736MB/s@62µs가 측정되었으며, Throughput은 QD256까지 변함없었습니다.
RND Pre-Conditioning
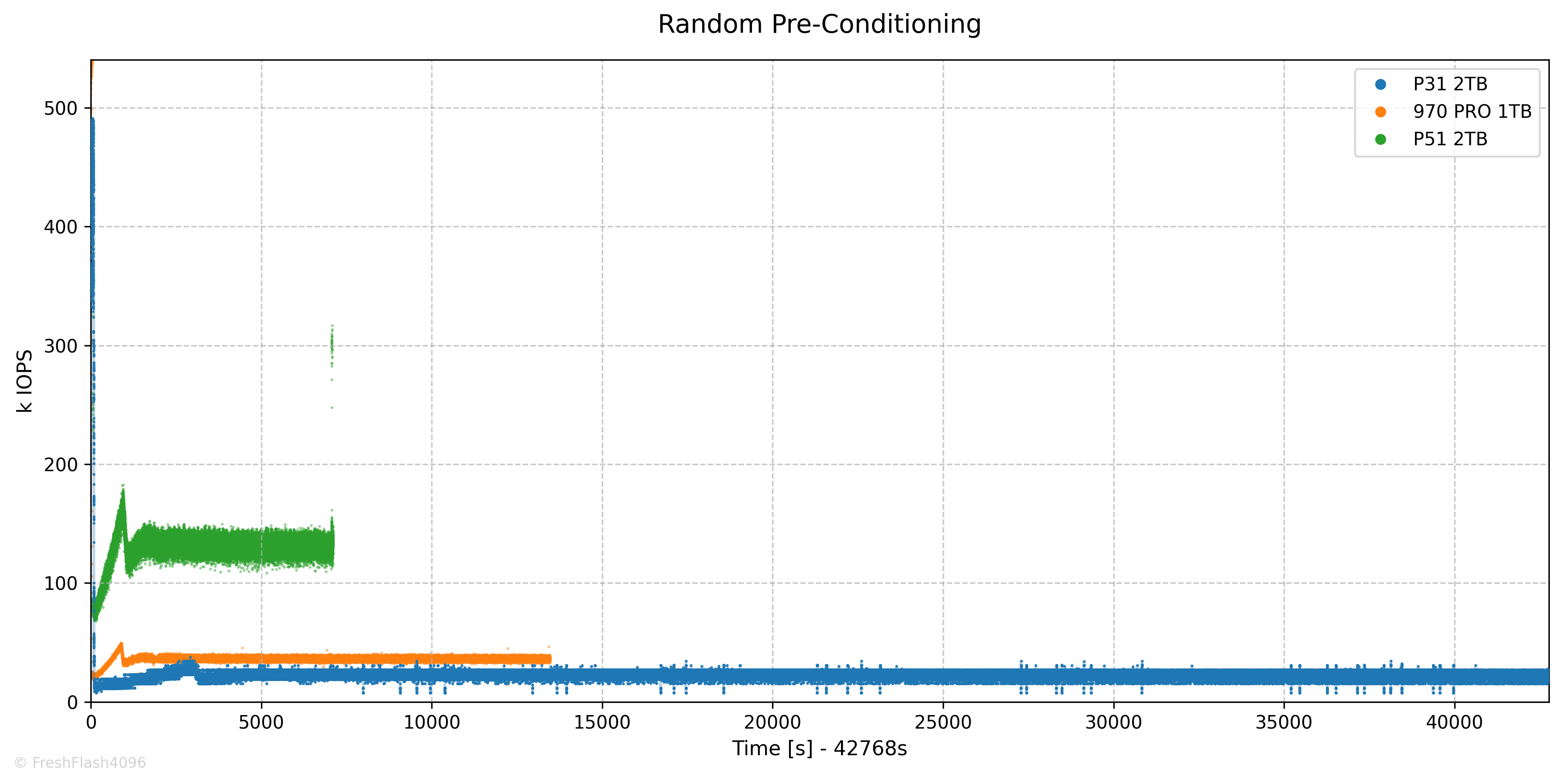
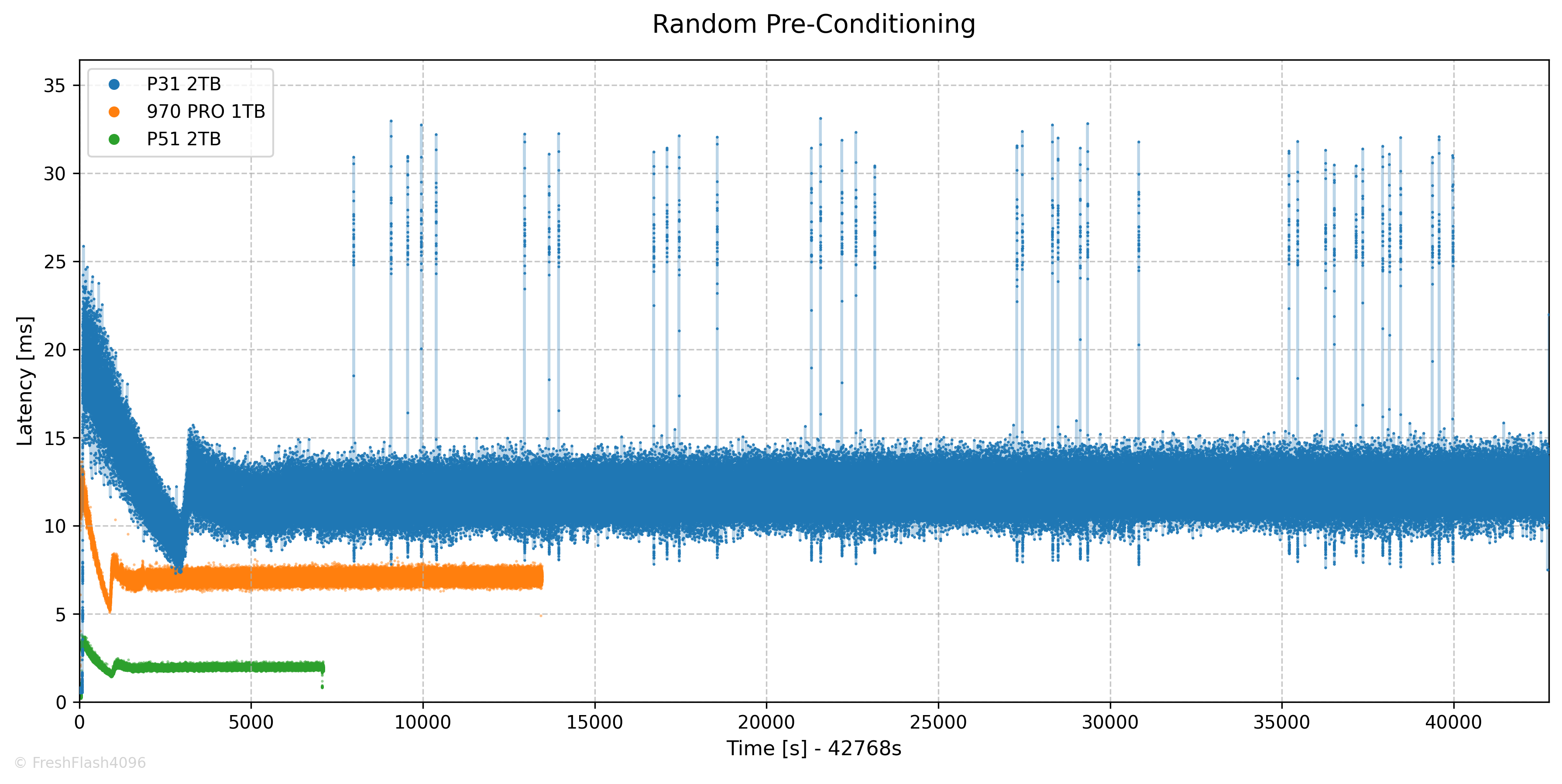
RND Pre-Conditioning은 약 12시간이 걸렸으며, 21.8k IOPS로 Steady State에 진입했습니다. 중간중간 지연시간이 튀는 모습이 눈에 띄네요.
RND 4k Performance
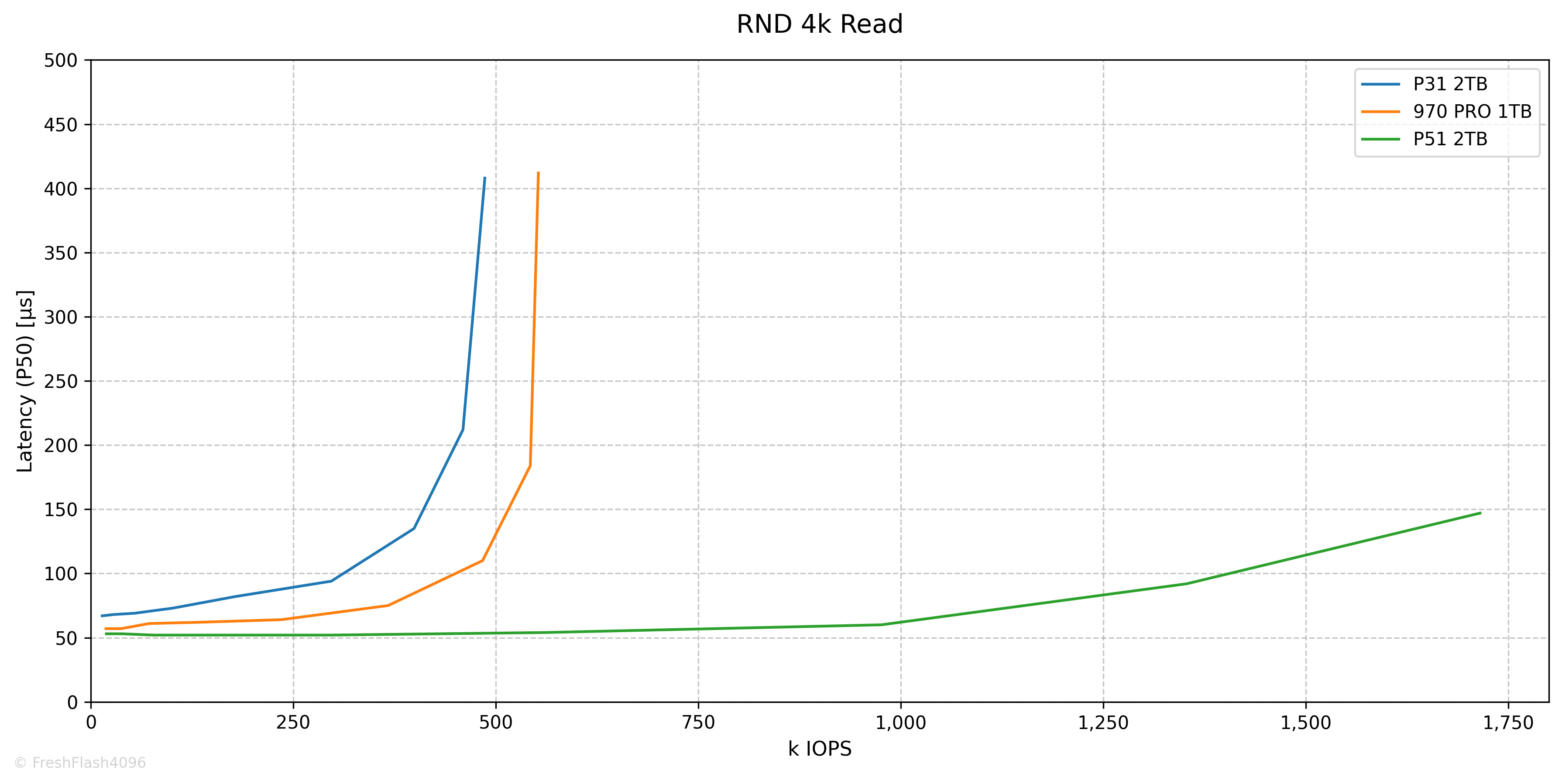
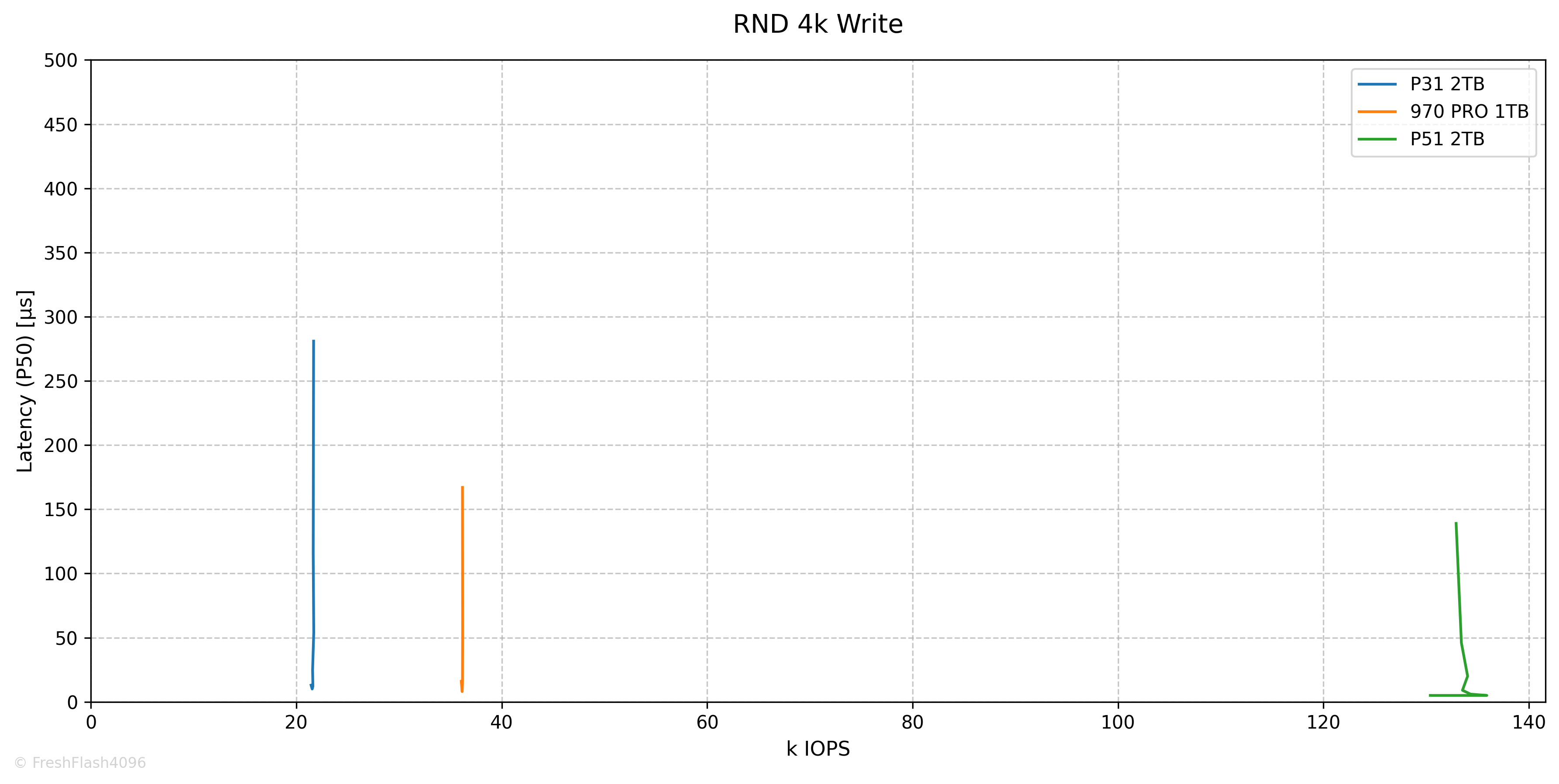
RND Read는 QD256에서 487k IOPS@408µs로 최대값을 보였습니다.
RND Write는 QD1에서 21.4k IOPS@13µs 였으며, SEQ Write처럼 변하지 않는 모습입니다. 약간의 갈고리와 같은 그래프의 모습은 QD2에서 21.5k IOPS@10µs의 수치에 의해 그려졌습니다.
4-Corners Consistency
QD에 따른 4-Corners Performance의 안정적인 정도를 제시합니다. 상위 99.9%값과 평균을 이용하는데, SEQ 128k에서는 Bandwidth를 기준으로, RND 4k에서는 IOPS를 기준으로 계산합니다. 참고로, RND 4k에서 QD1에 대한 값은 이후 Tail Latency에서 자세히 살펴보기에 제외됩니다.
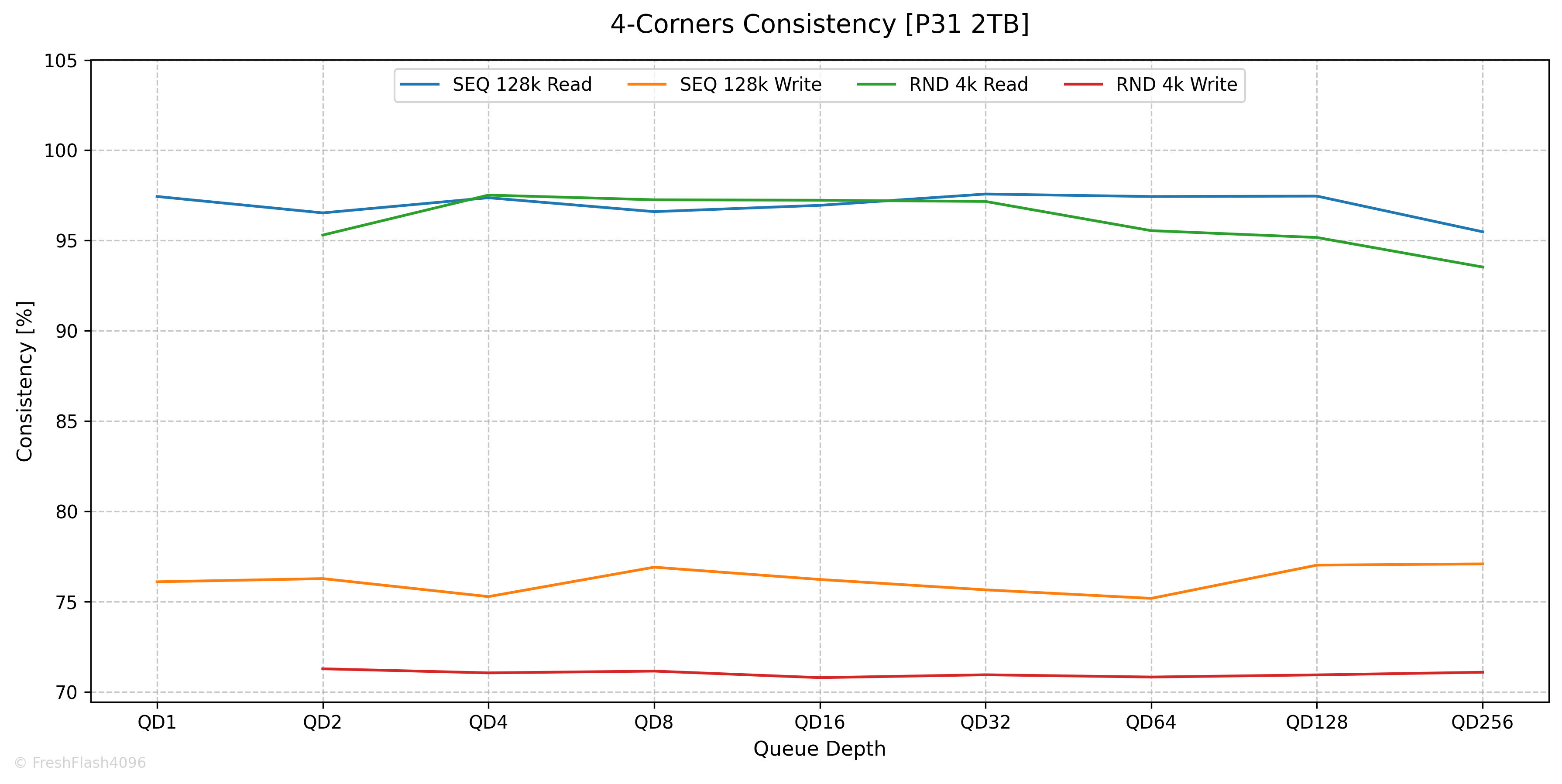
읽기는 대체로 95% 이상의 일관성을 보여주지만, 쓰기는 80%를 넘지 못하는 모습입니다.
Specific Workload Performance
4-Corners Performance가 아닌 워크로드를 분리했습니다. 단, 워크로드 이름은 편의상 붙인 것뿐이며, 실제 환경에서는 다양한 Block Size와 RW 비율이 나타난다는 것을 명심해야 합니다. Block Size들의 정확한 비율과 RW 비율을 결정하기 힘들어 대략 분류한, 가상의 워크로드입니다.
Boot Workload (OCP BootBench)
Hyperscale에서의 Boot Drive로 사용될 때의 성능을 측정하는 벤치마크입니다. SEQ Write로 User Capacity가 2번 채워지면, 동기 쓰기, TRIM, 읽기가 동시에 가해지며, 결과의 지표는 읽기 IOPS입니다. 60k IOPS를 통과하면 합격입니다.
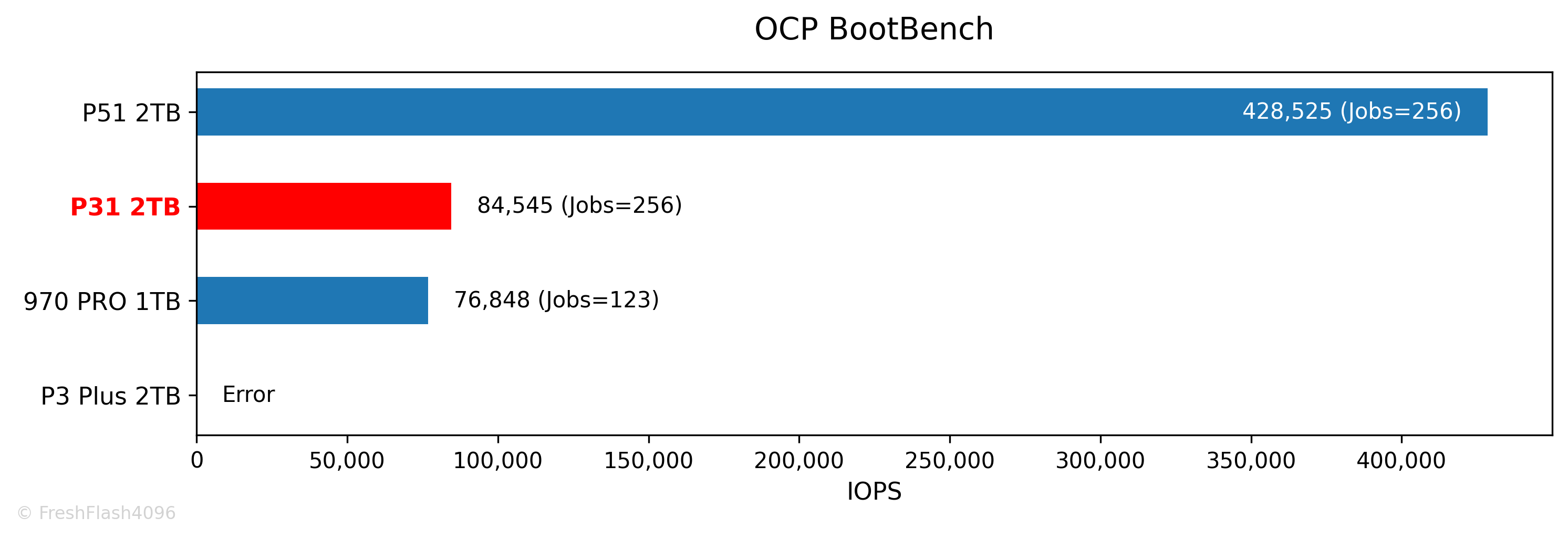
970 PRO보다 근소하게 더 우수한 모습을 보였습니다.
Read Intensive Workload (SEQ 128k R95:W05)
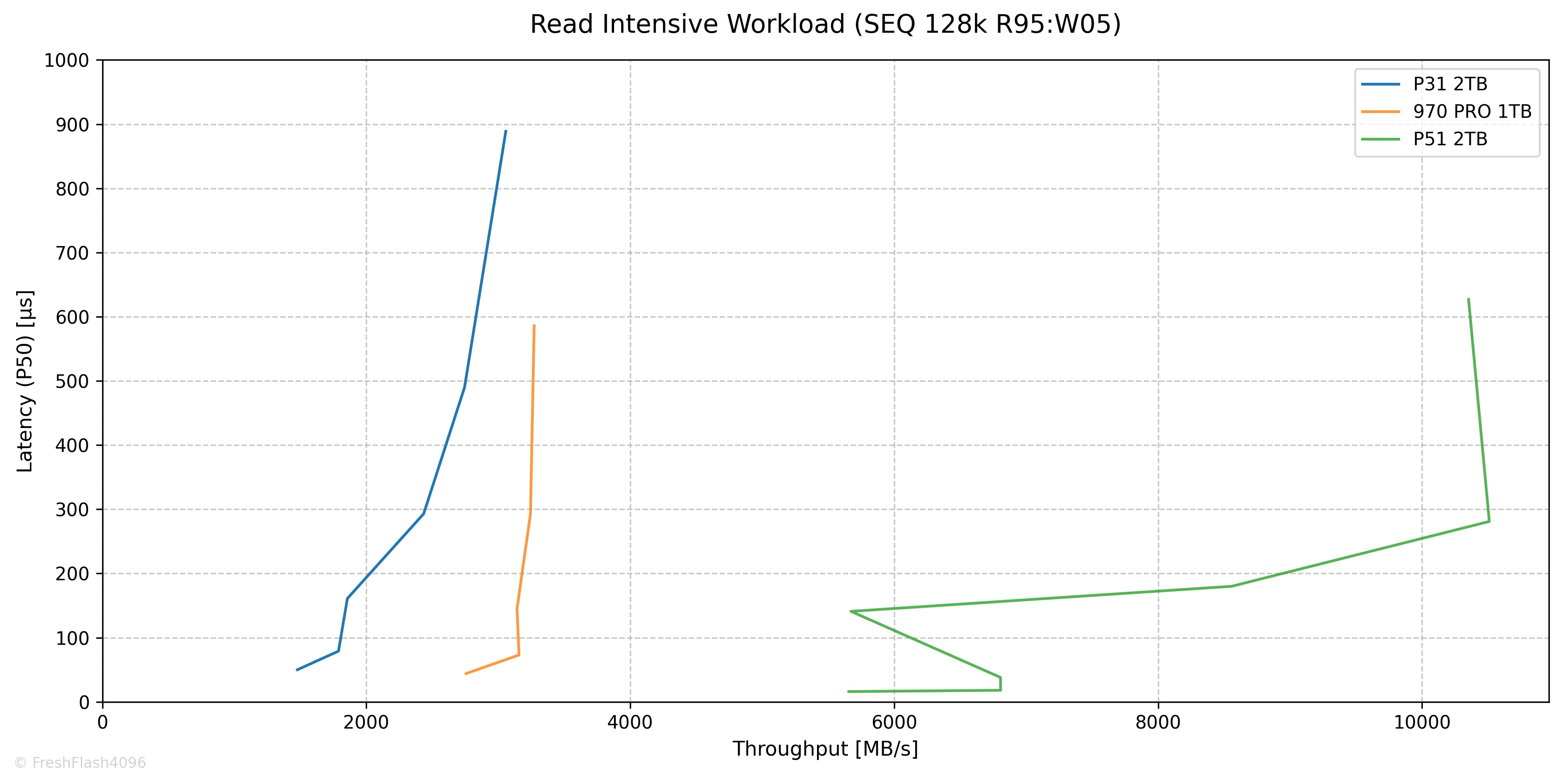
QD1의 1477MB/s@50µs로 시작해 QD32의 3057MB/s@889µs에서 포화되었습니다.
Mainstream Workload (RND 4k R70:W30)
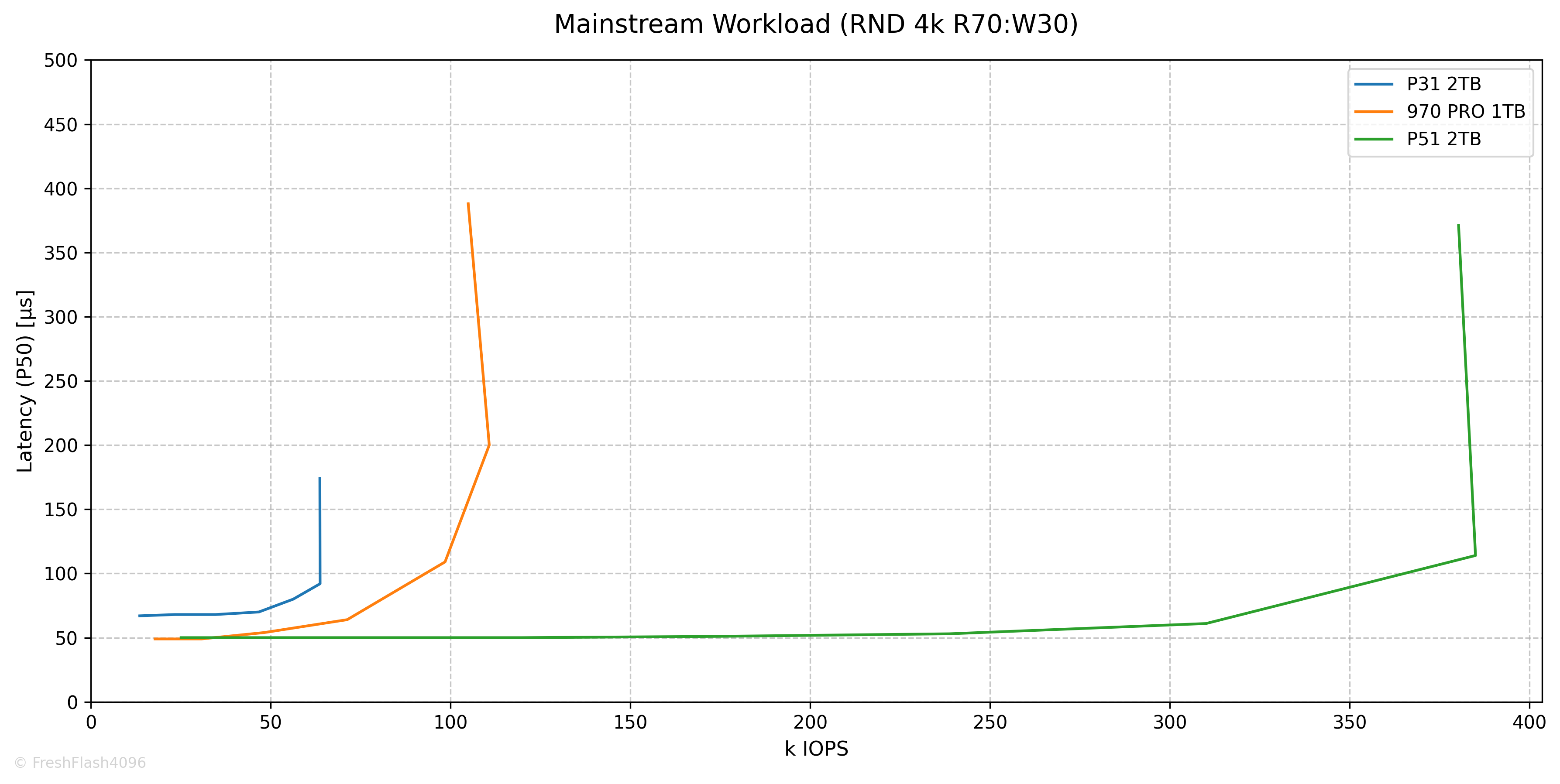
QD32에서 63.7k IOPS@92µs로 최대치가 측정되었으며, 이후에는 값이 증가하지 않았습니다. 비교군들에 비해 성능이 꽤 차이나는 모습입니다.
Write Intensive Workload (RND 4k R50:W50)
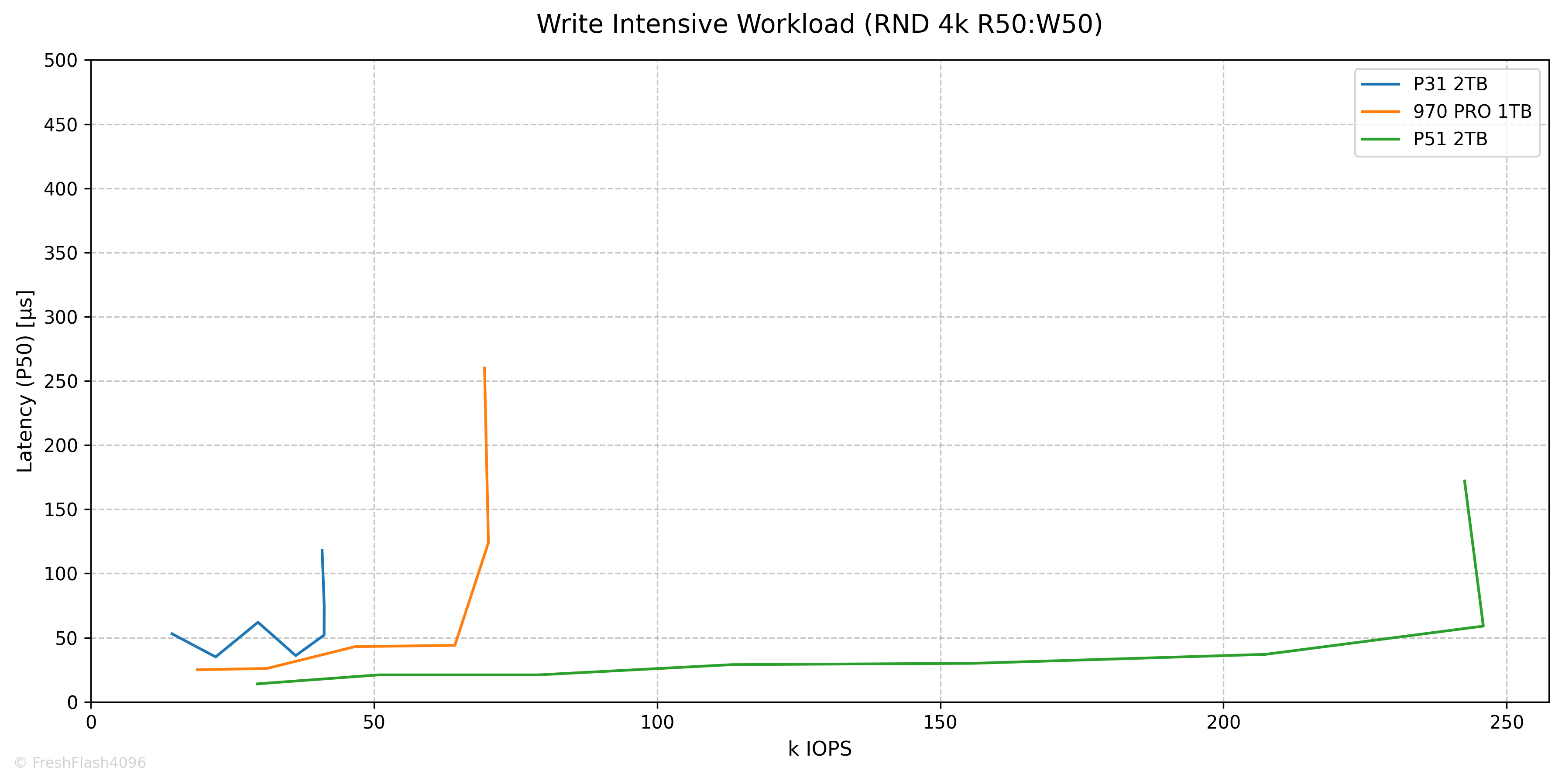
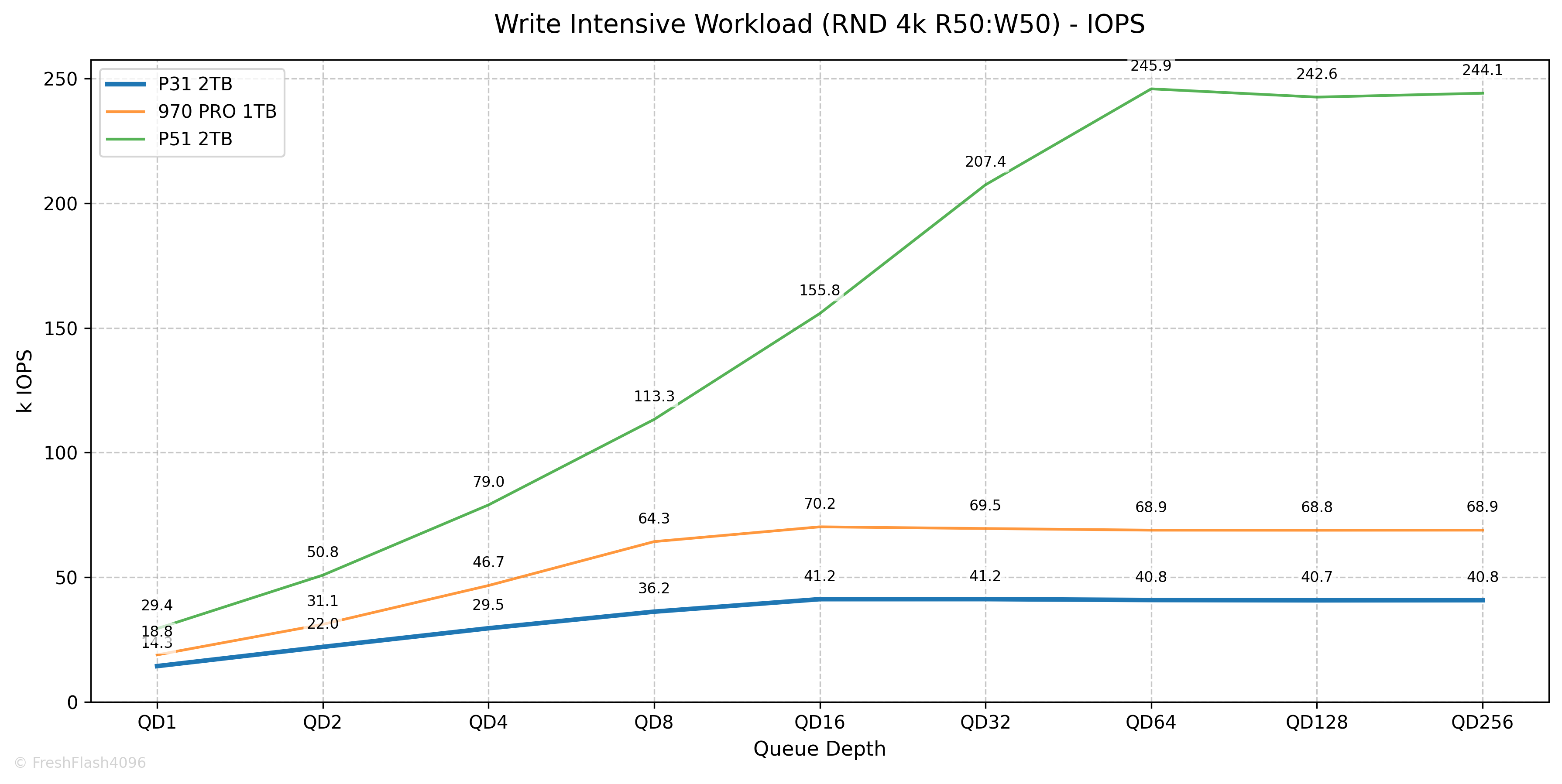
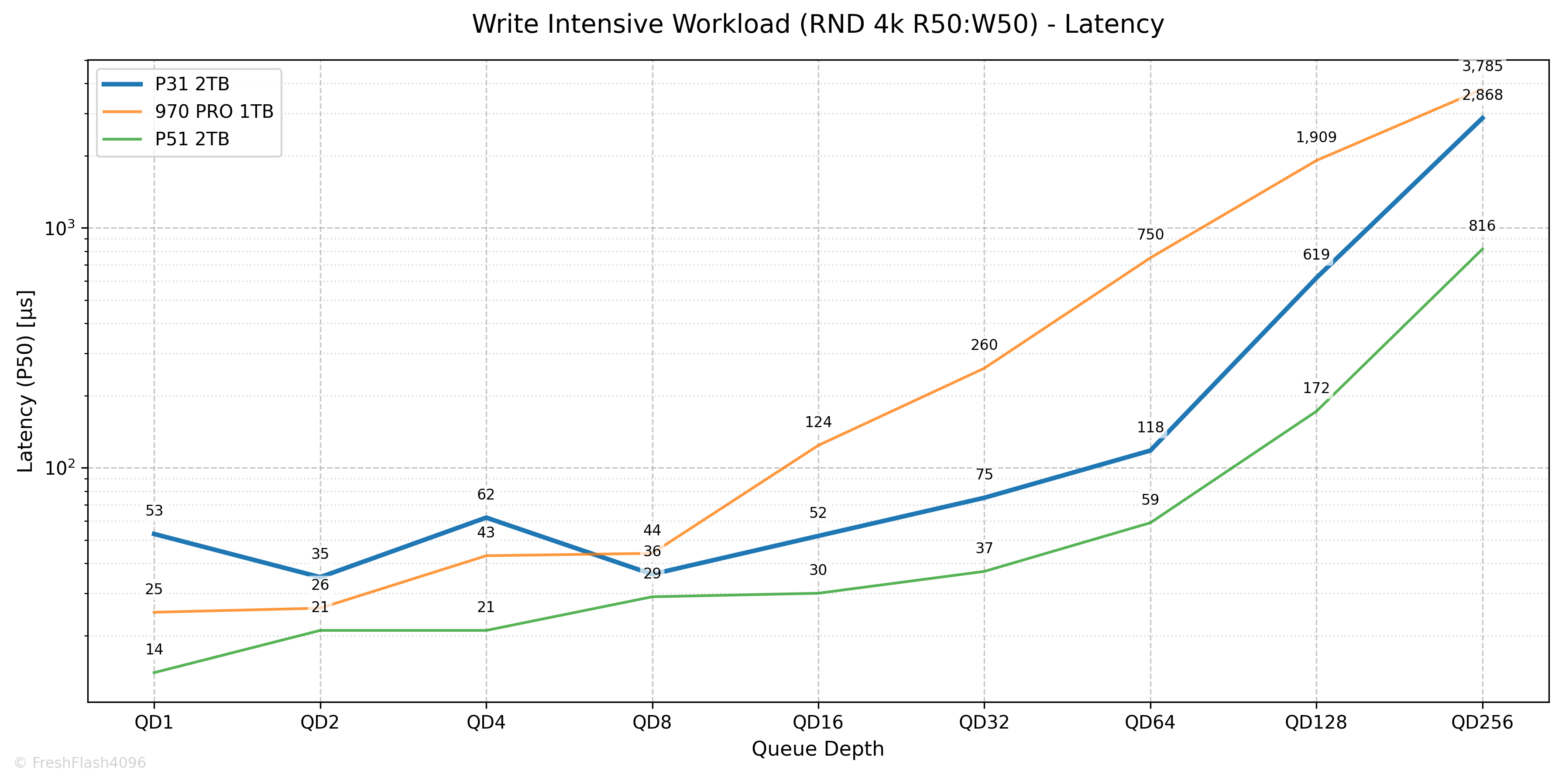
QD16에서 41.2k IOPS@52µs가 최대 성능으로 측정되었는데, 그래프가 삐뚤삐뚤한 모습을 보입니다. 아래는 QD에 따른 IOPS와 Latency를 그린 그래프입니다. 참고해주세요.
AI Workload (RND 512B Read)
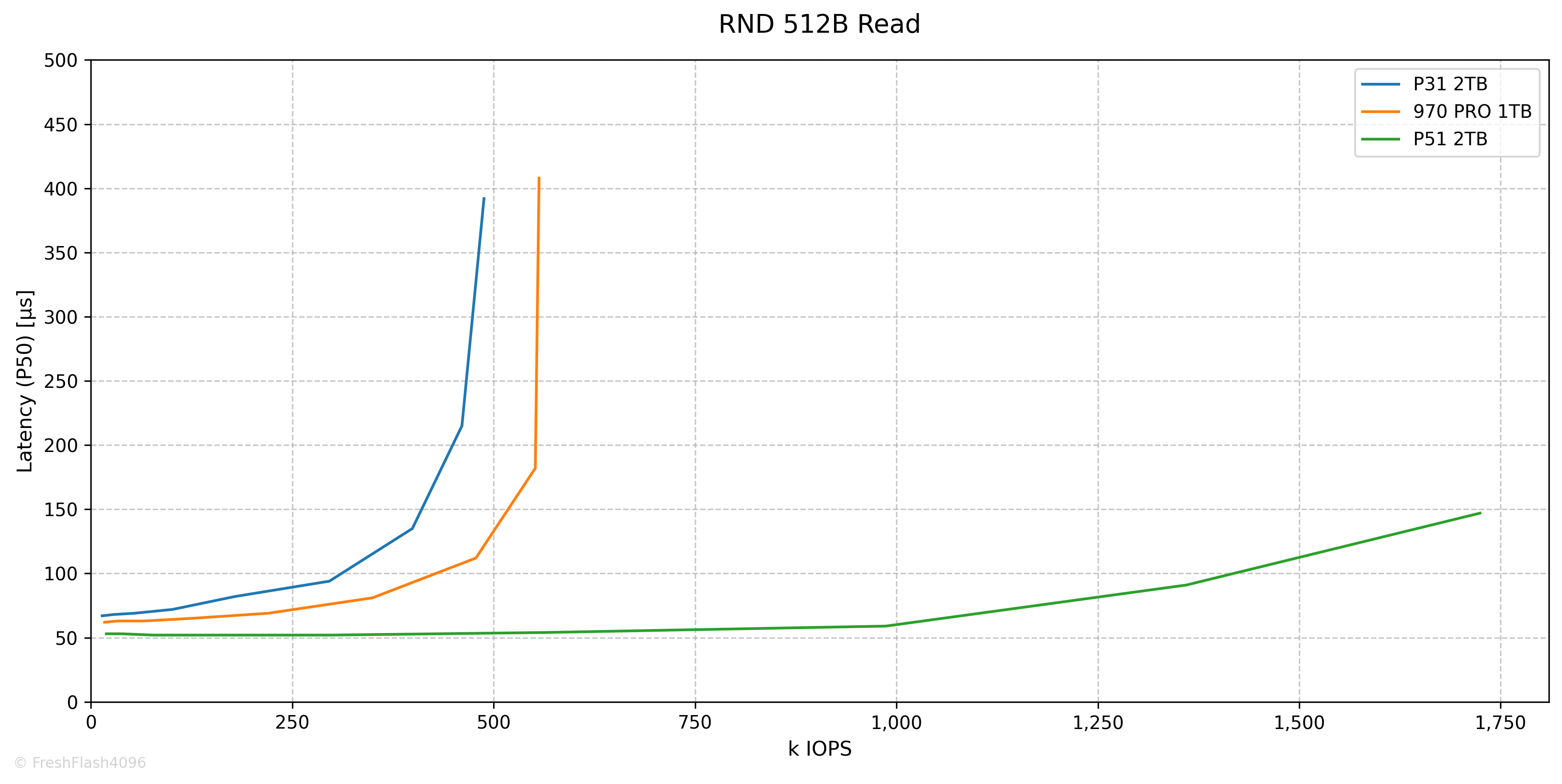
측정된 값은 QD256에서 488k IOPS@392µs로, RND 4k Read와 차이가 거의 없었습니다.
Random 4k QD1 Tail Latency
Latency에서 가장 느린 구간을 의미합니다. 그렇기 때문에 QoS(Quality of Service)에 큰 영향을 미치고, 실제로 eSSD의 데이터시트에서는 QoS를 명시하고 있습니다.
여기에선 100ms나 10ms 단위가 아닌, 모든 개별 I/O에 대한 지연시간을 카운트하여 그래프를 그립니다. 그렇기 때문에 데이터가 상당히 방대해, 이 항목은 RND 4k QD1에 대해서만 진행합니다.
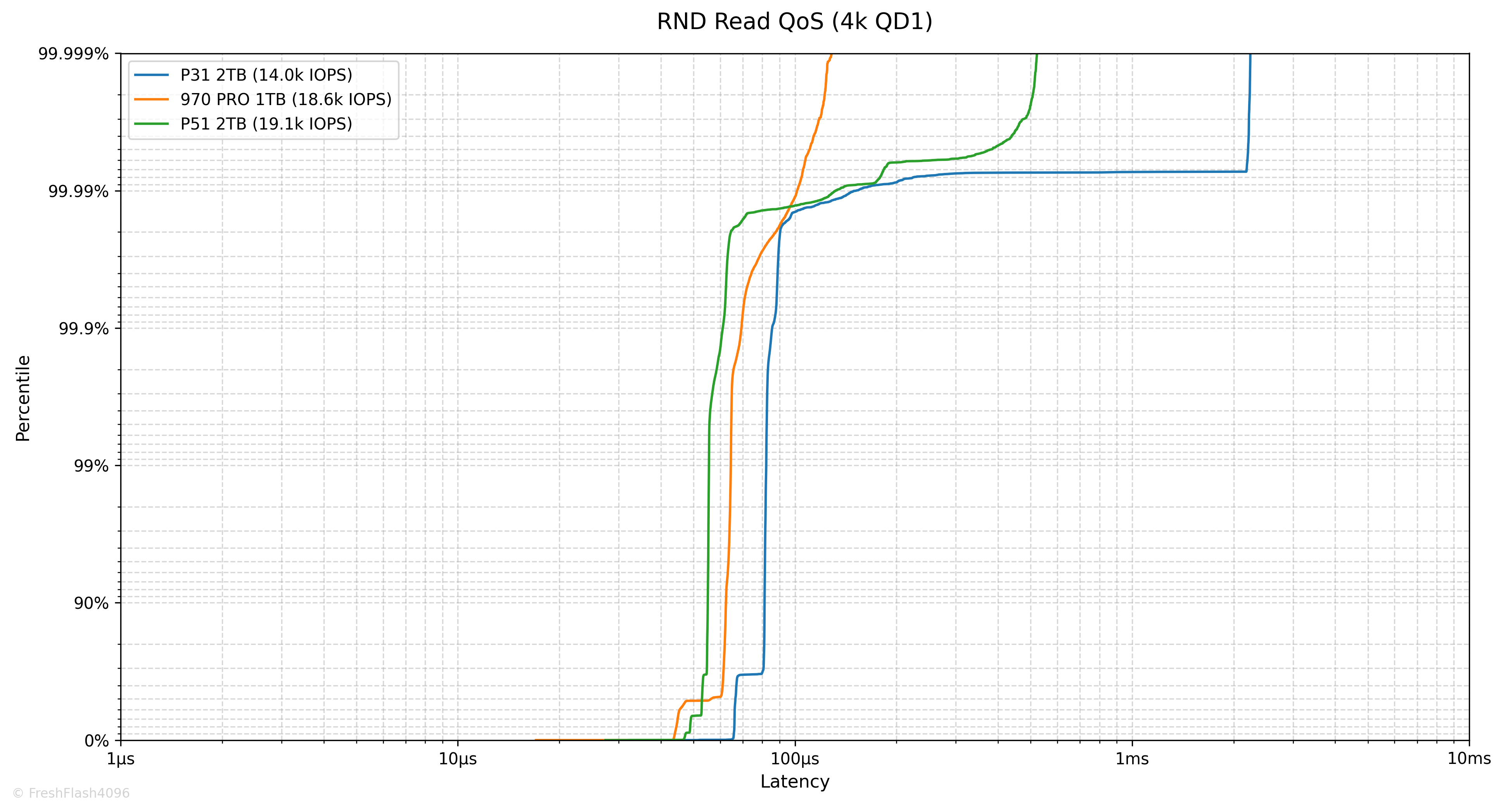
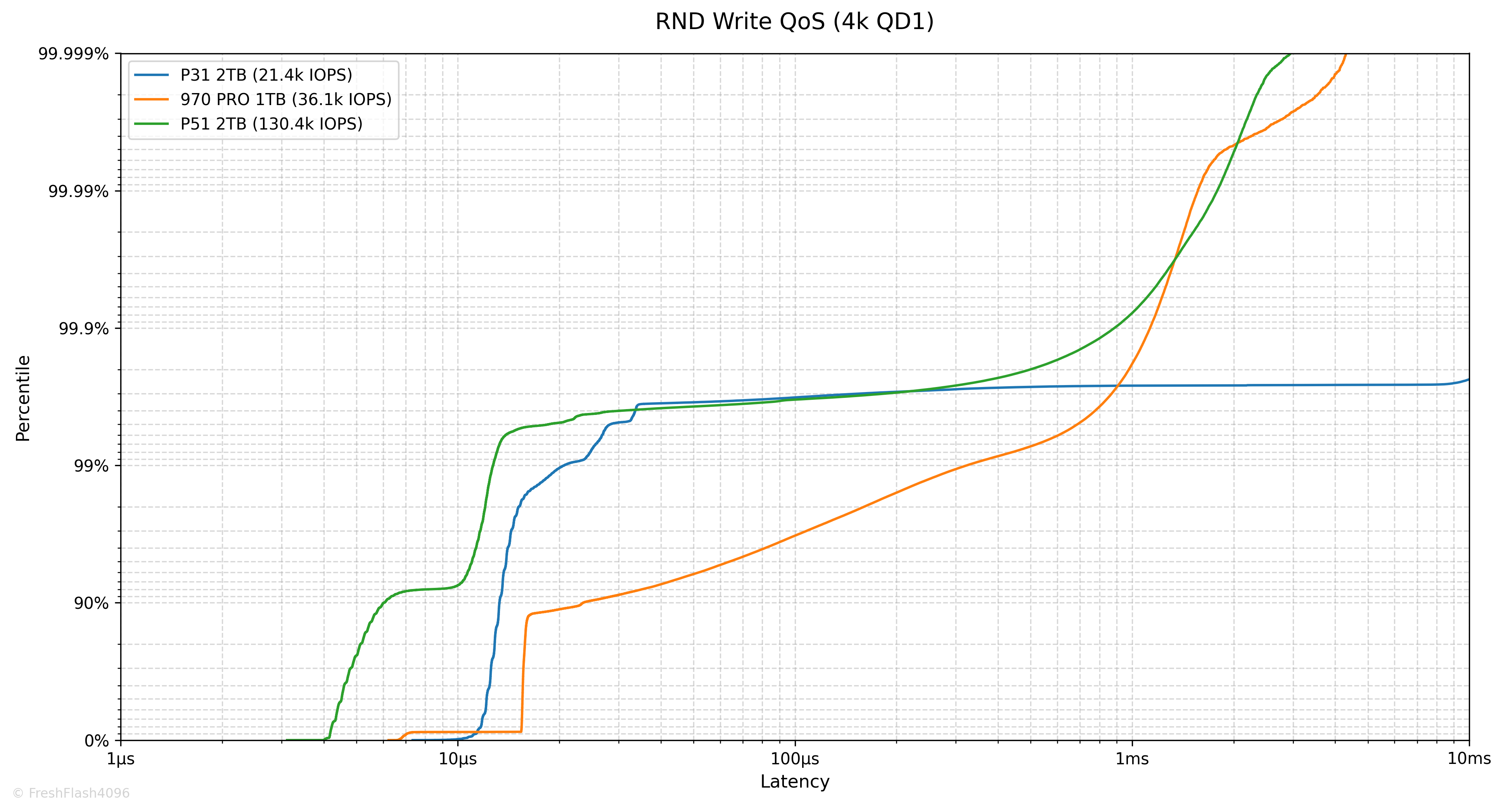
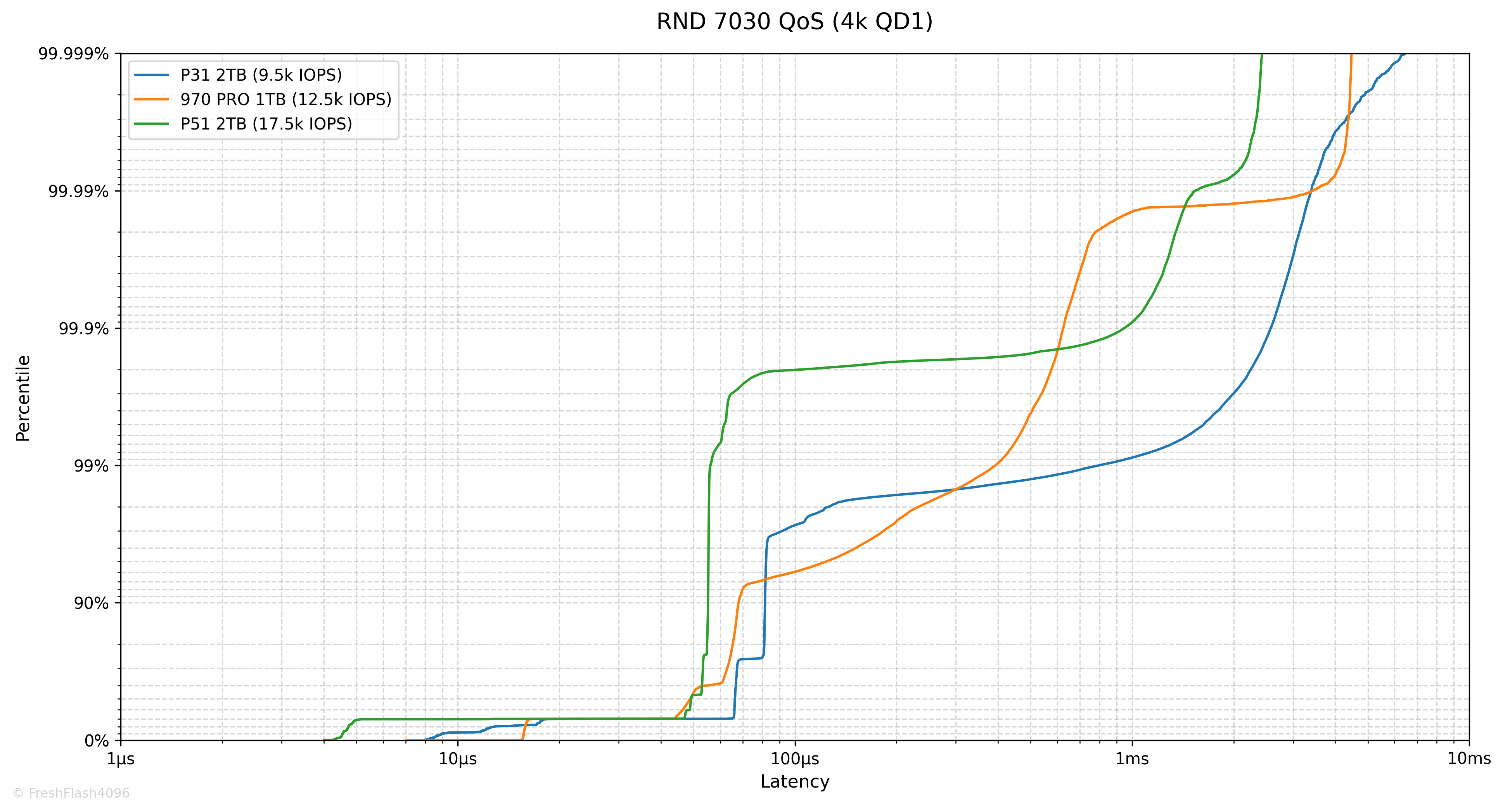
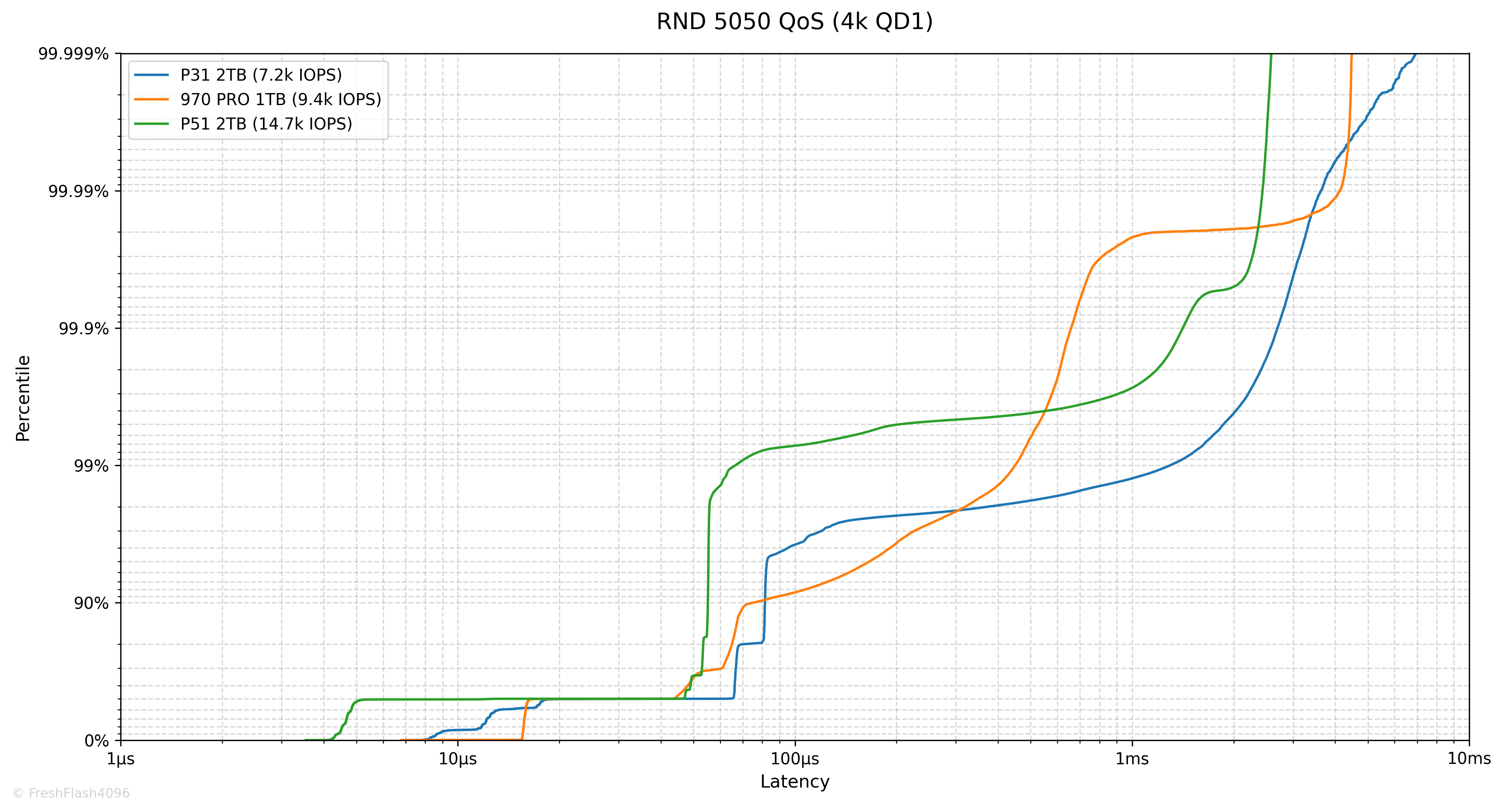
RND Write에서 지연시간이 늘어나 99.9% 이후의 수치가 그려지지 않은 것을 볼 수 있었습니다.
P31의 수치만 제시해드리자면, 99.9%에서 13.698ms, 99.99%에서 17.433ms, 99.999%에서는 21.103ms입니다. 꽤 늘어지는 모습이네요.
| RND Read | Datasheet | Benchmark Result |
| Typical Value [Burst] | 90 µs | 67 µs |
| Typical Value [Steady] | - µs | 67 µs |
| QoS (99.999%) [Steady] | - ms | 2.245 ms |
| RND Write | Datasheet | Benchmark Result |
| Typical Value [Burst] | 45 µs | 8 µs |
| Typical Value [Steady] | - µs | 13 µs |
| QoS (99.999%) [Steady] | - ms | 21.103 ms |
Steady State에서의 QoS는 깔끔하지 않았습니다. 다만, P31은 Steady State의 성능에 초점을 맞춘 eSSD가 아닌, Burst 성능을 바라보는 cSSD라는 점을 염두에 둡시다.
Polling 덕인지 Burst 상태의 지연시간은 데이터시트의 값보다 우수하게 측정되었습니다.
Closing
P31의 성능적인 측면에 대해 살펴보았습니다. 이제 리뷰를 13개 정도만 더 작성하면 좀 마음을 편하게 갖고 실험이나 리뷰를 할 수 있을 것 같은데, 일주일에 하나씩만 작성해도 한참 걸릴 것 같네요. 실기 시험을 준비하면 또 리뷰를 당분간 작성하지 못할테니 말이죠.
이번 리뷰는 여기까지 간단하게 보는 것으로 하겠습니다. 최근에 자극을 좀 받아서 Quarch Technology사의 장비를 들일까 또 고민이 되네요. 더 생각해보겠습니다.
다음 주는 리뷰를 쉬어가는 대신, 컴퓨텍스 후기로 찾아뵙겠습니다. 올해는 직접 방문하는데, 굉장히 기대됩니다.
지금은 NAS에 Mirror Pool로 설정되어 있습니다. 업글하고 싶네요.




Comments